







单位:Google Research
时间:2020.2
发表:ICLR2020
论文链接:https://arxiv.org/abs/1909.11942
一、前言
1. ALBERT想做些什么?
深度学习在模型结构想不到更好的后,就会想到增加模型的规模即深度和宽度,google团队在提出bert模型后也如是思考,想通过增加bert的宽度来提高效果。
但bert模型再预训练时已经很大了,强如google拥有这么好的TPU集群,增加self_attention神经元个数至2048时也跑不动。于是乎便想找方法来减少模型的参数,让更深更宽的bert可以训练。
2. ALBERT做到了什么?
在论文的摘要中,作者如是说:
综合经验证据表明,我们提出的方法导致的模型与原始的BERT相比,其规模大小要好得多。我们的最佳模型在GLUE、RACE和SQuAD基准上建立了新的最先进的结果,而与BERT-large相比,其参数更少
提出的ALBERT-base模型,表现与BERT-base相当,其参数量仅仅是后者的十分之一!
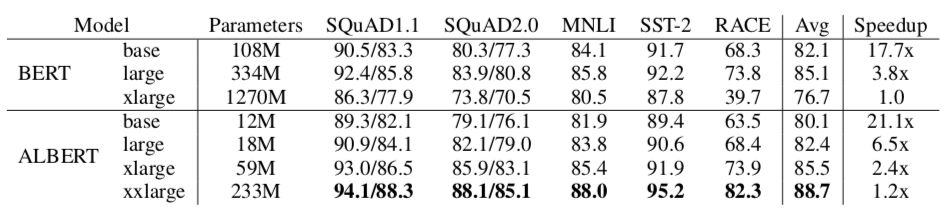
不过这里要先泼一泼冷水,如果你想要的是一个预测时间大幅减少在低算力的服务器能上线的模型的话,那么AL
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 595
595











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









