







模块简介
本模块主要练习Hadoop集群部署。
模块知识
● 使用Linux基础命令
● Hadoop集群搭建部署知识
环境准备
三台CentOS7操作系统的虚拟机
可以是3个Docker容器,也可以是三个VMWare/VirtualBox的虚拟机。三台虚拟机的最低配置为1核1G + 20G。如果是虚拟机中的Docker容器环境,则无需按照以下方式配置主机名和IP。若是按照《[选修]基于OpenEuler的Docker容器安装使用教程》创建的Docker容器环境,或者从一道云科技发展有限公司提供的百度盘链接下载的VMWare镜像直接导入的Docker容器环境,直接移步到“步骤一”开始。
● 可使用以下镜像安装虚拟机操作系统,或者自行搜索下载OpenEuler操作系统:
https://mirrors.aliyun.com/centos/7.9.2009/isos/x86_64/CentOS-7-x86_64-Minimal-2207-02.iso
注意:若没有现成的虚拟机供你使用,VMWare或者VirtualBox请自行搜索下载并安装。
● 使用以下命令将三台虚拟机的主机名分别修改为master、slave1、slave2:
vi /etc/hostname
● 使用以下命令设置三台虚拟机的固定IP:
vi /etc/sysconfig/network-scripts/ifcfg-ens33
打开文件后的初始内容如下:
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=dhcp
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
UUID=4a053340-23a9-4998-9e3c-9cf47ceaf727
DEVICE=ens33
ONBOOT=no
将第4行中dhcp修改为none;将第15行中no修改为yes。然后文件末尾再追加以下内容:
IPADDR=192.168.157.200
PREFIX=24
GATEWAY=192.168.157.2
DNS1=8.8.8.8
IPV6_PRIVACY=no
其中IPADDR的值三台虚拟机各不一样,请确保:
master为192.168.157.200,
slave1为192.168.157.201,
slave2为192.168.157.202。
注意:如果你的VMWare/VirtualBox给虚拟机的网段不是192.168.157.X,请在VMWare/VirtualBox的“虚拟网络编辑器”中修改为以上网段。当然你也可以使用你的虚拟机默认的网段来配置三台虚拟机的固定IP,只是需要注意后续步骤中的IP都要和你配置的IP相匹配。
模块内容
步骤一:配置host主机文件
1. 在Windows工作机的XShell工具中,通过SSH连接到master虚拟机上:
ssh root@192.168.157.200
- 输入密码,连接成功后,打开host的配置文件:
vi /etc/hosts
- 在文件末尾追加输入以下内容(按键盘上i键开启输入):
192.168.157.200 master
192.168.157.201 slave1
192.168.157.202 slave2
输入完成后保存并退出(按键盘上Esc键,然后输入:wq)。
4. 通过SSH分别连接到slave1和slave2虚拟机上,分别执行以上2~3操作。
步骤二:配置SSH无密钥连接
1. 在master虚拟机的XShell连接对话中,输入以下命令生成master的密钥对:
ssh-keygen -t rsa
- 连按三次回车键。密钥对生成后,使用以下命令将密钥复制到slave1:
ssh-copy-id slave1
输入yes继续,输入slave1虚拟机的root用户的密码。
3. 再次使用以下命令将密钥复制到slave2:
ssh-copy-id slave2
输入yes继续,输入slave2虚拟机的root用户的密码。
4. 再次使用以下命令将密钥复制到master本身:
ssh-copy-id master
输入yes继续,输入master虚拟机的root用户的密码。
5. 通过SSH分别连接到slave1和slave2虚拟机上,分别执行以上1~4操作。
步骤三:检查SSH无密钥连接
1. 在master虚拟机的XShell连接对话中,输入以下命令:
ssh slave1
检查是否不需要输入密码即可连接到slave1虚拟机。连接成功后终端显示:
[root@slave1]#
- 若显示以上内容,即表示slave1的无密钥连接配置成功,使用以下命令注销slave1的登录:
logout
- 使用同样的方法检查slave2和master本身是否配置成功无密钥连接。
步骤四:在三台虚拟机上安装JDK
1. 在master虚拟机的XShell连接对话中,输入以下命令创建software文件夹:
mkdir -p /root/software/
- 在Windows工作机上打开PowerShell,使用SCP命令将Windows工作机上的JDK安装包复制到master虚拟机的/root/software/路径下。
scp E:\BigData\Component\jdk-8u401-linux-x64.tar.gz root@192.168.157.200:/root/software/
输入master虚拟机的密码后等待复制完成。
注意:jdk-8u401-linux-x64.tar.gz文件的路径修改为你工作机上的该文件的实际路径。
3. 在master虚拟机的XShell连接对话中,输入以下命令解压JDK安装包:
tar -zxvf /root/software/jdk-8u401-linux-x64.tar.gz -C /usr/local/
这将在/usr/local/目录下创建一个名为jdk1.8.0_401的文件夹,并将JDK解压在这里。
4. 配置环境变量。输入以下命令创建一个新的环境变量配置文件:
vi /etc/profile.d/jdk.sh
在文件中添加以下内容:
export JAVA_HOME=/usr/local/jdk1.8.0_401
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
保存并退出。
5. 运行以下命令使环境变量配置生效:
source /etc/profile
- 运行以下命令验证JDK是否安装正确:
java -version
应该看到安装的JDK版本信息。
现在,已经成功安装了JDK并配置了相关的环境变量。
7. SSH连接到slave1和slave2虚拟机上,分别执行以上1~6操作,这将会给slave1和slave2成功安装JDK。
注意:执行scp命令时将IP地址替换为slave1和slave2的地址,即192.168.157.201和192.168.157.202
步骤五:在三台虚拟机上安装Hadoop
1. 在Windows工作机上打开PowerShell,使用SCP命令将Windows工作机上的Hadoop包复制到master虚拟机的/root/software/路径下。
scp E:\BigData\Component\hadoop-3.3.6.tar.gz root@192.168.157.200:/root/software/
输入master虚拟机的密码后等待复制完成。
注意:hadoop-3.3.6.tar.gz文件的路径修改为你工作机上的该文件的实际路径。
2. 在master虚拟机的XShell连接对话中,输入以下命令解压hadoop-3.3.6.tar.gz包:
tar -zxvf /root/software/hadoop-3.3.6.tar.gz -C /root/software/
这会将包内容解压到/root/software/hadoop-3.3.6/文件夹中。
3. 在/root/software/hadoop-3.3.6/下创建相关文件夹,输入以下命令:
mkdir -p /root/software/hadoop-3.3.6/hadoopDatas/tempDatas
mkdir -p /root/software/hadoop-3.3.6/hadoopDatas/namenodeDatas
mkdir -p /root/software/hadoop-3.3.6/hadoopDatas/datanodeDatas
mkdir -p /root/software/hadoop-3.3.6/hadoopDatas/dfs/nn/edits
mkdir -p /root/software/hadoop-3.3.6/hadoopDatas/dfs/snn/name
mkdir -p /root/software/hadoop-3.3.6/hadoopDatas/dfs/nn/snn/edits
- 配置hadoop-env.sh设置JAVA_HOME环境变量及Hadoop用户:
vi /root/software/hadoop-3.3.6/etc/hadoop/hadoop-env.sh
文件末尾追加输入以下内容:
export JAVA_HOME=/usr/local/jdk1.8.0_401
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
- 配置core-site.xml:
vi /root/software/hadoop-3.3.6/etc/hadoop/core-site.xml
删除已有的<configuration>对,然后文件末尾追加输入以下内容:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
- 配置hdfs-site.xml:
vi /root/software/hadoop-3.3.6/etc/hadoop/hdfs-site.xml
删除已有的<configuration>对,然后文件末尾追加输入以下内容:
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/root/software/hadoop-3.3.6/hadoopDatas/namenodeDatas</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/root/software/hadoop-3.3.6/hadoopDatas/datanodeDatas</value>
</property>
</configuration>
- 配置mapred-site.xml:
vi /root/software/hadoop-3.3.6/etc/hadoop/mapred-site.xml
删除已有的<configuration>对,然后文件末尾追加输入以下内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
- 配置yarn-site.xml:
vi /root/software/hadoop-3.3.6/etc/hadoop/yarn-site.xml
删除已有的<configuration>对,然后文件末尾追加输入以下内容:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
- 配置workers:
vi /root/software/hadoop-3.3.6/etc/hadoop/workers
删除已有的内容,然后输入以下内容:
master
slave1
slave2
- 从master将Hadoop复制到slave1,执行以下命令:
scp -r /root/software/hadoop-3.3.6/ slave1:/root/software/
- 从master将Hadoop复制到slave2,执行以下命令:
scp -r /root/software/hadoop-3.3.6/ slave2:/root/software/
- 配置Hadoop环境变量,执行以下命令:
vi /etc/profile.d/hadoop.sh
输入以下内容:
export HADOOP_HOME=/root/software/hadoop-3.3.6
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存并退出。
使Hadoop环境变量生效,执行以下命令:
source /etc/profile
- 该配置Hadoop环境变量的操作在slave1和slave2上分别操作一次。
步骤六:格式化HDFS
在master节点执行以下命令:
hdfs namenode -format
步骤七:启动Hadoop集群
在master节点执行以下命令:
start-dfs.sh
应该看到如下输出:
[root@master ~]# start-dfs.sh
Starting namenodes on [master]
Last login: Wed Feb 21 19:51:38 EST 2024 from 192.168.157.1 on pts/0
Starting datanodes
Last login: Wed Feb 21 19:54:24 EST 2024 on pts/0
Starting secondary namenodes [master]
Last login: Wed Feb 21 19:54:27 EST 2024 on pts/0
[root@master ~]#
则代表hdfs启动成功,接着再次执行以下命令:
start-yarn.sh
应该看到如下输出:
[root@master ~]# start-yarn.sh
Starting resourcemanager
Last login: Wed Feb 21 19:54:35 EST 2024 on pts/0
Starting nodemanagers
Last login: Wed Feb 21 19:56:42 EST 2024 on pts/0
[root@master ~]#
则代表yarn启动成功,接着再次执行以下命令:
mapred --daemon start historyserver
应该看到如下输出:
[root@master ~]# mapred --daemon start historyserver
[root@master ~]#
步骤八:验证
分别在master、slave1、slave2三个节点执行以下命令:
jps
应该分别看到如下输出:
master:
[root@master ~]# jps
1606 DataNode
2230 NodeManager
2087 ResourceManager
1816 SecondaryNameNode
2681 Jps
2620 JobHistoryServer
1471 NameNode
[root@master ~]#
slave1:
[root@slave1 ~]# jps
1562 Jps
1355 DataNode
1452 NodeManager
[root@slave1 ~]#
slave2:
[root@slave2 ~]# jps
1363 DataNode
1571 Jps
1460 NodeManager
[root@slave2 ~]#
步骤九:关闭master虚拟机防火墙
在master节点执行以下命令:
sudo systemctl stop firewalld
sudo systemctl disable firewalld
上述命令将停止并禁用firewalld服务,这是 CentOS 7 和更新版本中的默认防火墙服务。禁用防火墙以便在工作机上通过Web浏览器访问Hadoop。
注意:在正式生产环境中不建议禁用防火墙,需要配置防火墙开放某些端口。可使用以下命令查看服务正在监听的端口。
ss -nltp
或者
netstat -tuln
步骤十:通过Web浏览器访问Hadoop
在工作机上打开浏览器,输入以下网址访问Hadoop:
http://192.168.157.200:9870/
应该看到以下画面:
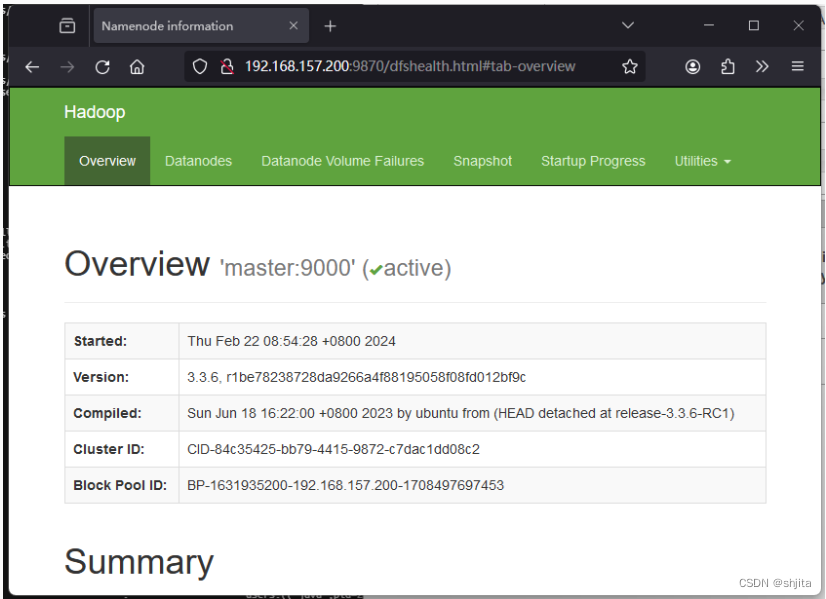
输入以下网址查看集群:
http://192.168.157.200:8088/
应该看到以下画面:
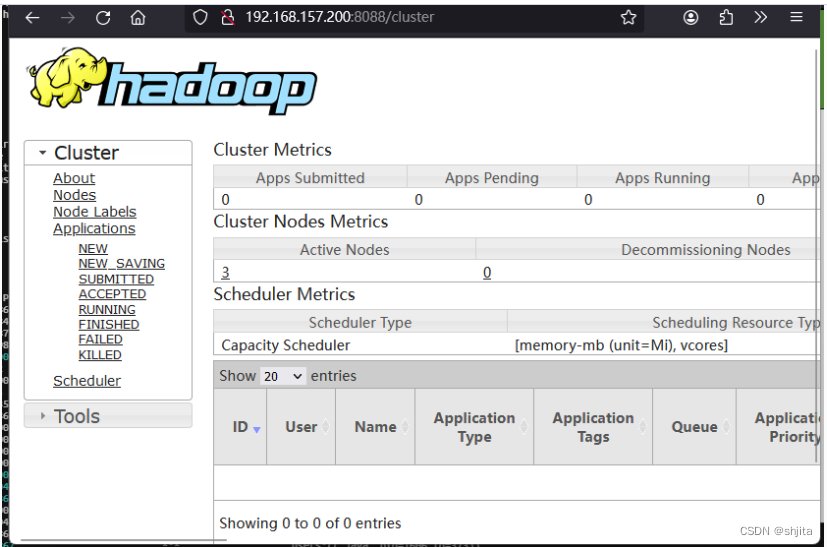
步骤十一:重启服务
在每次重新启动电脑后,需要重新启动Hadoop的服务,执行以下命令:
start-dfs.sh
start-yarn.sh
mapred --daemon start historyserver














 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









