






考虑到群体是全校,总体来看这次题目简单题部分还是偏简单了。简单题目大部分都是思维题,只有man!考到了简单的bfs。
难度分布
总共12道题目,以下是题目的难度分布:
very-easy 签到:A.河北师大最靓的仔、L.老丁的幸运手机号。
easy : J.叮当的奇妙大数、H.man!
mid: F.洞穴逃生、K.学长的圣遗物。
mid-hard: B.选择排序、G.省电、D.一道简单的数学题easy-version。
hard:C.唐山皇帝。
防ak:E.一道简单的数学题hard-version、I.小孙无法思考。
一血名单
下面是一血名单:
A.河北师大最靓的仔 (徐锦杰)
B.选择排序(李建川)
C.唐山皇帝 (无)
D.一个简单的数学题esay version (孙浩滨)
E.一个简单的数学题hard version (金鳞玲)
F.洞穴脱险 (孙传炜)
G.省电 (孙传炜)
H.man! (孙传炜)
I.小孙无法思考 (无)
J.叮当的奇妙大数 (宗意)
K.学长的圣遗物 (李延栋)
L.老丁的幸运手机号 (李金聪)
接下来题解按照难度递增给出。
very-easy部分(签到)
河北师大最靓的仔
题面

思路
经典的思维诈骗输出题。其实只要输出“XXX”即可,如果没有输出”XXX“那么我们后台会看到你们会输出了谁的名字,v我50不泄密。
代码
#include<bits/stdc++.h>
using namespace std;
int main()
{
cout << "XXX" << endl;
return 0;
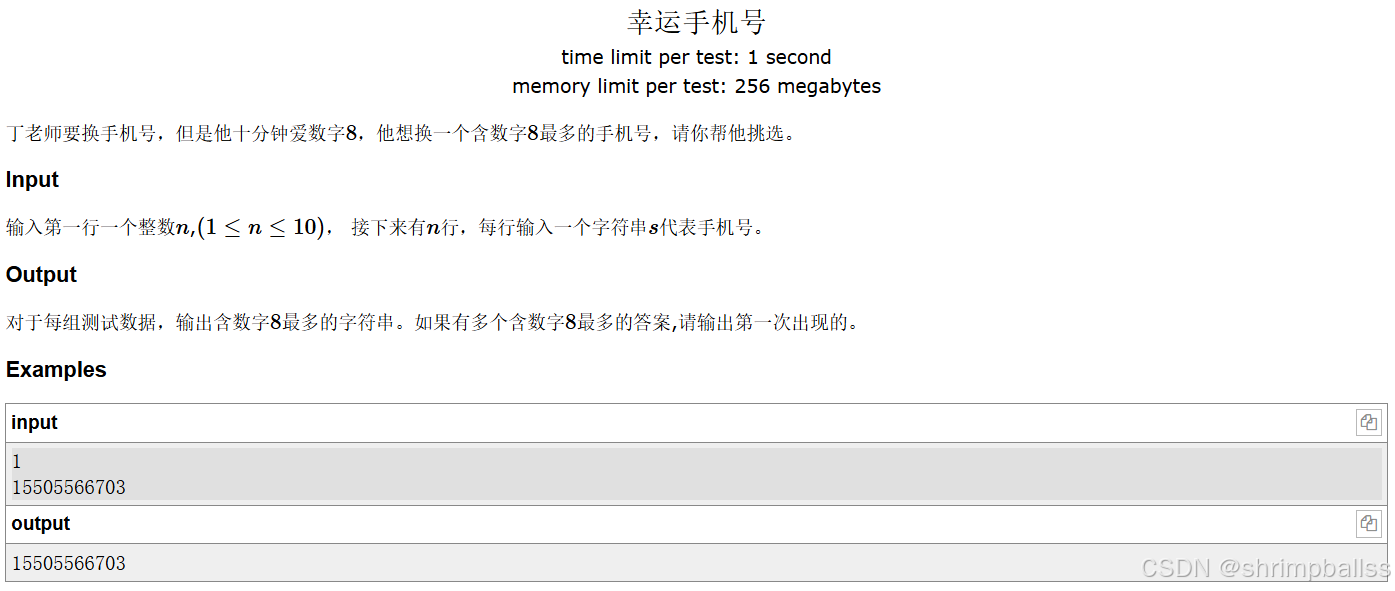
}老丁的幸运手机号
题面
思路
简单题,只需要更出现8更多的字符串,没有出现更多的我就不更新,这样就满足题意,看代码。
代码
#include<bits/stdc++.h>
using namespace std;
int main()
{
int n;
cin >> n;
int maxn = -1;
string res;
for(int i = 1; i <= n; i ++)
{
int cnt = 0;
string s;
cin >> s;
for(auto t: s)
{
if(t == '8') cnt ++;
}
if(cnt > maxn)
{
maxn = cnt;
res = s;
}
}
cout << res << endl;
}easy部分
叮当的奇妙大数
题面

思路
依旧是诈骗题。其实我们发现即使是9999拆开也只能是99 * 99诸如此类的乘法,始终不可能大于原来的数字。所以我们只需要输出原来数字各个位相加的结果就好了。
代码
#include<bits/stdc++.h>
using namespace std;
int main()
{
int n;
cin >> n;
string s;
cin >> s;
int res = 0;
for(int i = 0; i < n; i ++)
{
res += s[i] - '0';
}
cout << res << endl;
return 0;
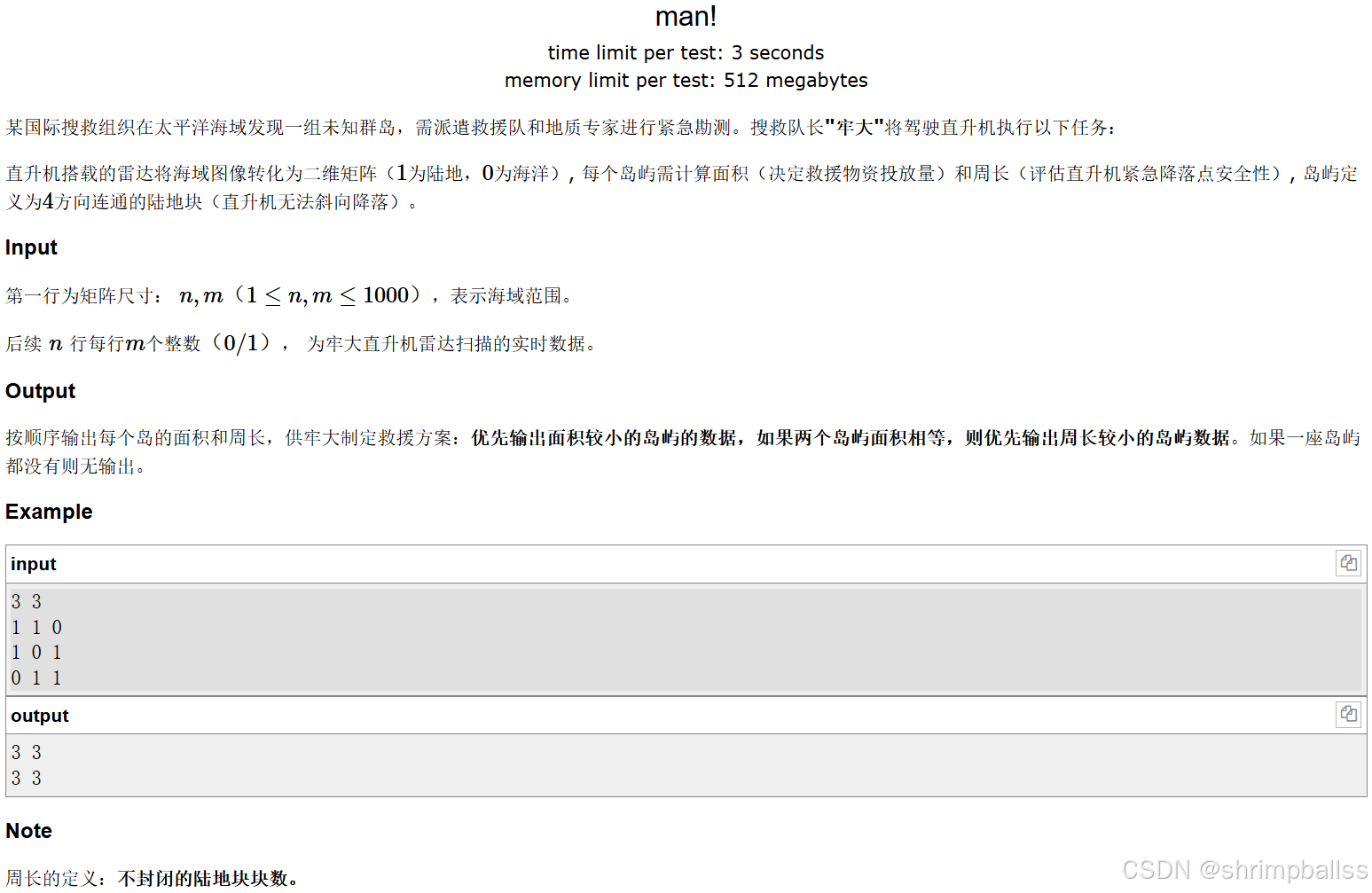
}man!
题面
思路
很基础的bfs,也是从这里开始上算法。我们暴力扫一遍各个位置,并且用一个st二维数组标记以及被计算过的位置,然后对所有没有被计算过的1位置跑bfs把所有与之联通的1放在一个集合里当作一个连通块就能知道面积。最后再通过计算各个连通块里有多少与0相邻的1或者在边界的1就能计算出周长。然后最后以pair的形式存在数组里排个序输出就行。
代码
#include<bits/stdc++.h>
using namespace std;
int dx[4] = {1,0,-1,0};
int dy[4] = {0,-1,0,1};
int main()
{
int n,m;
cin >> n >> m;
vector <vector <char>> g(n+1,vector<char>(m+1));
vector <vector <bool>> st(n+1,vector <bool>(m+1,false));
for(int i = 1; i <= n; i ++)
for(int j = 1; j <= m; j ++)
cin >> g[i][j];
vector <pair<int,int>> res;
vector <vector <pair<int,int>>> num;
for(int i = 1; i <= n; i ++)
{
for(int j = 1; j <= m; j ++)
{
if(st[i][j] || g[i][j] == '0') continue;
else
{
vector <pair<int,int>> tmp;
queue <pair<int,int>> p;
p.push({i,j});
int sum = 0;
while(p.size())
{
auto t= p.front();p.pop();
if(st[t.first][t.second]) continue;
else st[t.first][t.second] = true;
tmp.push_back({t.first,t.second});
for(int k = 0; k < 4; k ++)
{
int x = dx[k] + t.first;
int y = dy[k] + t.second;
if(x >= 1 && x <= n && y >= 1 && y <= m && g[x][y] == '1' && st[x][y] == 0)
{
p.push({x,y});
}
}
}
num.push_back(tmp);
}
}
}
for(vector <pair<int,int>> t: num)
{
int sa = 0;
int sb = t.size();
for(auto tt: t)
{
for(int i = 0; i < 4; i ++)
{
int x = tt.first + dx[i];
int y = tt.second + dy[i];
if(x < 1 || x > n || y < 1 || y > m || g[x][y] == '0'){sa ++;break;}
}
}
res.push_back({sb,sa});
}
sort(res.begin(),res.end());
for(auto [x,y] : res) cout << x << " " << y << endl;
return 0;
}mid部分
洞穴逃生
题面

思路
这道题的数组就是为了求
数组的, 所以按照题意把
数组求出来之后就可以把
数组扔掉.
随后我们考虑题意,首先我们要求最大值所以多走一格就是赚到,所以最优解一定是把所有格子全部走完,并且一个格子只有第一次走到才会产生贡献,所以每个格子只会从它旁边最优的格子走过来,其他不是最优的格子就不会对这个格子产生影响,把这种影响抽象成边的话,我们不难发现,这种影响组成了一棵树.此时易得这是一个图论问题.
既然是图论问题,我们就需要考虑如何建图,每个格子都有可能和他相邻的格子产生贡献,所以我们对两个相邻的格子(假设对格子和格子
)建一条边,边的值就是
, 这样我们就把图建好了.
其次考虑用什么图论算法, 我们每一个格子都需要贪心的选择最优的解法也就是最大的边,这种思想与最小生成树相似,但是求得是最大值,那么我们直接对反图求最小生成树即可求解.( 这里的反图就是所有边取相反数, 也就是
代码
#include<bits/stdc++.h>
using namespace std;
#define int long long
int p[250010],x[250010];
pair<int,pair<int,int>>k[250010];
int find(int x){
if(p[x]!=x)p[x]=find(p[x]);
return p[x];
}
signed main(){
int t;
cin>>t;
while(t--){
int n,m,sr,sc,tr,tc;
cin>>n>>m>>sr>>sc>>tr>>tc;
int x1,x2,a,b,c,pp;
cin>>x1>>x2>>a>>b>>c>>pp;
x[1]=x1,x[2]=x2;
int cnt=0,ans=0;
for(int i=1;i<=n*m;i++)p[i]=i;
for(int i=3;i<=n*m;i++)x[i]=(a*x[i-1]+b*x[i-2]+c)%pp;
for(int i=1;i<=n*m;i++){
if(i%m)k[cnt++]={-x[i]*x[i+1],{i,i+1}};
if(i<=(n-1)*m)k[cnt++]={-x[i]*x[i+m],{i,i+m}};
}
sort(k,k+cnt);
for(int i=0;i<cnt;i++){
int u=k[i].second.first,v=k[i].second.second;
int uu=find(u),vv=find(v);
if(uu!=vv){
p[uu]=vv;
ans+=k[i].first;
}
}
cout<<-ans<<endl;
}
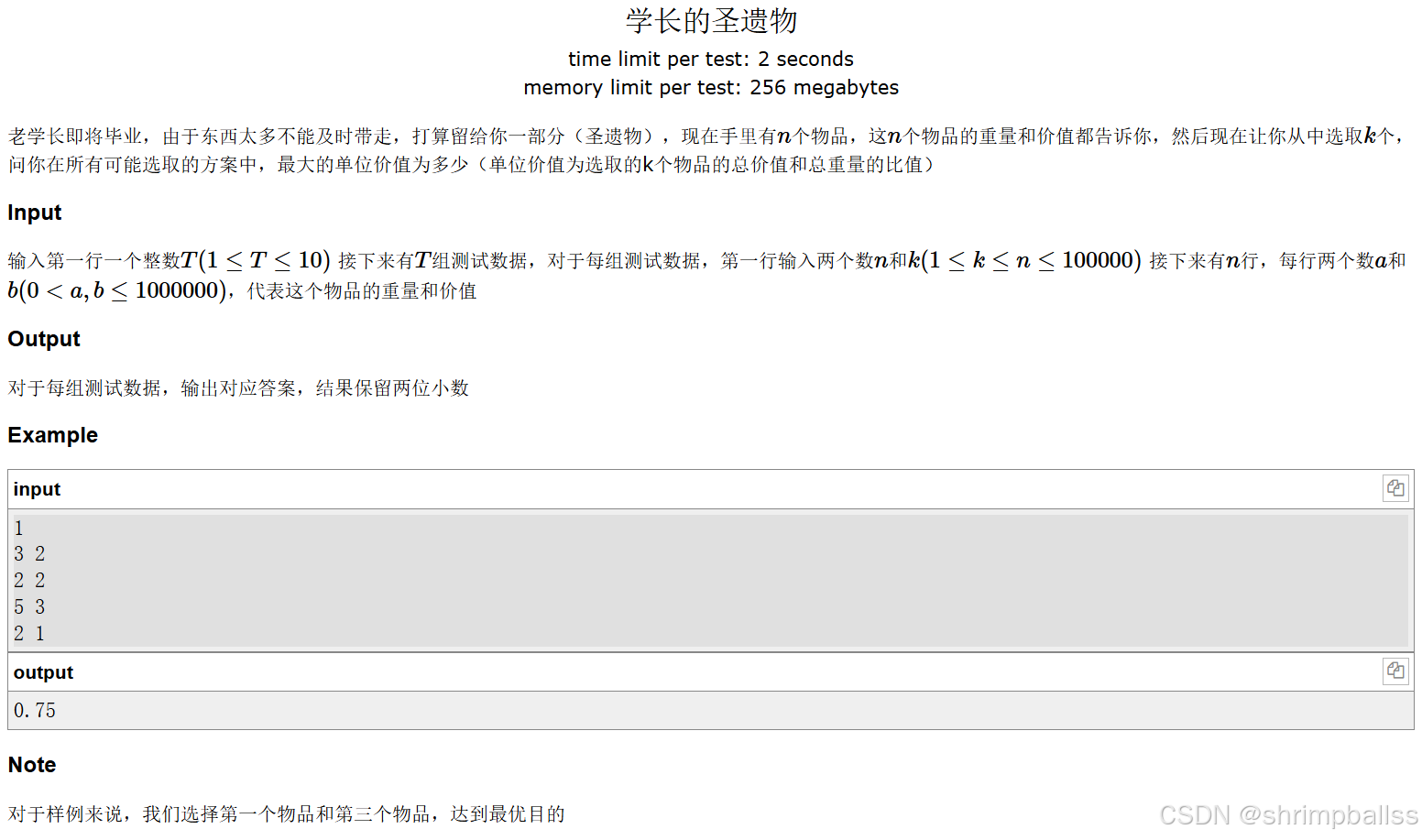
}学长的圣遗物
题面
思路
这题考虑二分答案,既选k个物品总价值与总重量的比值
价值 等式两边同时乘
可以得到
。
我们要所选的个总单位价值最大,即要选的数量中
最大,所以二分的check函数对
按降序排列,算出前k个之和是否大于0,大于0就说明当前单位价值可以到达,反之不能。
代码
#include<bits/stdc++.h>
using namespace std;
#define IOS ios::sync_with_stdio(false); cin.tie(0); cout.tie(0);
const int INF = 0x3f3f3f3f;
const int MAX = 1e5 + 7;
int n, k;
int a[MAX], b[MAX];
double w[MAX];
bool judge(double mid);
int main() {
IOS;
int T; cin >> T;
while (T--) {
cin >> n >> k;
for (int i = 1; i <= n; i++) cin >> a[i] >> b[i];
double l = 0, r = INF;
for (int i = 1; i <= 100; i++){
double mid = (l + r) / 2;
if (judge(mid)) l = mid;
else r = mid;
}
cout << fixed << setprecision(2) << l << endl;
}
return 0;
}
bool judge(double x) {
for (int i = 1; i <= n; i++)
w[i] = b[i] - a[i] * x;
sort(w + 1, w + 1 + n, greater<double>());
double sm = 0;
for (int i = 1; i <= k; i++)
sm += w[i];
return sm > 0;
}mid hard部分
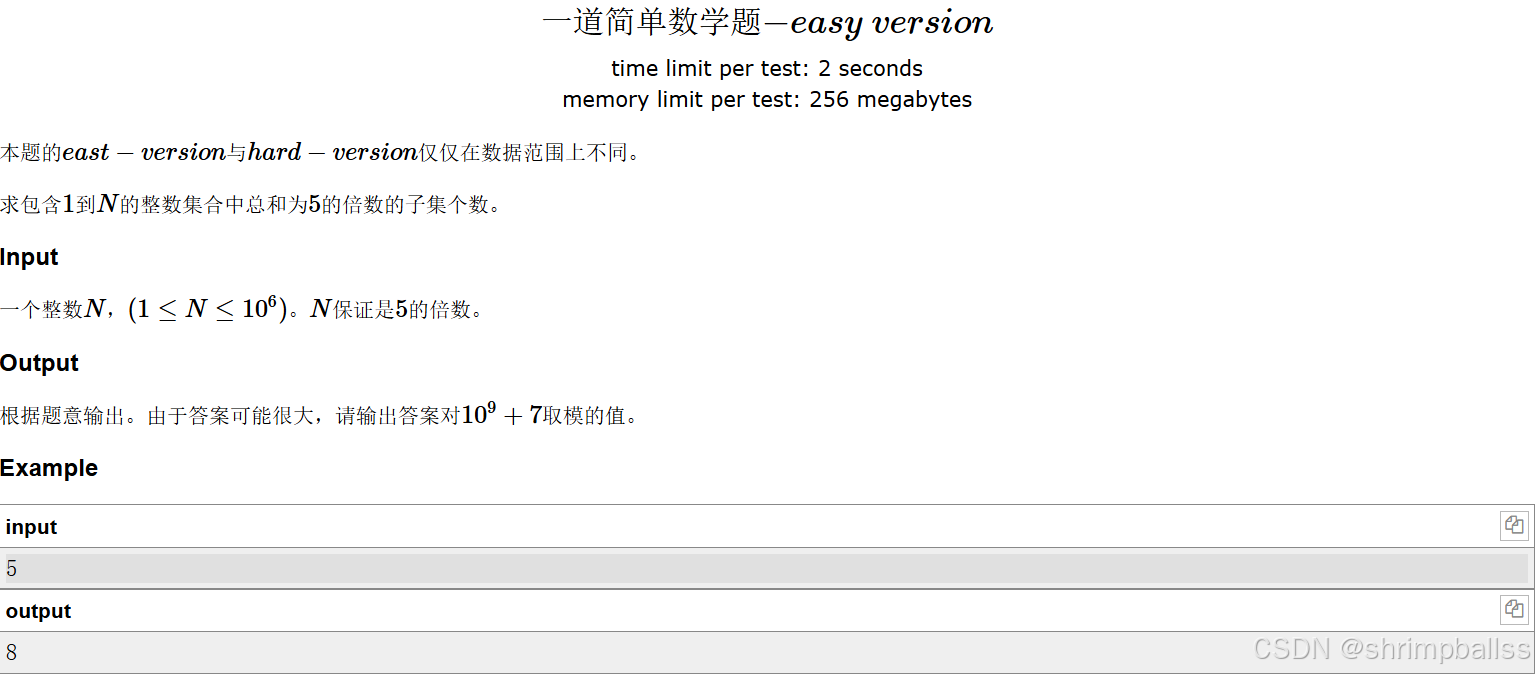
一个简单数学题(easy version)
题面
思路
用一个大小为 5 的数组 dp 来维护当前可达到的“和模 5”的子集个数,dp[r] 表示子集和 ≡ r (mod 5) 的子集数。
初始时只有空集,其和为 0,因此 dp[0] = 1,其余为 0。
依次枚举每个数 i∈[1..N],对 dp 进行更新。对每个余数 r,既可以“不选 i”,也可以“选 i”。“选 i”会将原来和为 r 的那些子集的和变成 (r + i) mod 5。
easy version的本题n的数据量只有1e6级别,可以用dp解决。
代码
#include <bits/stdc++.h>
using namespace std;
#define int long long
const int MOD = 1000000007;
signed main(){
ios::sync_with_stdio(false);
cin.tie(nullptr);
int N;
cin >> N;
vector<int> dp(5, 0LL);
dp[0] = 1;
for(int i = 1; i <= N; i++){
int x = i % 5;
int new_dp[5];
for(int r = 0; r < 5; r ++){
int sf = dp[r];
int fs = dp[(r + 5 - x) % 5];
new_dp[r] = (sf + fs) % MOD;
}
for(int r = 0; r < 5; r++){
dp[r] = new_dp[r];
}
}
cout << dp[0] % MOD << endl;
return 0;
}
选择排序
题面

思路
• 设第一个(或第二个)操作应用的范围为 [1, x](或 [y, n])。
• 猜测 y。
• 如果 [1, x] 和 [y, n] 不相交,找到离 y 最远的 x,使得范围 [x, y] 内的元素处于正确的位置。
• 否则,如果 [1, x] 和 [y, n] 相交,找到最小的 x,使得如果你对前 x 个元素进行排序,那么前 y - 1 个元素会处于正确的位置。
• 上述方法可以在 O(n) 时间内实现。一个 O(n log n) 时间复杂度的算法也可以在时间限制内通过所有测试用例。
代码
#define IOS ios::sync_with_stdio(false);cin.tie(0); cout.tie(0)
#define PII pair<int,int>
#include<bits/stdc++.h>
using namespace std;
#define int long long
int n,m;
void solve(){
cin >> n;
vector <int> a(n + 1);
for(int i=1;i<=n;i++)
{
cin >>a[i];
}
int maxn = 0;
vector <int> b=a;
sort(b.begin() + 1,b.end());
vector <int> p(n + 1);
map <int,int> st;
for(int i=1;i<=n;i++)
{
int k = lower_bound(b.begin()+1,b.end(),a[i])-b.begin();
if(st[k])
{
p[i] = ++st[k];
}
else st[k] = k,p[i]=k;
}
vector <int> tmp;
int res=n * n;
int minn =1e18;
for(int i=n;i>=1;i--)
{
if(p[i] < minn && p[i] < (i)) {minn = p[i];tmp.push_back(p[i]);}
}
for(int i=1;i<=n;i++)
{
int sk;
if(tmp.size())
sk = tmp.back();
else sk = n + 1;
sk = n - sk + 1;
sk = min(sk,n - i + 1);
int k = maxn * maxn + sk * sk;
res = min(res,k);
if(p[i] > i && p[i] > maxn)
{
maxn = max(maxn,p[i]);
}
if(tmp.size() == 0) continue;
if(p[i] == tmp.back()) tmp.pop_back();
}
minn = n + 1;
tmp.clear();
maxn = 0;
for(int i=1;i<=n;i++)
{
if(p[i] > i && p[i] > maxn)
{
maxn=p[i];
tmp.push_back(p[i]);
}
}
for(int i=n;i>=1;i--)
{
int sk;
if(tmp.size())
{
sk = tmp.back();
}
else {
sk = 0;
}
sk = min(sk,i);
res = min(res,(n - minn + 1) * (n - minn + 1) + sk * sk);
if(p[i] < i && p[i] < minn)
{
minn = p[i];
}
if(tmp.size() == 0) continue;
if(p[i] == tmp.back()) tmp.pop_back();
}
cout << res << endl;
}
signed main()
{
IOS;
solve();
}省电
题面
思路
思路:区间dp
设 表示
区间人在左端点里最小的耗电值。
表示
区间人在右端点的最小值。
设起点为, 因为
所以这样设置dp不会有重叠的情况。
然后推方程:先用前缀和记录前i个电灯的每秒耗电量,同时可以注意到人在左端点的时候,可以是上一个左端点向左边走一步,也可以是右边的右端点走到了这个区间的左端点。那么方程就是:
其中 表示区间
的每秒耗电量。
同理
方程推出来了那我们就直接枚举起点左边的l和起点右边的r就好啦,最后选区间为 左端点或者右端点最小的输出
代码
#include <string.h>
#define int long long
using namespace std;
int a[1010];
int dp[1010][1010];
int b[1010];
int sum[1010];
signed main()
{
int n;
int t;cin>>t;
while(t--){
cin>>n;
for(int i = 0; i <= n; i ++) for(int j = 0; j <= n; j++) dp[i][j] = 1e18;
int st;
cin>>st;
for(int i=1;i<=n;i++){
cin>>a[i]>>b[i];
sum[i]=sum[i-1]+b[i];
}
dp[st][st]=0;
for(int l=st;l>=1;l--){
for(int r=st;r<=n;r++){
int tot=sum[n]-sum[r]+sum[l];
dp[l][r]=min(dp[l][r],min(dp[l+1][r]+(a[l+1]-a[l])*tot,dp[r][l+1]+(a[r]-a[l])*tot));
dp[r][l]=min(dp[r][l],min(dp[r-1][l]+(a[r]-a[r-1])*(sum[n]-sum[r-1]+sum[l-1]),dp[l][r-1]+(a[r]-a[l])*(sum[n]-sum[r-1]+sum[l-1])));
}
}
cout<<min(dp[1][n],dp[n][1])<<endl;
}
return 0;
}
hard部分
唐山皇帝
题面
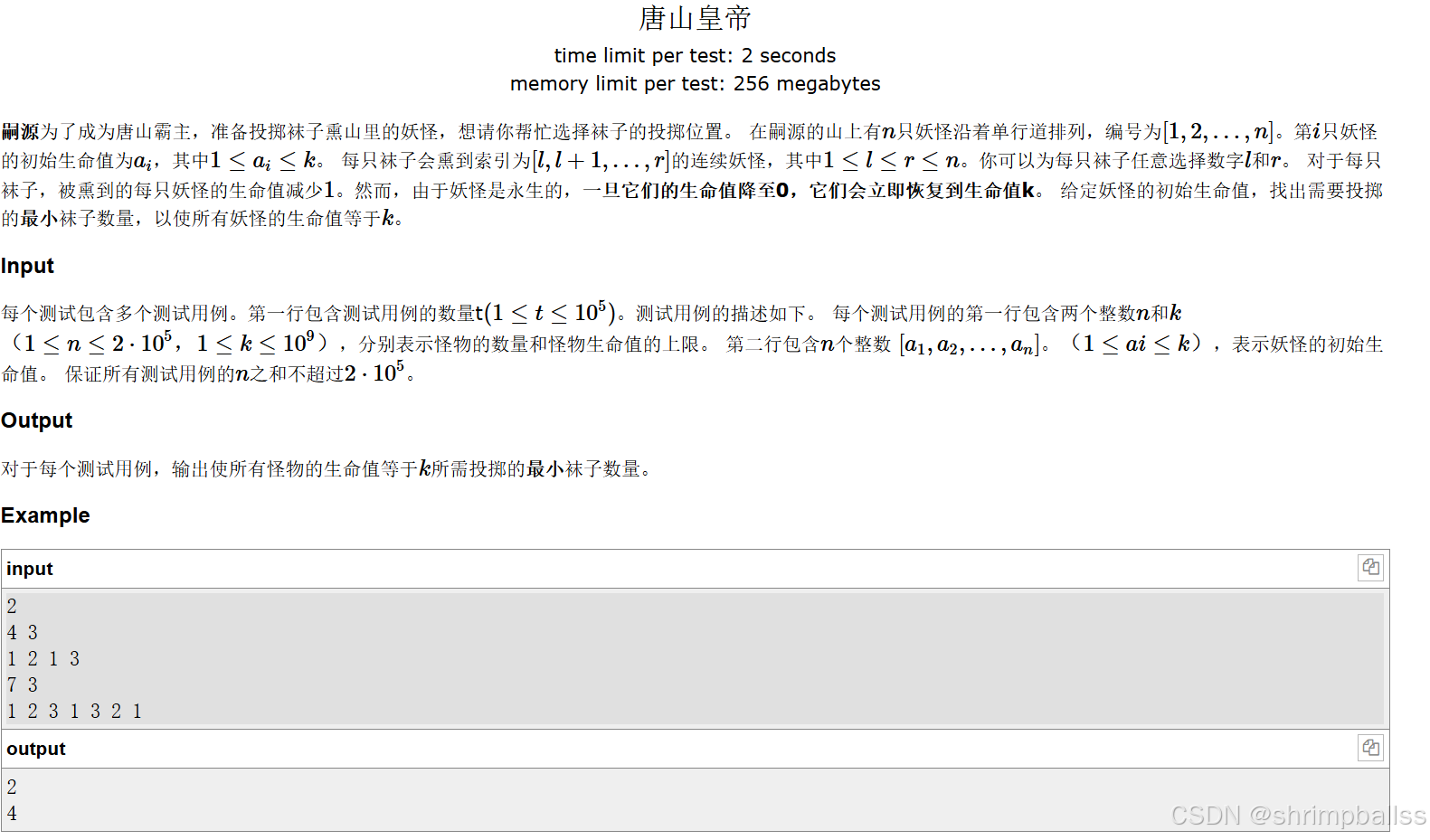
思路
首先将题目进行一定的转化,注意到对于一个 妖怪(数字),我们可以执行
次操作来使其符合条件(
为非负整数)。当确定了每个妖怪需要被执行的操作次数后,我们便可以容易地得出答案。
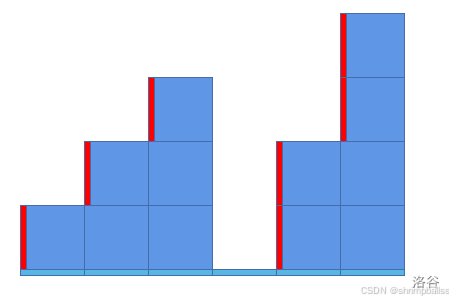
假设确定了每个妖怪需要被执行的操作次数为 [1,2,3,0,2,4],如下图所示,总共需要执行的操作次数即为红线标出的总长度,即 1+1+1+2+2=7。
不妨将每个妖怪的取值看作高度,将一个妖怪需要被操作的次数加上 称作提升。同时,由题意,高度恰好等于
的妖怪可以视为高度为 0,在下文中默认将所有高度恰好为
的妖怪的高度看作 0。
假设已经确定了 个妖怪需要被操作的次数,考虑第
个妖怪,将第
个妖怪的高度记作
。
1.若 ,那么可以直接不做任何提升操作。
2.若,有以下两种选择:
不做任何抬升操作,将答案增加
;
选择一个
,使得
最小(这个最小值后文记作
),并提升
范围中的每个妖怪,将答案增加
。
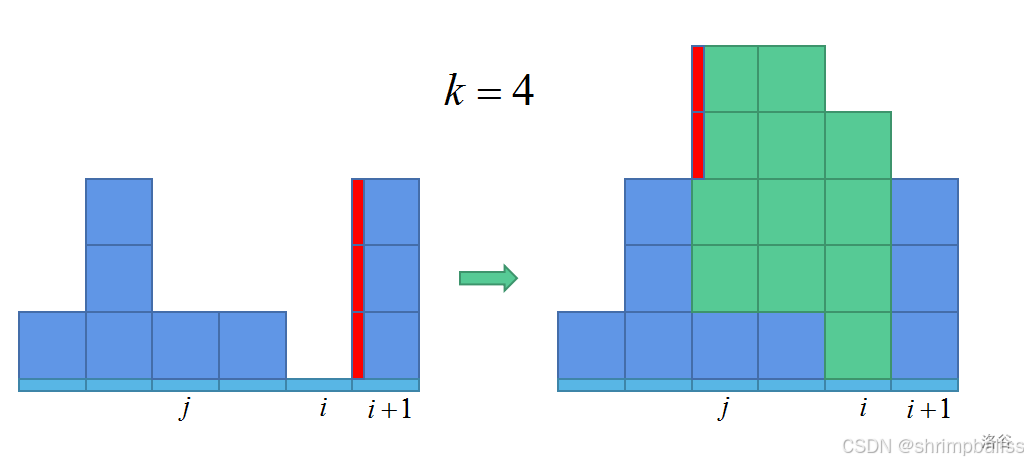
第一种操作很好理解,第二种操作的思想是将新增的妖怪前的妖怪提升,使得新增的妖怪不对答案产生贡献。同时,容易得知,如果选定一个妖怪,并将其及其后所有妖怪提升,其后妖怪产生的贡献不变,只有被选定的妖怪贡献产生变化。可参考下图。
在两种操作中选择一个贡献较小的,就完成了第个妖怪的计算。
这里按照这个思路直接模拟两种操作即可,不提供参考代码。
然而,每新增一个妖怪,这种方法就要向前遍历每一个妖怪,时间复杂度为,无法通过此题。
优先队列优化:
注意到,在上面的方法中,每个 最多被选中一次,且选择任意一个
进行操作后都不会影响其他任意一个
。那么,在每次新增一个妖怪后,我们可以预先计算好这个妖怪的
,并将其压入一个优先队列,这样之后的查询可以以
的复杂度完成。同时,由于每个
最多被选中一次,当我们通过优先队列获取到对应的
后,只需要将其出队而不需重新计算并入队。
引入优先队列进行优化后,每个妖怪需要花费 的时间计算
并入队,另外还可能需要
的时间出队。总体时间复杂度为
,使用的额外空间主要来自优先队列,空间复杂度
。
代码
#include<bits/stdc++.h>
using namespace std;
int a[200009];
void s()
{
int n,k;
cin>>n>>k;
for(int i=1; i<=n; i++)
{
cin>>a[i];
if(a[i]==k)a[i]=0;
}
long long ans=0;
priority_queue<long long , vector<long long> , greater<long long> >que;//小根堆
for(int i=1; i<=n; i++)
{
//上升 a[i]-a[i-1];
int cha=a[i]-a[i-1];
if(!que.empty()&&que.top()+k<cha)//可以贪
{
ans+=(que.top()+k);
que.pop();
que.push(cha-k);//将改变后的下降高度继续丢入小根堆
}
else
{
if(cha<0)que.push(cha);
ans+=max(0,cha);//只加上升量
}
}
cout<<ans<<endl;
}
int main()
{
int t;
cin>>t;
while(t--)s();
}
very hard(防ak)部分
一个简单数学题(hard version)
改编自IMO数学竞赛的练习中的数学题,经过研一学长的验题,本题目被他ac了以后从最难题的地位降到了第二。题解主要讲生成函数结合复变函数的解题思路。
一开始本题目不允许使用矩阵快速幂,后面心软了发布E题能用矩阵的公告。
如果采取矩阵快速幂的方式本体难度直线下降到mid hard。如果通过推论的方式本题的难度是非常高的。矩阵快速幂的题解在此不做赘述,此题解证明结论的严格推论。
本题有两人是用结论通过此题(金鳞玲同学以及李武同学)tql。
题面
思路
强行解释太生硬,让我们从一个具体的例子来展开。比如样例的 这种情况。我们知道数字集合为
。那么它的子集根据总和可以分为下列图中几类:

总和为0、5、10、15的子集加在一起总共有8个。因此本例答案为8。但是我显然不是为了让你数数而告诉你这些。我们换另一种角度看看能不能得到答案。
我们知道集合中的每个元素都有两种选择,选或不选,所以我们一开始就知道了原集合的所有子集的数量是。这很像二项分布的样子对吗,但是本体总和的计算是深受数值的影响的,每个元素的权重不同,不能直接通过二项分布直接得出。
但是这个转化很简单,我们知道 是二项分布的形式,在样例中不妨先直接套用令
,然后我们套上权值就得到
这里解释为什么这么做。在二项分布也就是第一个式子中 表示了一个数的两种选择,如果当前这个数字出现在我想要的子集里那么我就从1和
中选择
,否则选择1。而第二个式子中
中
表示当前的数字是几。
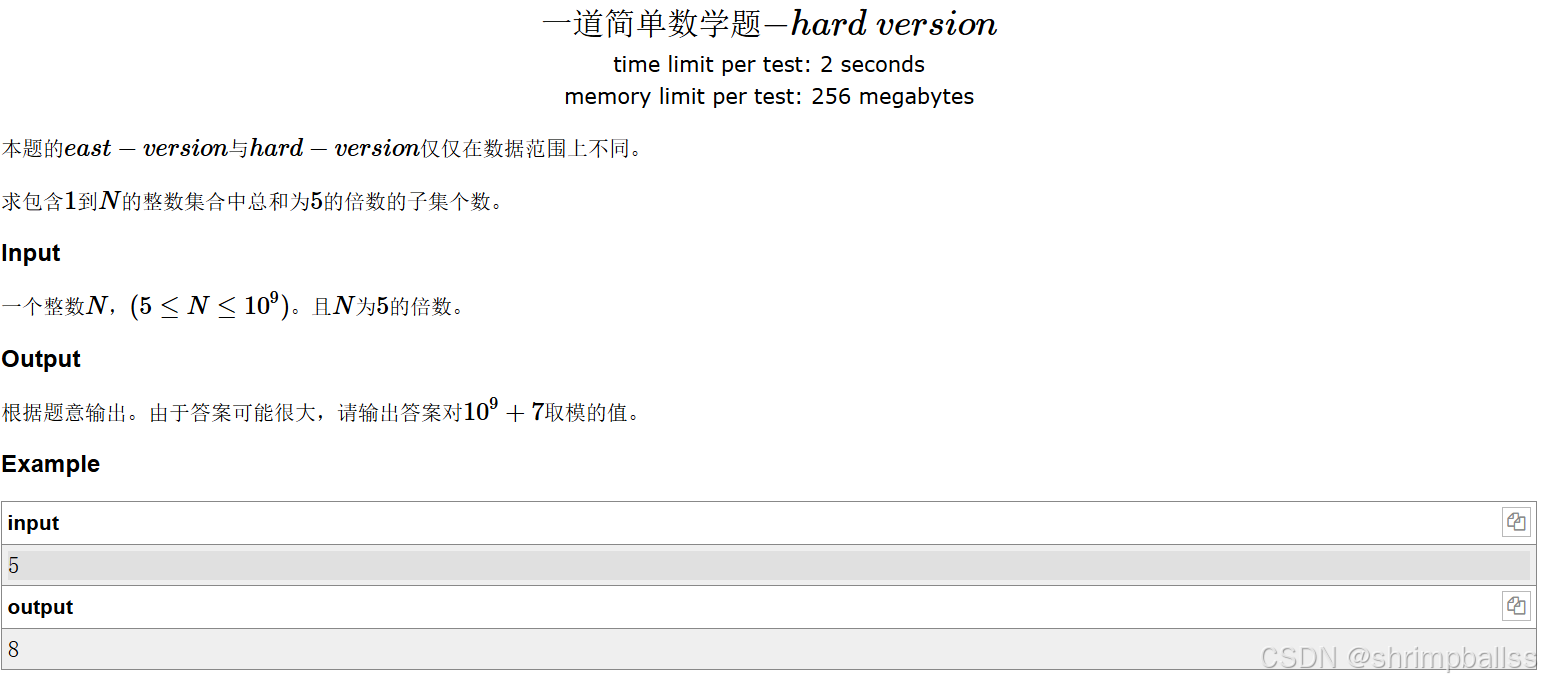
因此当我们把展开后就如下图:
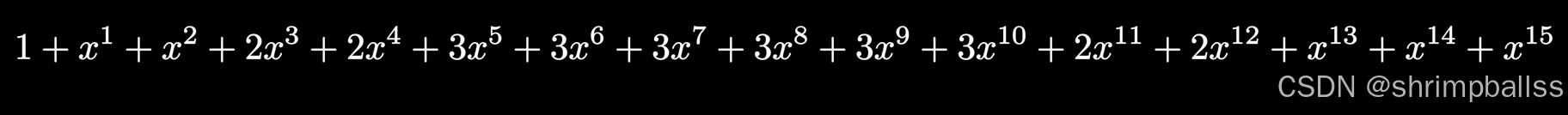
对应之前我们列出来的各种情况,的次数对应总和,例如总和为8的子集个数我们就可以通过查找
的系数,对应上面的展开式也就是3。
可能是由
得到的也有可能是
得到的诸如此类,所有的情况之和就是
的系数。换句话说就是总和为8的集合可能是
等等,但是总共有3个这样的集合。所以为了得到本题目的答案,我们只需要把
的系数相加就好,也就是
。
然后我们把他推广到。
这样就是。
这里我们再通过另一个我们已经知晓的东西来引进后面的内容。我们将推广后的式子展开成,
然后将 代入
易得
。
同理
所以。
为什么只有偶数项了呢?因为(-1)的周期是2。如果题目要求的是元素和为2的倍数的子集个数就好了。周期是2的我能推,那么周期为5的我是不是也能推呢?
聪明人已经发现可以用复数解决这样的问题。我们令。在复平面上的
:
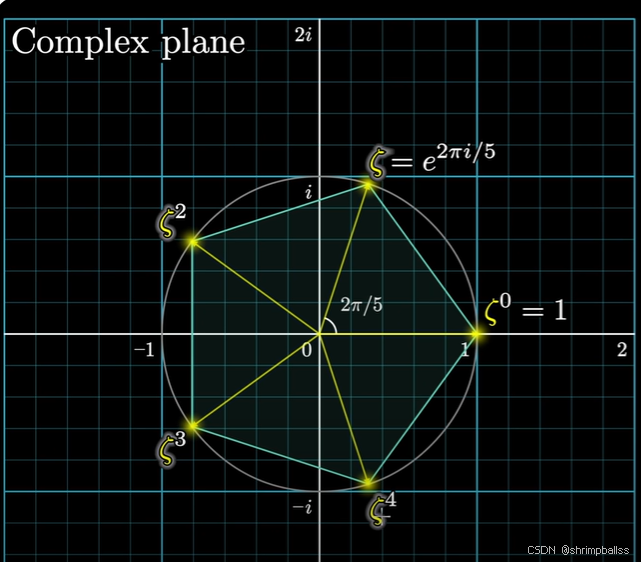
类比,我们要计算的是
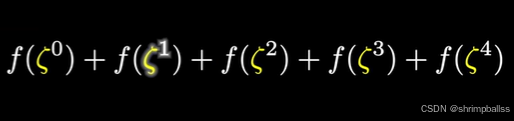
展开来如图:
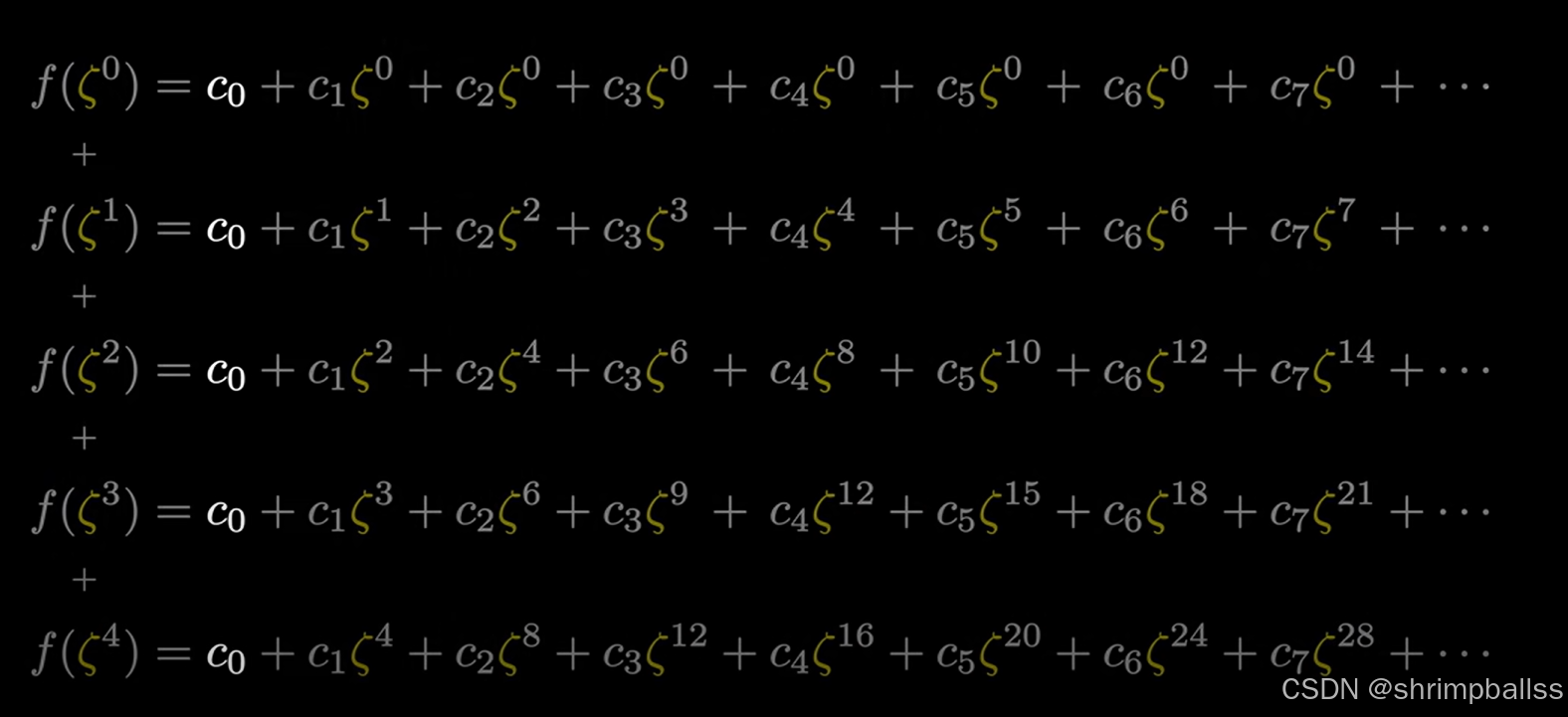
类似向量运算我们很快就知道。细心观察发现上面的图片中只有第5的倍数项是不为0的(自己画图就知道),而且知道是5。
所以:
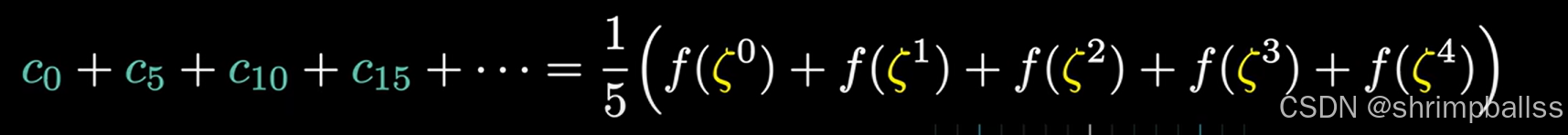
也就是说我们只需要算出右边的式子就能知道答案了。
我们从 的5周期性很容易就能推出
所以我们只需要知道 的值就行了。
再根据的5周期性得:
为了计算
我们设
将其因式分解:
将 -1 带入得知
所以:
本题的答案就是。
代码
#include<bits/stdc++.h>
using namespace std;
#define int long long
const int mod = 1e9+7;
int qmi(int a, int b)
{
int res = 1;
while(b)
{
if(b&1)res = res * a % mod;
a = a * a % mod;
b >>= 1;
}
return res;
}
void solve()
{
int n;
cin >> n;
int k = qmi(2,n);
int kk = qmi(2,n/5);
int sk = k + kk * 4;
sk %= mod;
sk *= qmi(5,mod - 2);
sk %= mod;
cout << sk << endl;
}
signed main()
{
int t=1;while(t--)solve();
}小孙无法思考
题面
思路
-
提示 #1
考虑如何确定是否可以生成 01 字符串 t 。
-
提示 #2
尝试设计一个只需要记录有用变量的 DP。
-
提示 #3
使用数据结构优化,或优化转移复杂度。
假设对 01 串 s 执行若干次操作后得到 01 串 t,不难发现 t 中每个元素一定对应 s 中一个子集的元素的 max。进一步观察可以发现这个子集一定构成一段区间,不妨写下 ti 对应 k=limaxrisk。
初始的串 t=s,因而所有 li=ri=i。假设当前的串 t 长度为 m,对应 l,r 两个序列,考虑如果在 1≤p≤m 的位置 p 执行了一次操作,得到的新序列 t′ 对应的 l′,r′ 两个序列。那么由于 ∀1≤i<p,ti′=max(ti,ti+1),∀p≤i<m,ti′=ti+1,可以发现 ∀1≤i<p,li′=li,ri′=ri+1,∀p≤i<m,li′=li+1,ri′=ri+1。如果只关注 l,r 两个序列到 l′,r′ 两个序列的变化,相当于删去了 lp 和 r1 两个值。
因此从 s 序列出发做 k 次操作,能生成的序列 t 对应的 l,r 序列,一定 l 序列是从 1∼n 任意删去 k 个值,r 序列是 k+1∼n。
现在,不妨考虑如何判定 01 串 t 能否被生成,将 t 反转得到 t′ 后,相当于目标是寻找 n≥p1>p2>...>pk≥1 使得 ∀1≤i≤k,ti′=k=pimaxn−i+1sk。一个显然正确的贪心策略是按照 i=1∼k 的顺序选择 pi,每次都选择最大的可行值。
现在考虑进行 DP,设 dpi,j 为有多少长度为 i 的 01 串 t,使得运行上述贪心算法后 pi 恰好取到 j。可以认为必定 p0=n+1,边界情况是 dp0,n+1=1。考虑从 dpi−1,j→dpi,∗ 的转移:
- 如果 s[j−1,n−i+1] 已经出现了 1,那么 t 反转后的第 i 位必须为 1,且必然 pi=j−1 ,将 dpi,j−1 加上 dpi−1,j。
- 如果 s[j−1,n−i+1] 未出现 1,t 反转后的第 i 位可以为 0,如果为 0 必然取 pi=j−1,还是将 dpi,j−1 加上 dpi−1,j;如果希望 t 反转后的第 i 位为 1,需要找到最大的 pos≤n−i+1 使得 spos 为 1,然后取 pi=pos,将 dpi,pos 加上 dpi−1,j。
两类转移可以看作是无论如何将 dpi,j−1 加上 dpi−1,j。然后找到最大的 pos≤n−i+1 使得 spos 为 1,对所有 j−1>pos 即 j≥pos+2 的 dpi,pos 加上 dpi,j。
可以将第一种转移视作对 DP 数组进行了整体平移,然后第二种转移是求 DP 数组一段后缀和再执行一次单点加,记录偏移量后容易使用线段树在 O(nlogn) 执行所有转移。
答案即是所有 1≤i≤n,1≤j≤n 的 dpi,j 之和,使用线段树维护时当然也可以 O(1) 求出当前的 dpi 的每一项之和(需要将 dpi−1,1 这一项平移后下标不在范围内的置零)。
由于转移有着更好的性质,实际上可以不用数据结构仅仅更巧妙地使用前缀和 O(n) 解决该问题,但这不是必要的。
代码
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
const ll mod=998244353;
const int N=1e6+5;
const int iu=1e6;
int n;
ll bit[N];
void upd(int id,ll v){
for(int i=id; i<=n ;i+=i&-i) bit[i]=(bit[i]+v)%mod;
}
ll qry(int id){
ll res=0;
for(int i=id; i>=1 ;i-=i&-i) res+=bit[i];
return res%mod;
}
char c[N];
int nxt[N];
void solve(){
string s;cin >> s;n=s.size();
for(int i=1; i<=n ;i++) c[i]=s[n-i];
for(int i=1; i<=n ;i++) bit[i]=0;
upd(1,1);
nxt[n+1]=n+1;
for(int i=n; i>=1 ;i--){
nxt[i]=nxt[i+1];
if(c[i]=='1') nxt[i]=i;
}
ll ans=0;
for(int i=1; i<=n ;i++){
if(c[i]=='0' && nxt[i]!=n+1){
int frog=nxt[i]-i+1;
ll add=qry(frog-1);
upd(frog,add);
}
ans+=qry(n-i+1);
}
ans%=mod;
cout << ans << '\n';
}
int main(){
ios::sync_with_stdio(false);cin.tie(0);
int t;cin >> t;
while(t--){
solve();
}
}
















 8253
8253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









