






前言
当我们做海洋和大气的资料同化时,往往需要大量的GDAS数据。为此,分享一个爬取大量gdas数据的程序。
一、GDAS及下载地址?
GDAS(Global Data Assimilation System)数据是由美国国家气象局(NWS)提供的一种全球气象数据集,主要用于天气预报和气候研究。GDAS数据通过同化来自多种观测来源(如卫星、雷达和地面气象站)的实时数据,生成高分辨率的气象分析场。这些数据包括温度、湿度、风速、气压等多种气象变量,广泛应用于数值天气预报模型和气候研究,为气象预报、灾害监测和气候变化研究提供重要的基础数据支持。
目前我发现的几个存储GDAS数据的网址
1.NCEI.NOAA存储地点NOAA gdas,只有近一年

2.NCAR存储NCAR gdas,1997-2024

3.第三个也是NCEI的NOAA官网地址:https://www.ncei.noaa.gov/products/weather-climate-models/global-data-assimilation,但需要使用邮箱申请,然后等申请通过在邮箱里面下载

二、下载脚本(python)
1.NOAA官网数据(只有距今最近一年)爬取
由于其内不同观测类型和总的数据集都有,但一般同化只用prepbufr.nr就行,里面所有观测类型都有,当然文件大小也是最大,所以我只爬取不同时刻的这个文件
代码如下:
import os
from datetime import datetime, timedelta
start_date = datetime(2023, 11, 1) # 下载起始时间,输入前先去网站看看有哪些时间的数据
end_date = datetime(2024, 10, 22) # 下载结束时间,注意事项同上
time_tags = ['00', '06', '12', '18'] # 4*daily
file_extension = '.prepbufr.nr'
current_date = start_date
while current_date <= end_date:
date_month = current_date.strftime('%Y%m')
date_day = current_date.strftime('%Y%m%d')
base_url = f'https://www.ncei.noaa.gov/data/ncep-global-data-assimilation/access/{date_month}/{date_day}/gdas.t'
for time_tag in time_tags:
url = f'{base_url}{time_tag}z{file_extension}'
save_path = f'{current_date.strftime("%Y%m%d")}_gdas.t{time_tag}z{file_extension}'
# 不同年份会出现相同名字的数据,所以下载完用确切时间命名
command = f'wget -O {save_path} {url}'
response = os.system(command)
if response == 0:
print(f'successful: {save_path}')
else:
print(f'error: URL: {url}')
current_date += timedelta(days=1)
2.NCAR官网数据爬取
这里我下载的是最下面的Unrestricted GDAS PREPBUFR Data (synoptic PREPBUFR files),如果需要下载其他的可以自行修改程序,但要注意,每个数据的格式(有的是tar压缩包)不同,时间覆盖也不同。
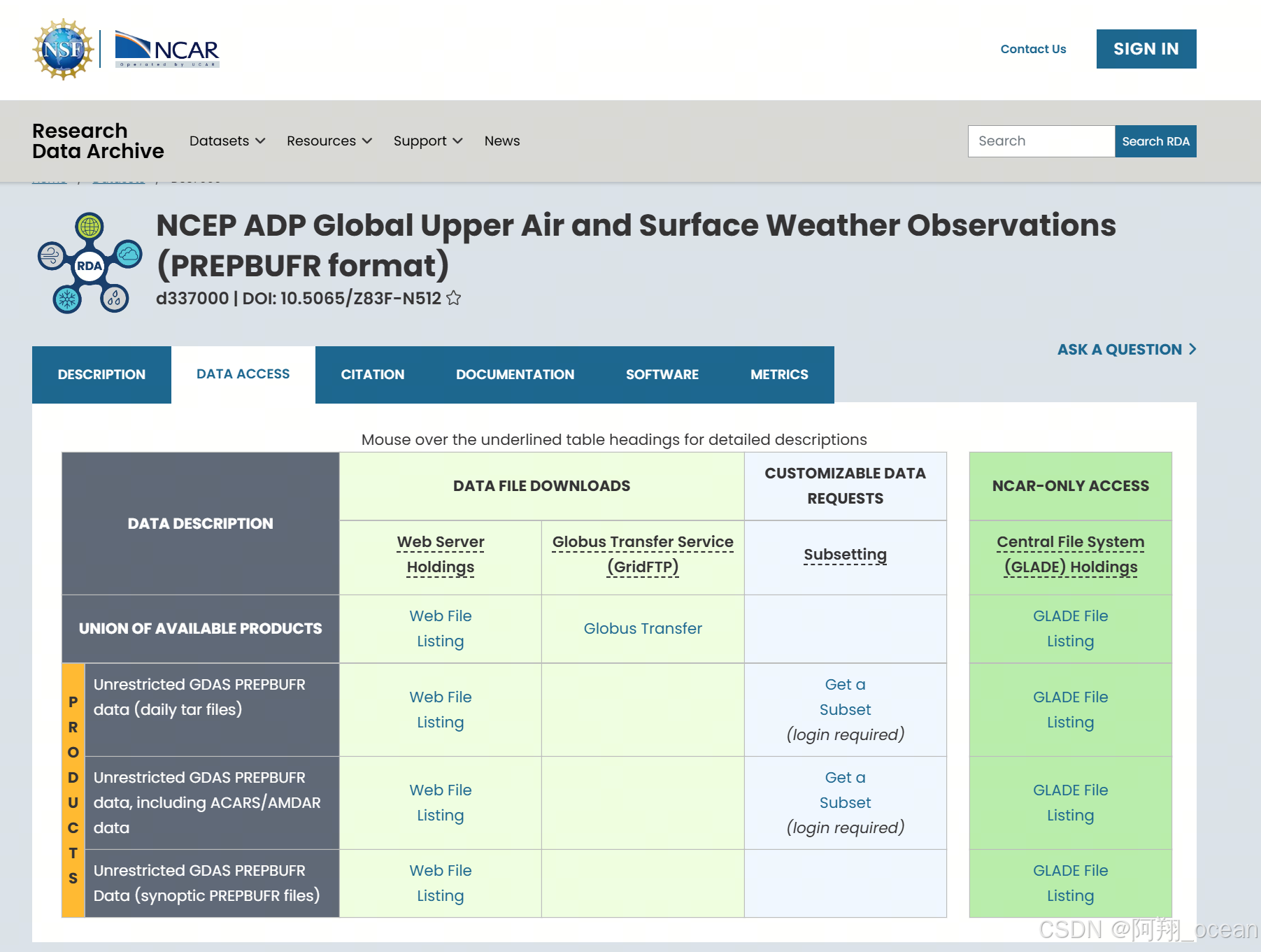
代码如下:
import os
import sys
import time
from urllib.request import build_opener
from datetime import datetime, timedelta
# 初始化下载器
opener = build_opener()
# 输入日期范围
start_date_str = input("请输入开始日期 (格式: YYYYMMDDHH): ") # 注意HH只能时00、06、12、18
end_date_str = input("请输入结束日期 (格式: YYYYMMDDHH): ") #同上
# 转换为 datetime 对象
start_date = datetime.strptime(start_date_str, "%Y%m%d%H")
end_date = datetime.strptime(end_date_str, "%Y%m%d%H")
# 生成日期列表
date_list = []
current_date = start_date
while current_date <= end_date:
date_list.append(current_date)
current_date += timedelta(hours=6) # 每6小时生成一个时间点
# 下载文件
for date in date_list:
year = date.year
folder = f"{year}" # 以年份命名文件夹
os.makedirs(folder, exist_ok=True) # 创建文件夹(如果不存在)
# 生成文件名
file_name = f"prepbufr.gdas.{date.strftime('%Y%m%d%H')}.nr"
file_url = f"https://data.rda.ucar.edu/d337000/prepnr/{year}/{file_name}"
retries = 5 # 重试次数
for attempt in range(retries):
try:
sys.stdout.write(f"下载 {file_name} 到 {folder} ... ")
sys.stdout.flush()
infile = opener.open(file_url)
with open(os.path.join(folder, file_name), "wb") as outfile:
outfile.write(infile.read())
sys.stdout.write("done\n")
break # 下载成功后退出重试循环
except Exception as e:
sys.stdout.write(f"失败: {e}\n")
if attempt < retries - 1: # 如果不是最后一次尝试
time.sleep(2) # 等待2秒后重试
sys.stdout.write("正在重试...\n")
else:
sys.stdout.write("达到最大重试次数,跳过此文件。\n")
time.sleep(1) # 每次下载之间等待1秒
要注意数据更新到哪了再填,例如今天就更新到了2024110112
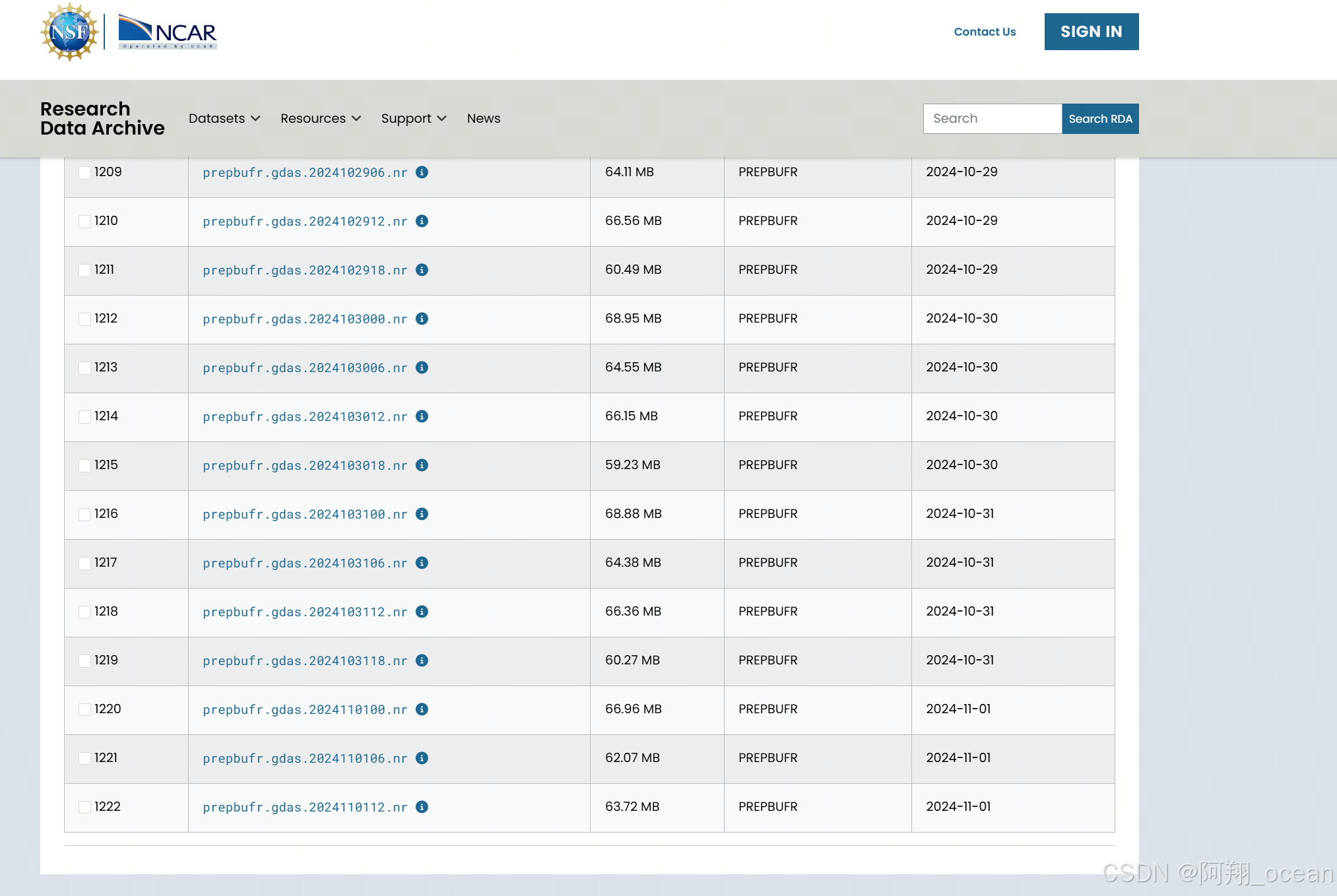
例如我要04年01月1日的到2024年11月1日12时(最新就到这)的。运行完程序后,先输入20040100,然后回车,再输入2024110112就行
如图所示
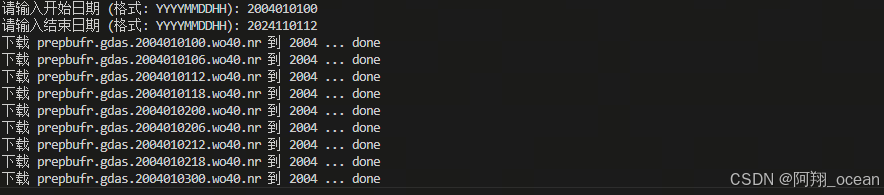
此外,我发现有时候会出现下载申请被拒绝,所以我这里设置了重试次数为5次,然后每两次下载之间停一秒(可能过快,可自行设定)以防请求频率过快
这里就实现了重新下载

就这些吧



















 1963
1963

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











