







Nutch是一个开源Java实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。
爬虫crawler和查询searcher。Crawler主要用于从网络上抓取网页并为这些网页建立索引。Searcher主要利用这些索引检索用户的查找关键词来产生查找结果。两者之间的接口是索引,所以除去索引部分,两者之间的耦合度很低。
Crawler和Searcher两部分尽量分开的目的主要是为了使两部分可以分布式配置在硬件平台上,例如将Crawler和Searcher分别放在两个主机上,这样可以提升性能
Nutch的目标:
Nutch 致力于让每个人能很容易,同时花费很少就可以配置世界一流的Web搜索引擎。为了完成这个宏伟的目标,nutch必须能够做到:• 每个月取几十亿网页
• 为这些网页维护一个索引
• 对搜引文件进行每秒上千次的搜索
• 提供高质量的搜索结果
• 以最小的成本运作
这将是一个巨大的挑战
Nutch的安装:
首先获取nutch2.3
wget https://archive.apache.org/dist/nutch/2.3/apache-nutch-2.3-src.tar.gz解压nutch 2.3
tar -zxvf apache-nutch-2.3-src.tar.gz重名字nutch
mv apache-nutch-2.3 nutch
nutch的配置:
第一步:进入conf/nutch-site.xml
<!-- 指定gora 后端 ,指定存储位置为Hbase-->
<property>
<name>storage.data.store.class</name>
<value>org.apache.gora.hbase.store.HBaseStore</value>
<description>Default class for storing data</description>
</property>
<!-- 指定nutch插件 -->
<property>
<name>plugin.includes</name>
<value>protocol-httpclient|urlfilter-regex|index-(basic|more)|
query-(basic|site|url|lang)|indexer-solr|nutch-extensionpoints|
protocol-httpclient|urlfilter-regex|parse-(text|html|msexcel|msword
|mspowerpoint|pdf)|summary-basic|scoring-opic|urlnormalizer-(pass
|regex|basic)protocol-http|urlfilter-regex|parse-(html|tika|metatags)
|index-(basic|anchor|more|metadata)</value>
</property>
<!--取消这个批注,使用hbase做为gora的后端 -->
<dependency org="org.apache.gora" name="gora-hbase"
rev="0.5" conf="*->default" />
<--将HbaseStore设为默认的存储 -->
gora.datastore.default=org.apache.gora.hbase.store.HBaseStore
第四步:进入nutch 的目录下
监测ant的版本输入ant –version
输入ant runtime 命令
这个命令将构建你的apache nutch,在nutch的家目录下面将创建相应的目录(runtime)。这个步骤是必须的,因为nutch2.3仅仅作为源码进行了发布。所有的目录里面最重要的是runtime,包含了所有需要爬行的脚本
ant之后:第五步:进入runtime/local/conf中,打开nutch-site,加入Http代理的名字。
<property>
<name>http.agent.name</name>
<value>My Nutch Spider</value>
</property>
<!--同时指定gora后端,以及指定插件。
<property>
<name>storage.data.store.class</name>
<value>org.apache.gora.hbase.store.HBaseStore</value>
<description>Default class for storing data</description>
</property>
<!-- 指定nutch插件 -->
<property>
<name>plugin.includes</name> <value>protocol-httpclient|urlfilter-regex|index-(basic|more)|query-(basic|site|url|lang)|indexer-solr|nutch-extensionpoints|protocol-httpclient|urlfilter-regex|parse-(text|html|msexcel|msword|mspowerpoint|pdf)|summary-basic|scoring-opic|urlnormalizer-(pass|regex|basic)protocol-http|urlfilter-regex|parse-(html|tika|metatags)|index-(basic|anchor|more|metadata)</value>
</property>
测试:前提是在你的本机上已经安装好了Solr
bin/crawl <seedDir> <crawlID> <solrURL><numberOfRounds>
bin/crawl urls/seed.txt alan http://192.168.14.151:8983/solr/ 2
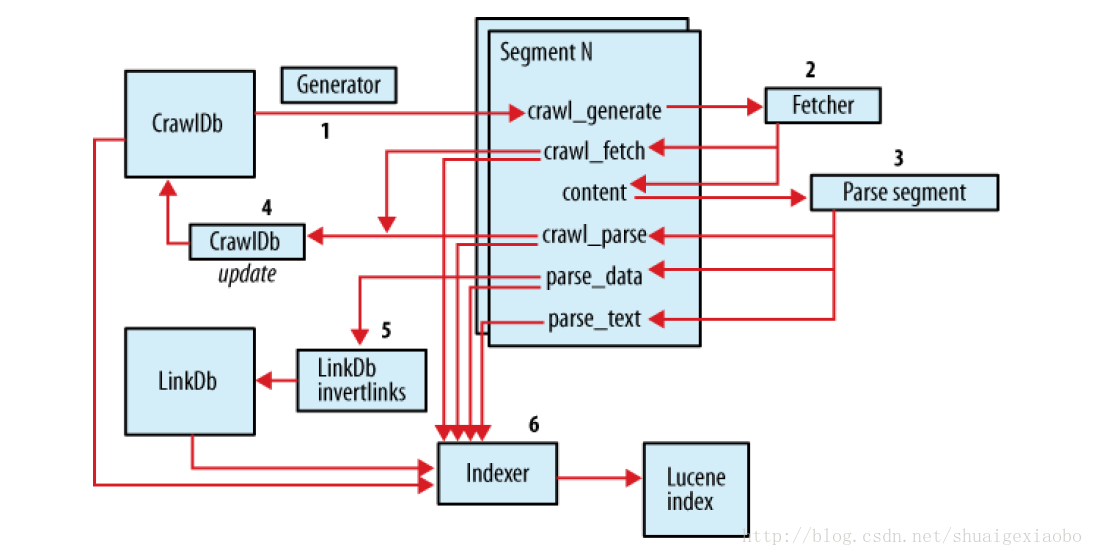
1) 建立初始 URL 集
2) 将 URL 集注入 crawldb 数据库---inject
crawldb中存放的是url地址,第一次根据所给url::http://blog.csdn.net/shuaigexiaobo/进行注入,然后updatecrawldb 保存第一次抓取的url地址,下一次即depth=2的时候就会从crawldb中获取新的url地址集,进行新一轮的抓取。
crawldb中有两个文件夹:current 和old. current就是当前url地址集,old是上一次的一个备份。每一次生成新的,都会把原来的改为old。
3) 根据 crawldb 数据库创建抓取列表---generate
4) 执行抓取,获取网页信息---fetch
5) 解析抓取的内容---parse segment
6) 更新数据库,把获取到的页面信息存入数据库中---updatedb
7) 重复进行 3~5 的步骤,直到预先设定的抓取深度。
---这个循环过程被称为“产生/抓取/更新”循环
8) 根据 sengments 的内容更新 linkdb 数据库---invertlinks
可以看到,一个segment包括以下子目录(多是二进制格式):
content:包含每个抓取页面的内容
crawl_fetch:包含每个抓取页面的状态
crawl_generate:包含所抓取的网址列表
crawl_parse:包含网址的外部链接地址,用于更新crawldb数据库
parse_data:包含每个页面的外部链接和元数据
parse_text:包含每个抓取页面的解析文本
每个文件的生成时间
1.crawl_generate在Generator的时候生成;
2.content,crawl_fetch在Fetcher的时候生成;
3.crawl_parse,parse_data,parse_text在Parse segment的时候生成。
linkdb: 链接数据库,用来存储每个网址的链接地址,包括源地址和链接地址。
9) 建立索引---index
感谢:http://www.cnblogs.com/huligong1234/p/3515214.html
Nutch的 过滤
在Nutch的conf目录中有automaton-urlfilter.txt、regex-urlfilter.txt、suffix-urlfilter.txt、prefix-urlfilter.txt、domain-urlfilter.txt几个文件用于实现过滤抓取数据,比如不抓取后缀为gif、exe的文件等,通过修改其中的值可以达到只抓取感兴趣的内容的目的,在一定程度上也有助于提高抓取速度。
在抓取过程中,这几个文件不是都起作用的,默认情况下只有regex-urlfilter.txt会达到过滤目的,这一点可以从Nutch-default.xml确认。在进行过滤规则的修改之前,先说明Nutch的过滤器原理。在Nutch中,过滤器是通过插件的方式实现的,插件在nutch-default.xml中定义,具体如下:
<!-- pluginproperties -->
<property>
<name>plugin.folders</name>
<value>plugins</value>
</property>
<property>
<name>plugin.auto-activation</name>
<value>true</value>
</property>
<property>
<name>plugin.includes</name>
<value>protocol-http|urlfilter-regex|parse-(html|tika)|index-(basic|anchor)|urlnormalizer-(pass|regex|basic)|scoring-opic</value>
</property>
<property>
<name>plugin.excludes</name>
<value></value>
</property>
其中plugin.folders定义了插件放置的位置,该值可以为绝对路径或者相对路径,若为相对路径则会在classpath中搜索,默认值为plugins,编译后的Nutch,会包含该文件夹。plugin.includes以正则表达式的方式定义了哪些插件将被包含在Nutch中,可以根据属性值查看plugins中的目录来确定默认值,比如urlfilter-regex,则说明默认情况下,过滤器插件使用的是urlfilter-regex,也即regex-urlfilter.txt文件。plugin.excludes属性以正则表达式的方式定义了哪些插件将被排除在Nutch之外定义了。
在了解了插件的定义后,具体看看过滤器分几种以及如何定义的。过滤器在nutch-default.xml中的定义如下:
<!-- urlfilterplugin properties -->
<property>
<name>urlfilter.domain.file</name>
<value>domain-urlfilter.txt</value>
</property>
<property>
<name>urlfilter.regex.file</name>
<value>regex-urlfilter.txt</value>
</property>
<property>
<name>urlfilter.automaton.file</name>
<value>automaton-urlfilter.txt</value>
</property>
<property>
<name>urlfilter.prefix.file</name>
<value>prefix-urlfilter.txt</value>
</property>
<property>
<name>urlfilter.suffix.file</name>
<value>suffix-urlfilter.txt</value>
</property>
<property>
<name>urlfilter.order</name>
<value></value>
</property>
通过上面的代码可知,过滤器可以分为5种,分别为:DomainURLFilter、RegexURLFilter、AutomatonURLFilter 、PrefixURLFilter、SuffixURLFilter,这5中过滤器的配置过滤规则的文件分别为:domain-urlfilter.txt、regex-urlfilter.txt、automaton-urlfilter.txt、prefix-urlfilter.txt、suffix-urlfilter.txt。属性urlfilter.order则定义了过滤器的应用顺序,所有过滤器都是与的关系。
了解了Nutch中是如何定义过滤器之后,再来看看具体的过滤规则文件,以regex-urlfilter.txt(默认情况下即按照该文件中的规则抓取数据)为例。该文件中定义的规则如下:
# skip file: ftp:and mailto: urls
-^(file|ftp|mailto):
# skip image andother suffixes we can't yet parse
# for a moreextensive coverage use the urlfilter-suffix plugin
-\.(gif|GIF|jpg|JPG|png|PNG|ico|ICO|css|CSS|sit|SIT|eps|EPS|wmf|WMF|zip|ZIP|ppt|PPT|mpg|MPG|xls|XLS|gz|GZ|rpm|RPM|tgz|TGZ|mov|MOV|exe|EXE|jpeg|JPEG|bmp|BMP|js|JS)$
# skip URLscontaining certain characters as probable queries, etc.
-[?*!@=]
# skip URLs withslash-delimited segment that repeats 3+ times, to break loops
-.*(/[^/]+)/[^/]+\1/[^/]+\1/
# accept anythingelse
+.
其中#表示注释内容,-表示忽略,+表示包含。若待抓取的url匹配该文件中的一个模式,则根据该模式前面的加号或者减号来判断该url是否抓取或者忽略,若url跟该文件中定义的规则都不匹配,则忽略该url。
感谢:http://blog.csdn.net/skywalker_only/article/details/17562543
Nutch 性能优化
读Nutch-site.xml
在nutch-site.xml中:
<name>fetcher.threads.fetch</name>
<value>10</value>
最大抓取线程数量
<name>fetcher.threads.per.queue</name>
<value>1</value>
同一时刻抓取网站的最大线程数量
配置这两个参数,扩大10至50倍,可以极大的加大抓取的性能。
更多关于Nutch-default.xml内容:参考 http://blog.csdn.net/xxx0624_/article/details/45703525
更多关于Nucth-site.xml文件,请 参考:http://www.cnblogs.com/zhjsll/p/4704371.html















 654
654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









