






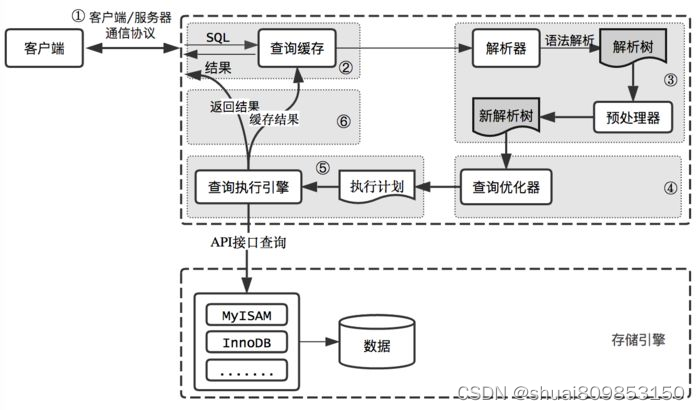
mysql 性能优化总结
文章目录
一、性能优化角度
1.1 需求和架构及业务实现优化
系统架构角度
1.最容易实现也是最基本的一点,就是尽量不要在数据库放一些奇怪的数据,比如二进制多媒体数据,流水队列数据,超大文本数据,可以使用类似阿里的对象存储来存大文件
2.是否合理利用了应用层的缓存机制
我们可以把不需要经常改动但需要经常查询的数据放进缓存中,比如用户的基本信息等
3.不要过度依赖sql语句的查询,能在代码中实现的就不要放在sql中来做
4.一些不合理的系统架构
比如缓存的不合理利用导致缓存命中率底下,浪费缓存的同时又浪费数据库的效率
过度依赖面向对象思想也会给系统带来不必要的压力
对可扩展性的过度追求,使系统被拆分的过度离散,需要使用大量的join语句
过度依赖数据库,把大量更适合放入文件系统的文件放入数据库,会造成资源的浪费和整体性能下降
过度理想化系统的用户体验,使大量的非核心业务消耗过多的资源
1.2.数据库自身的优化
数据库设计
1.在innodb能满足需求的情况下必须使用innodb,因为innodb支持事务,支持行级锁、更好的恢复性、高并发下性能更好,
2.字符集统一使用UTF8,兼容性更好,避免乱码,如果有存储emoji表情的需要,可以使用UFT8mb4字符集
3.使用comment从句添加表和列的备注,给所有字段和表都加上注释
4.单表数据量大小建议控制在500万以内,500万并不是MySQL的极限,但不建议过大,会造成表结构修改、备份恢复都有问题,可以使用分库分表等
5.谨慎使用分区表,分区表在物理上为多个文件,在逻辑上为一个表
6.尽量冷热分离,减少表的宽度,比如 用户的昵称和账号等信息基本不会改变,但是可能用户的积分等信息会经常改变,就可以把数据进行冷热分离
索引设计
1.单表索引建议不超过5个,增加查询效率的同时会减少插入和更新的效率
2.禁止给表中每一列都简历单独的索引
3.innodb的每个表必须有一个主键
4.常见索引列建议:
出现在 SELECT、UPDATE、DELETE 语句的 WHERE 从句中的列
包含在 ORDER BY、GROUP BY、DISTINCT 中的字段
并不要将符合 1 和 2 中的字段的列都建立一个索引, 通常将 1、2 中的字段建立联合索引效果更好
多表 join 的关联列
5.如何选择索引列的顺序:
把区分度(列中不同值的数量/列的总行数)最高的放在左侧
字段长度小的放在左侧,因为长度越小一页能存储的数据量就越大,IO性能就越好
频繁使用的放在左侧
6.避免简历冗余索引和重复索引:
重复索引示例:primary key(id)、index(id)、unique index(id)
冗余索引示例:index(a,b,c)、index(a,b)、index(a)
7.对于频繁的查询优先考虑使用覆盖索引(包含了所有查询字段 (where,select,ordery by,group by 包含的字段) 的索引 ),覆盖索引的好处:
避免innodb进行索引的二次查询
可以把随机IO变成顺序IO加快查询效率
8.索引SET规范
不建议使用外键索引,但一定哟啊在表与表之间的关联键上建立索引
外键可用于保证数据的参照完整性,但建议在业务端实现
外键会影响父表和子表的写操作降低性能
数据库字段
1.优先选择符合存储需要的最小的数据类型,字段越大单页节点存储的数量就越少,io操作就越多,索引性能就越差
2.避免使用TEXT,BLOB类型数据,因为mysql的内存临时表不支持大数据,如果一定要使用这种类型,建议分出到单独的表中,并且这两个类型只支持前缀索引,
3.避免使用ENUM类型,因为ENUM类型的orderBy操作效率低
4.尽量把所有列定义为NOT NULL,因为索引NULL需要额外空间来保存,并且比较和计算时要对NULL值做特殊处理
5.使用TIMESTAMP(4个字节)或DATETIME(8个字节)存储时间,不要用字符串类型
1.3.sql语句的优化
对于MySQL层优化一般遵从的原则:
减少数据访问:设置合理的字段类型,启用压缩,通过索引访问等减少磁盘IO
返回更少的数据:只返回需要的字段和数据分页处理 减少磁盘io及网络io
减少交互次数:批量DML操作,函数存储等减少数据连接次数
减少服务器CPU开销:尽量减少数据库排序操作以及全表查询,减少cpu 内存占用
利用更多资源:使用表分区,可以增加并行操作,更大限度利用cpu资源
总结到SQL优化中,就三点:
最大化利用索引;
尽可能避免全表扫描;
减少无效数据的查询;
 来匹配,作用类似于java中的indexOf(),查询字符串出现的角标位置, - 尽量避免使用in 和not in,会导致引擎走全表扫描。如下:
SELECT * FROM t WHERE id IN (2,3)
优化方式:如果是连续数值,可以用between代替。如下:
SELECT * FROM t WHERE id BETWEEN 2 AND 3 - 尽量避免使用 or,会导致数据库引擎放弃索引进行全表扫描。如下:
SELECT * FROM t WHERE id = 1 OR id = 3
优化方式:可以用union代替or。如下:
SELECT * FROM t WHERE id = 1
UNION
SELECT * FROM t WHERE id = 3 - 尽量避免进行null值的判断,会导致数据库引擎放弃索引进行全表扫描。如下:
SELECT * FROM t WHERE score IS NULL
优化方式:可以给字段添加默认值0,对0值进行判断。如下:
SELECT * FROM t WHERE score = 0
5.尽量避免在where条件中等号的左侧进行表达式、函数操作,会导致数据库引擎放弃索引进行全表扫描。
可以将表达式、函数操作移动到等号右侧。如下:
– 全表扫描
SELECT * FROM T WHERE score/10 = 9
– 走索引
SELECT * FROM T WHERE score = 10*9 - 当数据量大时,避免使用where 1=1的条件。通常为了方便拼装查询条件,我们会默认使用该条件,数据库引擎会放弃索引进行全表扫描。如下:
SELECT username, age, sex FROM T WHERE 1=1
优化方式:用代码拼装sql时进行判断,没 where 条件就去掉 where,有where条件就加 and。 - 查询条件不能用 <> 或者 !=
使用索引列作为条件进行查询时,需要避免使用<>或者!=等判断条件。如确实业务需要,使用到不等于符号,需要在重新评估索引建立,避免在此字段上建立索引,改由查询条件中其他索引字段代替。 - where条件仅包含复合索引非前置列
如下:复合(联合)索引包含key_part1,key_part2,key_part3三列,但SQL语句没有包含索引前置列"key_part1",按照MySQL联合索引的最左匹配原则,不会走联合索引。详情参考《联合索引的使用原理》。
select col1 from table where key_part2=1 and key_part3=2 - 隐式类型转换造成不使用索引
如下SQL语句由于索引对列类型为varchar,但给定的值为数值,涉及隐式类型转换,造成不能正确走索引。
select col1 from table where col_varchar=123; - order by 条件要与where中条件一致,否则order by不会利用索引进行排序
– 不走age索引
SELECT * FROM t order by age;
– 走age索引
SELECT * FROM t where age > 0 order by age;
4.少量使用SELECT*
5.禁止使用不含字段列表的INSERT语句
6.避免使用子查询,可以把子查询优化为join
7.避免使用join关联太多的表
8.减少同数据库的交互次数
9.使用in代替or,如果是连续的值,使用between and代替in
10.禁止使用order by rand将进行随机排序
11.WHERE从句中禁止堆列进行函数转换和计算
12.在明显不会有重复值时使用UNION ALL而不是UNION
13.拆分复杂的大SQL为多个小SQ
补充:sql相关命令

1、show processlist
2、explain select id ,name from stu where name=‘clsn’; # ALL id name age sex
select id,name from stu where id=2-1 函数 结果集 > 30;
show index from table;
3、通过执行计划判断,索引问题(有没有、合不合理)或者语句本身问题
4、 show status like ‘%lock%’; # 查询锁状态
kill SESSION_ID; # 杀掉有问题的 session
项目中遇到问题案例
查询统计一周数据,返回慢导致查询卡住 task 380W 数据,task_state 180w 数据
SELECT
t.access_time AS accessTime,t.resource_group_name,
t.cluster_name AS clusterName,
t.task_id AS taskId,
t.task_type AS taskType,
t.gpus AS gpus, IF
( t.worker_num < 1, 1, t.worker_num ) AS workerNum,
t.state AS state,
t.state_desc AS stateDesc,
t.host_ip AS hostIp,
t.ext_props AS extProps,
TIMESTAMPDIFF(
SECOND,
t.submit_time,
IFNULL(
ts.creating_time,
IFNULL(
t.start_time,
IF
( t.state IN ( 'Exception' ), t.submit_time, IFNULL( t.end_time, now( ) ) )
)
)
) AS timeDiff,
TIMESTAMPDIFF(
SECOND,
IF
( t.start_time IS NULL, t.submit_time, t.start_time ),
IF
( t.start_time IS NULL, t.submit_time, IFNULL( t.end_time, now( ) ) )
) AS timeRun FROM
(
SELECT
access_time,
cluster_name,
task_id,
task_type,
gpus,
worker_num,
state,
state_desc,
host_ip,
ext_props,
submit_time,
start_time,
end_time ,resource_group_name
FROM
task
WHERE
access_time BETWEEN '2022-11-21 00:00:00'
AND '2022-11-27 23:59:59'
AND cluster_name IN ( 'mlp_train_bhw_dg' )
AND task_type IN ( 'Job', 'Notebook', 'Service' )
AND ext_props NOT LIKE '%lifeCycleScript%'
AND resource_group_name IN ( SELECT resource_group_name FROM resource_group WHERE department LIKE '%OPPO%' AND resource_group_name NOT IN ( '' ) )
AND submit_time IS NOT NULL
AND state NOT IN ( 'Access', 'Waiting' )
AND t.cpus = 76
) t
INNER JOIN (
SELECT
task_id,
IF
( state = 'Creating', created_time, NULL ) AS creating_time
FROM
task_state
WHERE
state IN ( 'Creating', 'Submit' )
AND ( created_time BETWEEN '2022-11-21 00:00:00'
AND '2022-11-27 23:59:59' )
) ts ON t.task_id = ts.task_id
查询计划看出 join task_state 索引遍历数据row 数据太多导致查询慢
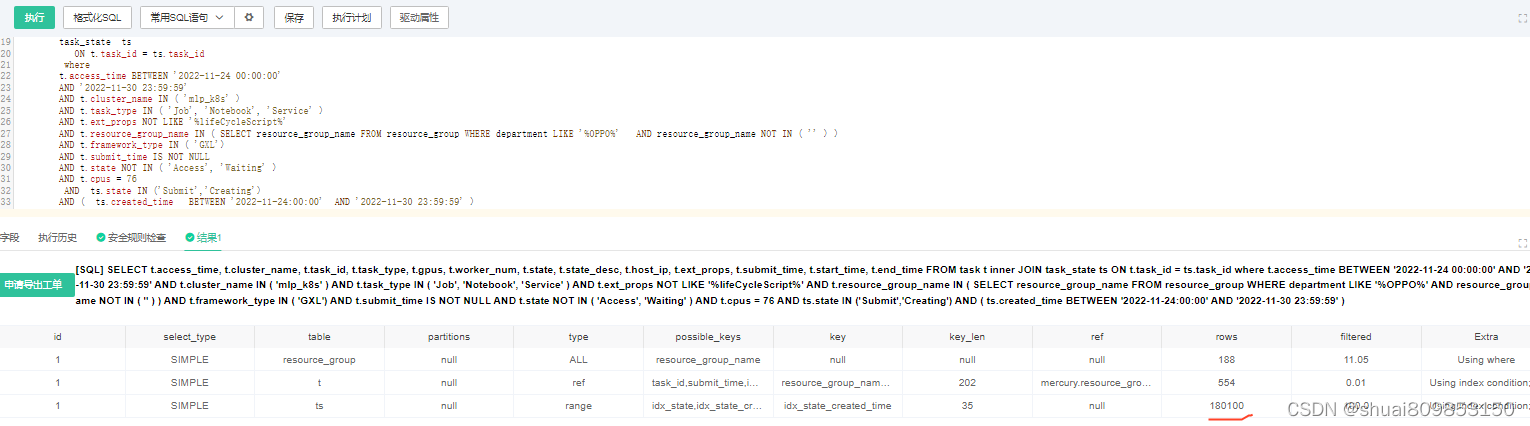
优化方案1. 使用with as 语句
因with as 子查询仅执行一次,将结果存储在用户临时表中,提高查询性能
with tmp1 as
(
SELECT task_id,IF( state = 'Creating', created_time, NULL ) AS creating_time FROM task_state
WHERE
state IN ( 'Creating', 'Submit' )
AND ( created_time BETWEEN '2022-11-21 00:00:00'
AND '2022-11-27 23:59:59' )
)
select xxx
FROM
task
left join tmp1 ts ON t.task_id = ts.task_id
WHERE
access_time BETWEEN '2022-11-21 00:00:00'
AND '2022-11-27 23:59:59'
AND cluster_name IN ( 'mlp_train_bhw_dg' )
AND task_type IN ( 'Job', 'Notebook', 'Service' )
AND ext_props NOT LIKE '%lifeCycleScript%'
AND resource_group_name IN ( SELECT resource_group_name FROM resource_group WHERE department LIKE '%OPPO%' AND resource_group_name NOT IN ( '' ) )
AND submit_time IS NOT NULL
AND state NOT IN ( 'Access', 'Waiting' )
AND t.cpus = 76
只支持MySQL 8.0以上版本
优化方案2.使用临时表缓存数据
CREATE TEMPORARY TABLE task_state (xx BIGINT(20), xx1 VARCHAR(200));
SELECT task_id,IF( state = ‘Creating’, created_time, NULL ) AS creating_time FROM task_state
WHERE
state IN ( ‘Creating’, ‘Submit’ )
AND ( created_time BETWEEN ‘2022-11-21 00:00:00’
AND ‘2022-11-27 23:59:59’ )
优化方案3. 代码分页查询
根据时间区间查询每日(数据量相对少)数据再合并数数据















 388
388











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









