









1.顶点与输入布局:
除了空间位置,D3D的顶点还可以存储其他属性数据,且D3D允许我们自行构建顶点格式
①第一步:创建一个结构体来容纳选定的顶点数据
struct Vertex1
{
XMFLOAT3 Pos;
XMFLOAT4 Color;
};
struct Vertex2
{
XMFLOAT3 Pos;
XMFLOAT3 Normal;
XMFLOAT2 Tex0;
XMFLOAT2 Tex1;
};
// 成员使用XMFLOATn而不是XMVECTOR②第二步:需要向D3D提供该顶点结构体的描述,使它了解应如何来处理结构体中的每个成员,这种描述叫做输入布局描述(Input layout description),使用结构体D3D12_INPUT_LAYOUT_DESC
typedef struct D3D12_INPUT_LAYOUT_DESC
{
const D3D12_INPUT_ELEMENT_DESC *pInputElementDesc; // ...ELEMENT_DESC数组
UINT NumElements; // 👆数组元素数量
} D3D12_INPUT_LAYOUT_DESC;D3D12_INPUT_ELEMENT_DESC数组中的元素依次描述了顶点结构体中所对应的成员,所以,顶点结构体中有n个成员,那么D3D12_INPUT_ELEMENT_DESC数组就存有n个元素
typedef struct D3D12_INPUT_ELEMENT_DESC
{
LPCSTR SemanticName; // HLSL Semantic -- 不同着色器提供不同语义名
UINT SemanticIndex;
DXGI_FORMAT Format;
UINT InputSlot;
UINT AlignedByteOffset;
D3D12_INPUT_CLASSIFICATION InputSlotClass;
UINT InstanceDataStepRate;
} D3D12_INPUT_ELEMENT_DESC;
// SemanticName:
合法的语义名,通过语义可以将顶点结构体中的元素与顶点着色器VS输入签名中的元素一一映射起来
https://docs.microsoft.com/en-us/windows/win32/direct3dhlsl/dx-graphics-hlsl-semantics
// SemanticIndex:
语义索引,再不引入新的语义名的情况下区分两组不同
-- 比如2组不同的纹理坐标都对应语义TEXCOORD 但索引一个为0,一个为1
未标明索引的语义将默认其索引值为0 -- POSITION和POSITION0等价 比如两组纹理,在VS中的语义分别是TEXCOORD0 TEXCOORD1
// Format:
DXGI_FORMAT枚举类型元素,指明顶点元素的格式
DXGI_FORMAT_R32_FLOAT // 1D 32位浮点标量
DXGI_FORMAT_R32G32_FLOAT // 2D
DXGI_FORMAT_R32G32B32_FLOAT // 3D 对应FLOAT3
DXGI_FORMAT_R32G32B32A32_FLOAT // 4D 对应FLOAT4
DXGI_FORMAT_R8_UINT // 1D 8位无符号整型标量
... 自行查阅
// InputSlot:
指定传递元素所用的输入槽索引,D3D共支持16个输入槽(0~15),可以通过它们来向输入装配阶段传递顶点数据
目前我们只会用到输入槽0(所有顶点元素都来自同一个输入槽)
本章习题2会涉及多输入槽的编程实践
// AlignedByteOffset:
在特定输入槽中,从C++顶点结构体的首地址到其中元素其实地址的偏移量(字节表示)
比如上面Vertex2结构体,该偏移值依次为0,12,24,32
// InputSlotClass:
暂时指定为D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA
另一选项D3D12_INPUT_CLASSIFICATION_PER_INSTANCE_DATA则用于实例化这种高级技术
// InstanceDataStepRate:
目前设置为0,若采用实例化这种高级技术,设置为1对前面两种顶点结构,编写对应的D3D12_INPUT_ELEMENT_DESC数组
D3D12_INPUT_ELEMENT_DESC desc1[] =
{
{"POSITION",0,DXGI_FORMAT_R32G32B32_FLOAT,0,0,
D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA,0},
{"COLOR",0,DXGI_FORMAT_R32G32B32A32_FLOAT,0,12,
D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA,0},
};
D3D12_INPUT_ELEMENT_DESC desc2[] =
{
{"POSITION",0,DXGI_FORMAT_R32G32B32_FLOAT,0,0,
D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA,0},
{"NORMAL",0,DXGI_FORMAT_R32G32B32_FLOAT,0,12,
D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA,0},
{"TEXCOORD",0,DXGI_FORMAT_R32G32_FLOAT,0,24,
D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA,0},
{"TEXCOORD",1,DXGI_FORMAT_R32G32_FLOAT,0,32,
D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA,0},
};2.顶点和顶点缓冲区:
为了让GPU可以访问顶点数组,就需要把它们放置在称为缓冲区的GPU资源(ID3D12Resource)中,存放顶点的缓冲区叫做顶点缓冲区
缓冲区的结构比纹理更简单:既非多维资源,也不支持mipmap,过滤器以及多重采样等技术。
同4.3.8节中创建深度模板缓冲区一样:①首先填写D3D12_RESOURCE_DESC结构体来描述缓冲区资源②接着调用ID3D12Device::CreateCommittedResource方法来创建ID3D12Resource对象
Direct3D 12提供了一个C++包装类CD3DX12_RESOURCE_DESC,派生于D3DX12_RESOURCE_DESC,并附有多种便于使用的构造函数以及方法:
static inline CD3DX12_RESOURCE_DESC Buffer(
UINT64 width, // width对于缓冲区而言,代表所占用字节数
D3D12_RESOURCE_FLAGS flags = D3D12_RESOURCE_FLAG_NONE,
UINT64 alignment = 0
){
return CD3DX12_RESOURCE_DESC(
alignment, width, 1, 1, 1,
DXGI_FORMAT_UNKNOWN, 1, 0,
D3D12_TEXTURE_LAYOUT_ROW_MAJOR, flags
);
}
GPU的不同资源通过D3DX12_RESOURCE_DESC的成员dimension区分,缓冲区用D3D12_RESOURCE_DIMENSION_BUFFER类型表示,纹理则用D3D12_RESOURCE_DIMENSION_TEXTURE2D类型标识
对于静态几何体(每一帧都不会改变的几何体)而言,我们会将顶点缓冲区置于默认堆(D3D12_HEAP_TYPE_DEFAULT)中来优化性能。顶点缓冲区初始化完毕后,只有GPU需要从其中读取数据绘制几何体。然而,如果CPU不能向默认堆中的顶点缓冲区写入数据,那么我们该如何初始化此顶点缓冲区呢?
因此,我们还需要用D3D12_HEAP_TYPE_UPLOAD这种堆类型来创建一个处于中介位置的上传缓冲区资源。在4.3.8节里,我们就是通过把资源提交至上传堆,才得以将数据从CPU复制到GPU显存中。在创建了上传缓冲区后,我们就可以将顶点数据从系统内存复制到上传缓冲区,而后再把顶点数据从上传缓冲区复制到真正的顶点缓冲区中。
我们在d3dUtil.h/.cpp文件中构建了以下工具函数,以避免在每次使用默认缓冲区时再做这些重复的工作:
Microsoft::WRL::ComPtr<ID3D12Resource> d3dUtil::CreateDefaultBuffer(
ID3D12Device* device,
ID3D12GraphicsCommandList* cmdList,
const void* initData,
UINT64 byteSize,
Microsoft::WRL::ComPtr<ID3D12Resource>& uploadBuffer)
{
ComPtr<ID3D12Resource> defaultBuffer; // GPU资源
// 创建实际的默认缓冲区资源
ThrowIfFailed(device->CreateCommittedResource(
&CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_DEFAULT), // 默认堆
D3D12_HEAP_FLAG_NONE,
&CD3DX12_RESOURCE_DESC::Buffer(byteSize),
D3D12_RESOURCE_STATE_COMMON,
nullptr,
IID_PPV_ARGS(defaultBuffer.GetAddressOf())));
// 为了将CPU端内存中的数据复制到默认缓冲区,我们需要创建一个处于中介位置的上传堆
ThrowIfFailed(device->CreateCommittedResource(
&CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_UPLOAD), // 上传堆
D3D12_HEAP_FLAG_NONE,
&CD3DX12_RESOURCE_DESC::Buffer(byteSize),
D3D12_RESOURCE_STATE_GENERIC_READ, // 上传堆的启动状态
nullptr,
IID_PPV_ARGS(uploadBuffer.GetAddressOf())));
// 描述我们希望复制到默认缓冲区中的数据
D3D12_SUBRESOURCE_DATA subResourceData = {};
subResourceData.pData = initData;
subResourceData.RowPitch = byteSize;
subResourceData.SlicePitch = subResourceData.RowPitch;
// 将数据复制到默认缓冲区资源的流程
// UpdateSubresources辅助函数会先将数据从CPU端的内存中复制到位于中介位置的上传缓冲区里接着
// 再通过调用ID3D12CommandList::CopySubresourceRegion函数,把上传堆内的数据复制到mBuffer中
cmdList->ResourceBarrier(
1,
&CD3DX12_RESOURCE_BARRIER::Transition(defaultBuffer.Get(),
D3D12_RESOURCE_STATE_COMMON,
D3D12_RESOURCE_STATE_COPY_DEST // 该状态指示资源为某次复制操作的目的地
));
// dx12提供的函数
UpdateSubresources<1>(
cmdList,
defaultBuffer.Get(),
uploadBuffer.Get(),
0, 0, 1, &subResourceData
);
cmdList->ResourceBarrier(
1,
&CD3DX12_RESOURCE_BARRIER::Transition(defaultBuffer.Get(),
D3D12_RESOURCE_STATE_COPY_DEST,
D3D12_RESOURCE_STATE_GENERIC_READ // 其他读取状态位的逻辑OR组合,是上载堆所需的启动状态
));
// 调用以上函数后,必须保证uploadBuffer依然存在,而不能对它立即销毁,因为命令列表的复制操作可能尚未执行。当复制完成后,才可释放uploadBuffer
return defaultBuffer;
}👆函数作用:将数据从CPU端复制到上传堆,再从上传堆复制到GPU端的缓冲区中。其中上传堆与GPU端缓冲区在此函数中构造,且GPU端缓冲区资源作为函数返回值返回
后续如果想要绑定到渲染流水线上,使用SetGraphics...函数,并传入GPU端缓冲区的虚拟地址GetGPUVirtualAddress()
其中:
typedef struct D3D12_SUBRESOURCE_DATA
{
const void *pData;
LONG_PTR RowPitch;
LONG_PTR SlicePitch;
} D3D12_SUBRESOURCE_DATA;
// pData:
指向某个系统内存块的指针,其中有初始化缓冲区所用的数据
// RowPitch:
对于缓冲区而言,此参数为欲复制数据的字节数
// SlicePitch:
对于缓冲区而言,此参数亦为欲复制数据的字节数代码示例,创建存有立方体8个顶点的默认缓冲区:
Vertex vertices[] =
{
Vertex({ XMFLOAT3(-1.0f, -1.0f, -1.0f), XMFLOAT4(Colors::White) }),
Vertex({ XMFLOAT3(-1.0f, +1.0f, -1.0f), XMFLOAT4(Colors::Black) }),
Vertex({ XMFLOAT3(+1.0f, +1.0f, -1.0f), XMFLOAT4(Colors::Red) }),
Vertex({ XMFLOAT3(+1.0f, -1.0f, -1.0f), XMFLOAT4(Colors::Green) }),
Vertex({ XMFLOAT3(-1.0f, -1.0f, +1.0f), XMFLOAT4(Colors::Blue) }),
Vertex({ XMFLOAT3(-1.0f, +1.0f, +1.0f), XMFLOAT4(Colors::Yellow) }),
Vertex({ XMFLOAT3(+1.0f, +1.0f, +1.0f), XMFLOAT4(Colors::Cyan) }),
Vertex({ XMFLOAT3(+1.0f, -1.0f, +1.0f), XMFLOAT4(Colors::Magenta) })
};
const UINT64 vbByteSize = 8 * sizeof(Vertex);
ComPtr<ID3D12Resource> VertexBufferGPU = nullptr;
ComPtr<ID3D12Resource> VertexBufferUploader = nullptr;
VertexBufferGPU = d3dUtil::CreateDefaultBuffer(md3dDevice.Get(), mCommandList.Get(), vertices, vbByteSize, VertexBufferUploader);为了将顶点缓冲区绑定到渲染流水线上,我们需要给这种资源创建一个顶点缓冲区视图(vertex buffer view),与RTV不同的是,我们不需要为顶点缓冲区视图创建描述符堆。而且,顶点缓冲区视图由结构体D3D12_VERTEX_BUFFER_VIEW结构体来表示:
typedef struct D3D12_VERTEX_BUFFER_VIEW
{
D3D12_GPU_VIRTUAL_ADDRESS BufferLocation; // 顶点缓冲区资源虚拟地址 通过ID3D12Resource::GetGPUVirtualAddress方法获得地址
UINT SizeInBytes; // 顶点缓冲区大小(字节)
UINT StrideInBytes; // 每个顶点元素所占用的字节数
} D3D12_VERTEX_BUFFER_VIEW;
在顶点缓冲区及其对应视图创建完成之后,便可以将它与渲染流水线上的一个输入槽(input slot)相绑定。这样一来,我们就能向流水线中的输入装配器阶段传递顶点数据了。
void ID3D12GraphicsCommandList::IASetVertexBuffers(
UINT StartSlot,
UINT NumView,
const D3D12_VERTEX_BUFFER_VIEW *pViews
);
// StartSlot:
在绑定多个顶点缓冲区时,所用的起始输入槽。输入槽0~15
// NumView:
将要与输入槽绑定的顶点缓冲区数量(pViews中视图的数量)
一个输入槽绑定一个顶点缓冲区 假设StartSlot=k NumView=n 那么输入槽k k+1 ... k+n-1
// pViews:
指向顶点缓冲区视图数组中第一个元素的指针调用示例:
D3D12_VERTEX_BUFFER_VIEW vbv;
vbv.BufferLocation = VertexBufferGPU->GetGPUVirtualAddress();
vbv.StrideInBytes = sizeof(Vertex);
vbv.SizeInBytes = 8 * sizeof(Vertex);
D3D12_VERTEX_BUFFER_VIEW vertexBuffers[1] = { vbv };
mCommandList->IASetVertexBuffers(0,1,vertexBuffers);在我们示例中实际只会使用一个输入槽:
ID3D12Resource* mVB1;
ID3D12Resource* mVB2;
D3D12_VERTEX_BUFFER_VIEW mVBView1;
D3D12_VERTEX_BUFFER_VIEW mVBView2;
/*---创建顶点缓冲区及其视图---*/
mCommandList->IASetVertexBuffers(0,1,&mVBView1);
mCommandList->IASetVertexBuffers(0,1,&mVBView2);
// 都是用输入槽0将顶点缓冲区设置到输入槽上并不会对其执行实际的绘制操作,而仅为顶点数据送至渲染流水线做好准备而已。这最后一步才是通过ID3D12GraphicsCommandList::DrawInstanced方法真正地绘制顶点:
void ID3D12GraphicsCommandList::DrawInstanced(
UINT VertexCountPerInstance, // 每个实例要绘制的顶点数量
UINT InstanceCount, // 实现实例化的高级技术,目前只绘制一个实例,所以设置为1
UINT StartVertexLocation, // 顶点缓冲区内第一个被绘制顶点的索引
UINT StartInstanceLocation // 用于实现实例化的高级技术,暂时设置为0
);
// StartVertexLocation + VertexCountPerInstance 确定了一组连续的顶点3.索引和索引缓冲区:
索引缓冲区的创建流程和顶点缓冲区类似
为了使索引缓冲区与渲染流水线绑定,我们需要给索引缓冲区资源创建一个索引缓冲区视图,如同顶点缓冲区视图一样,我们也无须为索引缓冲区视图创建描述符堆
索引缓冲区视图由结构体D3D12_INDEX_BUFFER_VIEW来表示:
typedef struct D3D12_INDEX_BUFFER_VIEW{
D3D12_GPU_VIRTUAL_ADDRESS BufferLocation;
UINT SizeInBytes;
DXGI_FORMAT Format; // 唯一不同之处
} D3D12_INDEX_BUFFER_VIEW;
// Format:
索引格式,必须为表示16位索引的DXGI_FORMAT_R16_UINT类型,或表示32位索引的DXGI_FORMAT_R32_UINT类型
16位索引可以减少内存和带宽的占用,但如果索引范围超出16位数据的表达范围,那只能使用32位索引了与顶点缓冲区类型,使用ID3D12GraphicsCommandList::IASetIndexBuffer()方法将索引缓冲区绑定到输入装配器阶段,下列代码创建一个索引缓冲区来定义构成立方体的三角形:
索引下标是以0开始!
std::uint16_t indices[] =
{
// front face
0, 1, 2,
0, 2, 3,
// back face
4, 6, 5,
4, 7, 6,
// left face
4, 5, 1,
4, 1, 0,
// right face
3, 2, 6,
3, 6, 7,
// top face
1, 5, 6,
1, 6, 2,
// bottom face
4, 0, 3,
4, 3, 7
};
const UINT ibByteSize = 36 * sizeof(std::uint16_t);
ComPtr<ID3D12Resource> IndexBufferGPU = nullptr;
ComPtr<ID3D12Resource> IndexBufferUploader = nullptr;
IndexBufferGPU = d3dUtil::CreateDefaultBuffer(md3dDevice.Get(), mCommandList.Get(), indices.data(), ibByteSize, mBoxGeo->IndexBufferUploader);
D3D12_INDEX_BUFFER_VIEW ibv;
ibv.BufferLocation = IndexBufferGPU->GetGPUVirtualAddress();
ibv.Format = DXGI_FORMAT_R16_UINT;
ibv.SizeInBytes = ibByteSize;
mCommandList->IASetIndexBuffer(&ibv);最后注意,我们使用索引的时候,使用ID3D12GraphicsCommandList::DrawIndexedInstanced方法代替DrawInstanced方法进行绘制:
void ID3D12GraphicsCommandList::DrawIndexedInstanced(
UINT IndexCountPerInstance, // 每个实例将要绘制的索引数量
UINT InstanceCount, // 实例化高级技术,目前只绘制一个实例,所以设置为1
UINT StartIndexLocation, // 索引缓冲区的起始索引
INT BaseVertexLocation, // 在本次绘制调用读取顶点之前,要为每个索引都加上此整数值
UINT StartInstanceLocation // 实例化高级技术,暂时设置为0
);为理解这些参数,考虑这种情况,有3个要绘制的几何体,它们都有自己的顶点缓冲区和索引缓冲区。现在将3个物体各自的顶点缓冲区合并成一个大的顶点缓冲区,索引缓冲区也同样做此操作。此时存储的索引值是相对它们局部的顶点缓冲区,而非全局顶点缓冲区。所以需要对索引值进行重新计算,使之可以正确引用全局顶点缓冲区中的数据。所以BaseVertexLocation应运而生,从其名字可以看出就,这个值代表的就是某个几何体的局部顶点缓冲区相对于全局顶点缓冲区的偏移量,我们应该在原索引的基础上加上此偏移量。
基准顶点地址(base vertex location):每个物体第一个顶点相对于全局顶点缓冲区的位置
4.Vertex Shader(VS) -- 顶点着色器示例:
在D3D中,编写着色器的语言为高级着色语言(HLSL, High Level Shading Language)
实现简单的顶点着色器的代码:
cbuffer cbPerObject : register(b0)
{
float4x4 gWorldViewProj; // 位于常量缓冲区中
};
void VS(
float3 iPosL : POSITION,
float4 iColor : COLOR,
out float4 oPosH : SV_POSITION,
out float4 oColor : COLOR)
{
// 把顶点变换到齐次裁剪空间
oPosH = mul(float4(iPosL, 1.f), gWorldViewProj);
// 将顶点颜色传入像素着色器
oColor = iColor;
}
// float4()语法构造了一个4D向量
// HLSL中float2->2D,float3->3D,float4->4D
// 内置函数mul执行向量与矩阵之间 矩阵和矩阵之间... 的乘法 根据不同规模进行重载顶点着色器就是上例中名为VS的函数,我们可以给顶点着色器起任意合法的函数名。上述顶点着色器共有4个参数,前两个为输入参数,后两个为输出参数(out 关键字)。HLSL没有引用和指针的概念,所以借助结构体或多个输出参数才能从函数中返回多个值。HLSL中的所有函数都是内联(inline)函数。
前两个输入参数构成了输入签名,分别对应绘制立方体自定义顶点结构中的两个数据成员。参数语义":POSITION"和":COLOR"用于将顶点结构体中的元素映射到顶点着色器的相应输入参数。
输出参数也附有各自的语义,并以此为纽带,将顶点着色器的输出参数映射到下一个处理阶段(几何着色器或像素着色器)中所对应的输入参数。注意,SV_POSITION的语义比较特殊,SV代表系统值(system value),它所修饰的顶点着色器输出元素存有齐次裁剪空间中的顶点位置信息。因此,我们为输出位置信息的参数附上SV_POSITION语义,使GPU可以进行例如裁剪、深度测试和光栅化等处理之时,借此实现其他属性无法介入的有关运算。另外,对于任何不具有系统值的输出参数而言,我们都可以根据需求以合法的语义名修饰它。
注意1:如果没有使用几何着色器,那么顶点着色器必须用SV_POSITION语义来输出顶点在齐次裁剪空间中的位置,因为执行完顶点着色器后(在没有使用几何着色器的情况下),硬件期望获得顶点位于齐次裁剪空间之中的坐标。如果使用了几何着色器,那么可以把输出顶点在齐次裁剪空间中位置的工作交给它来处理。
注意2:在顶点着色器或几何着色器中是无法进行透视除法的,此阶段只能实现投影矩阵这一环节的运算。透视除法将在后面交给硬件执行。
我们可以将函数返回类型和输入签名打包成结构体:
cbuffer cbPerObject : register(b0)
{
float4x4 gWorldViewProj;
};
struct VertexIn
{
float3 PosL : POSITION;
float4 ColorL : COLOR;
};
struct VertexOut
{
float4 PosH : SV_POSITION; // 注意这里是float4而不是float3
float4 Color : COLOR;
};
VertexOut VS(VertexIn vin)
{
VertexOut vout;
vout.PosH = mul(float4(vin.PosL, 1.f), gWorldViewProj);
vout.color = vin.color;
return vout;
}代码中Pos后跟的字母,大概能猜测出其意思:(当然,变量名是可自定义的)
PosL -- Local Space 局部空间
PosW -- World Space 世界空间
PosH -- Homogenous Space 齐次空间
其中常量缓冲区中常量名前加g,可能代表GPU
顶点数据与输入签名不需要完全匹配,但是我们一定要向顶点着色器提供其输入签名所定义的顶点数据。顶点数据可以额外附带一些冗余数据(VS用不到的)。-- 换句话说,保证VS输入签名中的数据一定能从顶点数据中获取。
※另外,顶点着色器输入签名中数据的类型不一定要和与其对应的顶点数据类型一致。类型不一致也是合法的,D3D会对输入寄存器中数据类型进行重新加以解释。然而VC++调试窗口还是会给出警告。
5.Pixel Shader(PS) -- 像素着色器:
为了计算出三角形中每个像素的属性,我们会在光栅化处理阶段对VS(或几何着色器)输出的顶点属性进行插值,这些插值数据会传入像素着色器作为输入。
像素着色器的任务是给每个像素片段计算出一个对应的颜色。注意,像素着色器以像素片段作为输入数据,但这些像素片段可能最终不会留存在后台缓冲区中。例如,像素片段可能在PS中被裁剪掉了(HLSL中内置了clip函数,可以使像素片段在后续的处理流程中被忽略掉)、或者被深度值较小的片段所覆盖等等。-- 所以要区分像素片段和像素
由于硬件优化的问题,某些像素片段在移送至像素着色器之前,可能已经被渲染流水线所剔除(提前深度剔除) -- 提前深度剔除可以让不符合的像素片段不被像素着色器处理。但有一种情况是像素着色器会修改像素的深度值,所以PS需要对每个像素执行一遍。
上面示例加上PS的代码:
cbuffer cbPerObject : register(b0)
{
float4x4 gWorldViewProj;
};
void VS(
float3 iPosL : POSITION,
float4 iColor : COLOR,
out float3 oPosH : SV_POSITION,
out float4 oColor : COLOR
){
oPosH = mul(float4(iPosL, 1.f), gWorldViewProj);
oColor = iColor;
}
float4 PS(float4 posH : SV_POSITION, float4 color : COLOR ) : SV_Target
{
return color;
}像素着色器返回一个4D颜色值,而位于此函数参数列表后的SV_Target语义则表示返回值的类型应当与渲染目标格式(render target format)相匹配,该输出值会被存于渲染目标之中
将输入签名和输出参数封装进结构体的方法改写上面函数:
cbuffer cbPerObject : register(b0)
{
float4x4 gWorldViewProj;
};
struct VertexIn{
float3 Pos : POSITION;
float4 Color : COLOR;
};
struct VertexOut{
float4 Pos : SV_POSITION;
float4 Color : COLOR;
};
VertexOut VS(VertexIn vin)
{
VertexOut vout;
vout.Pos = mul(float4(vin.Pos, 1.f), gWorldViewProj);
vout.Color = vin.Color;
return vout;
}
float4 PS(VertexOut vout) : SV_Target
{
return vout.Color;
}6.常量缓冲区:
①创建常量缓冲区:
常量缓冲区是一种GPU资源(ID3D12Resource),其内容可供着色器程序所引用
cbuffer cbPerObject : register(b0)
{
float4x4 gWorldViewProj;
};cbuffer对象(常量缓冲区)的名称为cbPerObject
与顶点缓冲区和索引缓冲区不同的是,常量缓冲区通常由CPU每帧更新一次,所以我们会把常量缓冲区创建到一个上传堆而非默认堆中,这样做能使我们从CPU端更新常量
常量缓冲区对硬件有特别的要求,常量缓冲区的大小必为硬件最小分配空间(256B)的整数值
我们经常需要用到多个相同类型的常量缓冲区,假设常量缓冲区cbPerObject内存储的是随不同物体而异的常量数据,因此,我们绘制n个物体,需要n个该类型的常量缓冲区。下列代码,展示了我们如何创建一个缓冲区资源,并利用它来存储NumElements个常量缓冲区:
struct ObjectConstants
{
DirectX::XMFLOAT4X4 WorldViewProj = MathHelper::Identity4x4();
};
// d3dUtil内的工具函数: return(byteSize+255)&~255;
UINT mElementByteSize = d3dUtil::CalcConstantBufferByteSize(sizeof(ObjectConstants));
ComPtr<ID3D12Resouce> mUploadCBuffer;
device->CreateCommittedResouce(
&CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_UPLOAD), // 直接使用上传堆
D3D12_HEAP_FLAG_NONE,
&CD3DX12_RESOURCE_DESC::Buffer(mElementByteSize * NumElements), // NumElements个常量缓冲区的大小
nullptr,
IID_PPV_ARGS(&mUploadCBuffer)
);我们可以认为mUploadCBuffer中存储了一个ObjectConstants类型的常量缓冲区数组(同时按照256B的整数倍来填充数据)。待到绘制物体的时候,只要将常量缓冲区视图(CBV)绑定到存有物体相应常量数据的缓冲区子区域即可。
我们无需为HLSL结构体中显示填充相应的常量数据,这是因为它会暗中完成这项工作 -- 我们也可以手动填充避免其隐式填充
cbuffer cbPerObject : register(b0)
{
float4x4 gWorldViewProj;1
};
cbuffer cbPerObject : register(b0)
{
float4x4 gWorldViewProj;
float4x4 Pad0;
float4x4 Pad1;
float4x4 Pad2;
};
// 1个float对应4个字节 16个float:64B 所以256B = 4*float4x4随D3D12一同推出的着色器模型(shader model)5.1。其中引进一条可用于定义常量缓冲区的HLSL语法,它的使用方法如下:
// HLSL:
struct ObjectConstants
{
float4x4 gWorldViewProj;
uint matIndex;
};
ConstantBuffer<ObjectConstants> gObjConstants : register(b0);我们将常量缓冲区的数据元素封装在一个结构体中,再用结构体来创建常量缓冲区。好处就是,获取数据元素的语法不同了:
uint index = gObjConstants.matIndex;
// 原来是直接使用matIndex②更新常量缓冲区:
因为是上传堆,所以我们能通过CPU为常量缓冲区资源更新数据
ComPtr<ID3D12Resource> mUploadBuffer;
BYTE* mMappedData = nullptr;
mUploadBuffer->Map(0, nullptr, reinterpret_cast<void**>(&mMappedData));
// 第一个参数:子资源索引 对于缓冲区,本身就是唯一的子资源,所以设置为0
// 第二个参数:可选项,内存的映射范围(nullptr:整个资源进行映射)
// 第三个参数:借助双重指针,返回待映射资源数据的目标内存块
memcpy(mMappedData, &data, dataSizeInBytes); // 将数据从系统内存(CPU端)复制到常量缓冲区
// 更新完后,释放映射内存之前对其进行Unmap操作:
if(mUploadBuffer != nullptr)
mUploadBuffer->Unmap(0, nullptr);
mMappedData = nullptr;③上传缓冲区辅助函数:
将上传缓冲区的相关操作简单地封装一下,会使用起来更方便。我们在UploadBuffer.h文件中定义了以下类。它替我们实现了上传缓冲区资源的构造与析构函数、处理资源的映射和取消映射操作,还提供了CopyData方法来更新缓冲区中的元素。在需要通过CPU修改上传缓冲区中的数据的时候,便可以使用CopyData。此类可用于各种类型的上传缓冲区,而非只针对常量缓冲区。当用此类管理常量缓冲区时,我们就需要通过构造函数参数isConstantBuffer来对此加以描述。另外,如果此类中存储的是常量缓冲区,那么其中的构造函数将自动填充内存,是常量缓冲区大小成为256B的整数倍。
template<typename T> // T是缓冲区对应的结构体类型
class UploadBuffer
{
public:
UploadBuffer(ID3D12Device* device, UINT elementCount, bool isConstantBuffer) :
mIsConstantBuffer(isConstantBuffer)
{
mElementByteSize = sizeof(T);
// typedef struct D3D12_CONSTANT_BUFFER_VIEW_DESC {
// UINT64 OffsetInBytes; // multiple of 256
// UINT SizeInBytes; // multiple of 256
// } D3D12_CONSTANT_BUFFER_VIEW_DESC;
// 常量缓冲区大小为256B的整数倍
if(isConstantBuffer)
mElementByteSize = d3dUtil::CalcConstantBufferByteSize(sizeof(T));
ThrowIfFailed(device->CreateCommittedResource(
&CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_UPLOAD),
D3D12_HEAP_FLAG_NONE,
&CD3DX12_RESOURCE_DESC::Buffer(mElementByteSize*elementCount),
D3D12_RESOURCE_STATE_GENERIC_READ,
nullptr,
IID_PPV_ARGS(&mUploadBuffer)));
ThrowIfFailed(mUploadBuffer->Map(0, nullptr, reinterpret_cast<void**>(&mMappedData)));
// 只要还会修改当前的资源,我们就无须取消映射
// 但是,在资源被GPU使用期间,我们千万不可向资源进行写操作
}
UploadBuffer(const UploadBuffer& rhs) = delete;
UploadBuffer& operator=(const UploadBuffer& rhs) = delete;
~UploadBuffer()
{
if(mUploadBuffer != nullptr)
mUploadBuffer->Unmap(0, nullptr);
mMappedData = nullptr;
}
ID3D12Resource* Resource()const
{
return mUploadBuffer.Get();
}
void CopyData(int elementIndex, const T& data)
{
memcpy(&mMappedData[elementIndex*mElementByteSize], &data, sizeof(T));
}
private:
Microsoft::WRL::ComPtr<ID3D12Resource> mUploadBuffer;
BYTE* mMappedData = nullptr;
UINT mElementByteSize = 0;
bool mIsConstantBuffer = false;
};④常量缓冲区描述符:
常量缓冲区描述符需要放在D3D12_DESCRIPTOR_HEAP_TYPE_CBV_SRV_UAV类型所建的描述符堆里。这种堆内可以混合存储常量缓冲区描述符、着色器资源描述符和无序访问描述符。
void BoxApp::BuildDescriptorHeaps()
{
D3D12_DESCRIPTOR_HEAP_DESC cbvHeapDesc;
cbvHeapDesc.NumDescriptors = 1;
cbvHeapDesc.Type = D3D12_DESCRIPTOR_HEAP_TYPE_CBV_SRV_UAV;
cbvHeapDesc.Flags = D3D12_DESCRIPTOR_HEAP_FLAG_SHADER_VISIBLE; // 与RTV和DSV类型,但这里不同,设置为visible
cbvHeapDesc.NodeMask = 0;
// ComPtr<ID3D12DescriptorHeap> mCbvHeap
ThrowIfFailed(md3dDevice->CreateDescriptorHeap(&cbvHeapDesc,
IID_PPV_ARGS(&mCbvHeap)));
}通过填写D3D12_CONSTANT_BUFFER_VIEW_DESC实例,再调用ID3D12Device::CreateConstantBufferView方法,便可创建常量缓冲区
void BoxApp::BuildConstantBuffers()
{
mObjectCB = std::make_unique<UploadBuffer<ObjectConstants>>(md3dDevice.Get(), 1, true); // 第二个参数:1个同类型的常量缓冲区 第三个参数:常量缓冲区:true
UINT objCBByteSize = d3dUtil::CalcConstantBufferByteSize(sizeof(ObjectConstants));
// 缓冲区的起始地址(索引为0的那个常量缓冲区的地址)
D3D12_GPU_VIRTUAL_ADDRESS cbAddress = mObjectCB->Resource()->GetGPUVirtualAddress();
// 偏移到常量缓冲中绘制第i个物体所需的常量数据
int boxCBufIndex = i;
cbAddress += boxCBufIndex*objCBByteSize;
D3D12_CONSTANT_BUFFER_VIEW_DESC cbvDesc;
cbvDesc.BufferLocation = cbAddress;
cbvDesc.SizeInBytes = d3dUtil::CalcConstantBufferByteSize(sizeof(ObjectConstants));
md3dDevice->CreateConstantBufferView(
&cbvDesc, // const D3D12_CONSTANT_BUFFER_VIEW_DESC* 指针
mCbvHeap->GetCPUDescriptorHandleForHeapStart()); // 该句柄表示保存常量缓冲区视图的堆的开始
}⭐注意:CreateConstantBufferView中cbvDesc参数不是数组,也就是说一次调用只能创建一个常量缓冲区,要创建多个缓冲区需要偏移句柄并多次调用。
⑤根签名和描述符表:
在绘制调用开始之前,我们将不同的着色器程序所需的各种类型的资源绑定到渲染流水线上。实际上,不同类型的资源会被绑定到特定的寄存器槽(register slot)上,以供着色器访问。
b0 b1 b... 常量缓冲区
t0 t1 t... 纹理
s0 s1 s... 采样器
根签名:在执行绘制命令之前,那些应用程序将绑定到渲染流水线上的资源,它们会被映射到着色器的对应输入寄存器。根签名一定要与着色器相兼容,在创建PSO流水线状态对象时会对此进行验证。
在D3D中,根签名由ID3D12RootSignature接口来表示,并以一组描述绘制调用过程中着色器所需资源的根参数定义而成。根参数可以是根常量、根描述符、描述符表。
描述符表指定的是描述符堆中存有描述符的一块连续区域。
void BoxApp::BuildRootSignature()
{
// 根参数数组
CD3DX12_ROOT_PARAMETER slotRootParameter[1];
// 创建一个描述符表
CD3DX12_DESCRIPTOR_RANGE cbvTable;
cbvTable.Init(D3D12_DESCRIPTOR_RANGE_TYPE_CBV,
1, // 表中的描述符数量
0); // 将这段描述符区域绑定到此基准着色器寄存器 - 此处为b0
slotRootParameter[0].InitAsDescriptorTable(
1, // 描述符区域的数量
&cbvTable); // 指向描述符区域的指针
// 根签名由一组根参数构成
CD3DX12_ROOT_SIGNATURE_DESC rootSigDesc(
1, // 根签名中根参数的个数
slotRootParameter, 0, nullptr,
D3D12_ROOT_SIGNATURE_FLAG_ALLOW_INPUT_ASSEMBLER_INPUT_LAYOUT);
// 创建一个含一个槽位的根签名(该槽位指向一个仅有单个常量缓冲区组成的描述符区域)
ComPtr<ID3DBlob> serializedRootSig = nullptr;
ComPtr<ID3DBlob> errorBlob = nullptr;
HRESULT hr = D3D12SerializeRootSignature(&rootSigDesc, D3D_ROOT_SIGNATURE_VERSION_1,
serializedRootSig.GetAddressOf(), errorBlob.GetAddressOf());
if(errorBlob != nullptr)
{
::OutputDebugStringA((char*)errorBlob->GetBufferPointer());
}
ThrowIfFailed(hr);
ThrowIfFailed(md3dDevice->CreateRootSignature(
0,
serializedRootSig->GetBufferPointer(),
serializedRootSig->GetBufferSize(),
IID_PPV_ARGS(&mRootSignature)));
}根签名只定义了应用程序要绑定到渲染流水线的资源,却没有真正地执行任何资源绑定操作。只要率先通过命令列表设置好根签名,我们就能用ID3D12GraphicsCommandList::SetGraphicsRootDescriptorTable方法令描述符表与渲染流水线相绑定
void ID3D12GraphicsCommandList::SetGraphicsRootDescriptorTable(
UINT RootParameterIndex, // 将根参数按此索引(欲绑定到的寄存器槽号)进行设置
D3D12_GPU_DESCRIPTOR_HANDLE BaseDescriptor // 此参数指定的是将要相着色器绑定的描述符表中第一个描述符位于描述符堆中的句柄。比如说,如果根签名指明当前描述符表中共有5个描述符,则堆中的BaseDescriptor及其后面的4个描述符将被设置到此描述符表中
);下面代码先将根签名和CBV堆设置到命令队列上,并随后再通过设置描述符表来指定我们希望绑定到渲染流水线的资源:
// 绑定根签名
mCommandList->SetGraphicsRootSignature(mRootSignature.Get());
// 绑定CBV堆
ID3D12DescriptorHeap* descriptorHeaps[] = { mCbvHeap.Get() };
mCommandList->SetDescriptorHeaps(_countof(descriptorHeaps), descriptorHeaps);
// 偏移到此次绘制调用所需的CBV处:
CD3DX12_GPU_DESCRIPTOR_HANDLE cbv(mCbvHeap->GetGPUDescriptorHandleForHeapStart());
cbv.Offset(cbvIndex, mCbvSrvUavDescriptorSize); // cbvIndex:物体索引
mCommandList->SetGraphicsRootDescriptorTable(0, cbv);注意:如果更改了根签名,则会失去现存所有的绑定关系。也就是说,修改根签名之后,我们需要按新的根签名定义重新将所有的对应资源绑定到渲染流水线上。
7.编译着色器:
在D3D中,shader程序必须被编译为一种可移植的字节码。接下来,图形驱动程序将获取这些字节码,并将其重新编译为针对当前系统GPU所优化的本地指令[ATI1]。我们可以在运行期间用以下函数对着色器进行编译:
HRESULT D3DCompileFromFile(
LPCWSTR pFileName,
const D3D_SHADER_MACRO *pDefines,
ID3DInclude *pInclude,
LPCSTR pEntrypoint,
LPCSTR pTarget,
UINT Flags1,
UINT Flags2,
ID3DBlob **ppCode,
ID3DBlob **ppErrorMsgs
);
// pFileName:
HLSL源文件名
// pDefines:
高级功能,本书不使用,常设置为nullptr
// pInclude:
高级功能,本书不使用,常设置为nullptr
// pEntrypoint:
着色器的入口点函数名,一个.hlsl文件中可能存有多个着色器程序(比如一个VS一个PS),我们需要为待编译的着色器指定入口点
// pTarget:
指定所用的着色器类型和版本的字符串 -- 不同版本其内置函数与数据结构不同
本书采用的着色器模型版本为5.0和5.1,比如:
VS: vs_5_0和vs_5_1 PS: ps_5_0和ps_5_1
// Flags1:
对着色器代码应该如何编译的标志,比如:
D3DCOMPILE_DEBUG 调试模式来编译着色器
D3DCOMPILE_SKIP_OPTIMIZATION 指示调试器跳过优化阶段(对调试很有用)
// Flags2:
高级编译选项
// ppCode:
返回一个指向ID3DBlob数据结构的指针,存储编译好的着色器对象字节码
// ppErrirMsgs:
返回一个指向ID3DBlob数据结构的指针,如果在编译过程中发生了错误,它便会存储报错的字符串ID3DBlob类型描述的其实就是一段普通的内存块,这是该接口的两个方法:
①LPVOID GetBufferPointer:返回指向ID3DBlob对象中数据的void*类型的指针
②SIZE_T GetBufferSize:返回缓冲区的字节大小(即对象中数据大小)
为了能够输出错误信息,我们在d3dUtil.h/.cpp文件中实现了下列辅助函数在运行时编译着色器:
ComPtr<ID3DBlob> d3dUtil::CompileShader(
const std::wstring& filename,
const D3D_SHADER_MACRO defines,
const std::string& entrypoint,
const std::string& target
)
{
// 若处于调试模式,则使用调试标志
UINT compileFlags = 0;
#if defined(DEBUG) || defined(_DEBUG)
compileFlags = D3DCOMPILE_DEBUG | D3DCOMPILE_SKIP_OPTIMIZATION;
#endif
HRESULT hr = S_OK;
ComPtr<ID3DBlob> byteCode = nullptr;
ComPtr<ID3DBlob> errors;
hr = D3DCompileFromFile(filename.c_str(), defines,
D3D_COMPILE_STANDARD_FILE_INCLUDE,
entrypoint.c_str(), target.c_str(), compileFlags, 0, &byteCode,
&errors
);
// 将错误信息输出到调试窗口
if(errors != nullptr)
OutputDebugStringA((char*)errors->GetBufferPointer());
ThrowIfFailed(hr);
return byteCode;
}以下是调用此函数的示例:
ComPtr<ID3DBlob> mvsByteCode = nullptr;
ComPtr<ID3DBlob> mpsByteCode = nullptr;
mvsByteCode = d3dUtil::CompileShader(L"Shaders\\color.hlsl",
nullptr, "VS", "vs_5_0");
mpsByteCode = d3dUtil::CompileShader(L"Shaders\\color.hlsl",
nullptr, "PS", "ps_5_0");仅对着色器进行编译并不会将它与渲染流水线相绑定以供其使用,我们会在6.9节中介绍相关的做法。
1️⃣离线编译:
我们不仅可以在运行期间编译着色器,还能够从单独的步骤离线地编译着色器,这样的好处有:①对于复杂的着色器,其编译过程可能耗时较长②早于运行时发现编译错误③windows8应用中的应用而言,必须采用离线编译这种方式
我们通常用.cso即compiled shader object(已编译着色器对象)作为已编译着色器的扩展名
为了以离线的方式编译着色器,我们将使用DirectX自制的FXC命令行编译工具。
⭐fxc.exe的具体位置:C:\Program Files (x86)\Windows Kits\10\bin\10.0.19041.0\x64\fxc.exe -- 进入该目录后使用cmd命令行
①为了将color.hlsl文件中分别以VS和PS作为入口点的顶点着色器和像素着色器编译为调试版本的字节码,我们可以输入以下命令:
fxc "color.hlsl" /Od /Zi /T vs_5_0 /E "VS" /Fo "color_vs.cso" /Fc "color_vs.asm"
fxc "color.hlsl" /Od /Zi /T ps_5_0 /E "PS" /Fo "color_ps.cso" /Fc "color_ps.asm"②为了将color.hlsl文件中分别以VS和PS作为入口点的顶点着色器和像素着色器编译为发行版本的字节码,我们可以输入以下命令:
fxc "color.hlsl" /T vs_5_0 /E "VS" /Fo "color_vs.cso" /Fc "color_vs.asm"
fxc "color.hlsl" /T ps_5_0 /E "PS" /Fo "color_ps.cso" /Fc "color_ps.asm"FXC命令行参数及其作用:
/Od 禁止优化(对调试十分有用)
/Zi 开启调试信息
/T <string> 着色器类型和着色器模型的版本
/E <string> 着色器入口点
/Fo <string> 经过编译的着色器对象字节码
/Fc <string> 输出一个着色器的汇编文件清单(对于调试、检验指令数量、查阅生成的代码细节都是很有帮助的)
不再需要调用D3DCompileFromFile方法,但生成的.cso文件需要通过C++的文件输入机制加载到应用程序中
ComPtr<ID3DBlob> d3dUtil::LoadBinary(const std::wstring& filename)
{
std::ifstream fin(filename, std::ios::binary);
fin.seekg(0, std::ios_base::end);
std::ifstream::pos_type size = (int)fin.tellg();
fin.seekg(0, std::ios_base::beg);
ComPtr<ID3DBlob> blob;
ThrowIfFailed(D3DCreateBlob(size, blob.GetAddressOf()));
fin.read((char*)blob->GetBufferPointer(), size);
return blob;
}
...
ComPtr<ID3DBlob> mvsByteCode = d3dUtil::LoadBinary(L"Shaders\\color_vs.cso");
ComPtr<ID3DBlob> mpsByteCode = d3dUtil::LoadBinary(L"Shaders\\color_ps.cso");2️⃣生成着色器汇编代码:
FXC程序根据可选参数/Fc来生成可移植的着色器代码,通过查询着色器的汇编代码,即可核对着色器的指令数量,也能了解生成代码细节。
考虑这种情况,GPU可编程初期阶段,着色器中使用分支指令(if else)的代价是比较高昂的,编译器往往会对两个分支都进行求值,最后通过求值结果进行插值整理条件语句。
查看着色器汇编代码的目的是为了弄清楚它到底做了什么。
3️⃣利用Visual Studio离线编译着色器:
我们可以向工程中添加.hlsl文件,而visual studio会识别它们并提供编译的选项,从UI中配置的选项其实就是FXC的参数。但是,使用Visual Studio集成的HLSL工具有一个缺点,它只允许每个文件中仅有一个着色器程序,比如一个hlsl文件中VS和PS不能同时存在,每个.hlsl文件只能输出一个.cso文件。
8.光栅器状态:
当今渲染流水线中的大多阶段都是可编程的,但是有些特定环节只能接收配置。例如,用于配置渲染流水线中光栅化阶段的光栅化状态组由结构体D3D12_RASTERIZER_DESC来表示:
typedef struct D3D12_RASTERIZER_DESC {
// 右侧注释都为默认值
D3D12_FILL_MODE FillMode; // D3D12_FILL_MODE_SOLID
D3D12_CULL_MODE CullMode; // D3D12_CULL_MODE_BACK
BOOL FrontCounterClockwise; // false
INT DepthBias; // 0
FLOAT DepthBiasClamp; // 0.f
FLOAT SlopeScaledDepthBias; // 0.f
BOOL DepthClipEnable; // true
BOOL MultisampleEnable; // false
BOOL AntialiasedLineEnable; // false
UINT ForcedSampleCount; // 0
D3D12_CONSERVATIVE_RASTERIZATION_MODE ConservativeRaster; // D3D12_CONSERVATIVE_RASTERIZATION_MODE_OFF
} D3D12_RASTERIZER_DESC;
// 其中参数大部分都是相对高级或不常用的成员,我们只对其中关键的3个成员进行讲解
// FillMode:
D3D12_FILL_MODE_WIREFRAME 采用线框模式进行渲染
D3D12_FILL_MODE_SOLID 使用实体模式进行渲染(默认)
// CullMode:
D3D12_CULL_MODE_NONE 禁止剔除操作
D3D12_CULL_MODE_BACK 背面剔除
D3D12_CULL_MODE_FRONT 正面剔除
// FrontCounterClockwise:
false:根据摄像机视角,将顶点顺序为顺时针方向的三角形看作正面朝向(默认) -- true则相反
代码示例:创建一个开启线框模式,且背面剔除的光栅化状态:
CD3DX12_RASTERIZER_DESC rsDesc(D3D12_DEFAULT);
rsDesc.FillMode = D3D12_FILL_MODE_WIREFRAME;
rsDesc.CullMode = D3D12_CULL_MODE_NONE;
/*
CD3DX12_RASTERIZER_DESC提供一个接收CD3DX12_DEFAULT作为参数来创建光栅化状态对象的构造函数
CD3DX12_DEFAULT只是一个哑类型,而此函数的作用是将光栅化状态中需要被初始化的成员重载为默认值
*/
// CD3DX12_DEFAULT和D3D12_DEFAULT的定义如下:
// struct CD3DX12_DEFAULT {};
// extern const DECLSPEC_SELECTANY CD3DX12_DEFUALT D3D12_DEFAULT;
// 这两个被广泛应用于Direct3D的其他几个工具类中9.流水线状态对象:Pipeline State Object -- PSO
到目前为止,我们已经展示了编写输入布局描述、创建VS和PS,以及配置光栅器状态组这3个步骤,但还未曾讲解如何将这些对象绑定到图形流水线上,用以实际绘制图形。
大多数控制图形流水线状态的对象被统称为PSO,用ID3D12PipelineState接口来表示。要创建PSO,我们首先要填写一份描述其细节的D3D12_GRAPHICS_PIPELINE_STATE_DESC结构体示例:
typedef struct D3D12_GRAPHICS_PIPELINE_STATE_DESC
{
ID3D12RootSignature *pRootSignature;
D3D12_SHADER_BYTECODE VS;
D3D12_SHADER_BYTECODE PS;
D3D12_SHADER_BYTECODE DS;
D3D12_SHADER_BYTECODE HS;
D3D12_SHADER_BYTECODE GS;
D3D12_STREAM_OUTPUT_DESC StreamOutput;
D3D12_BLEND_DESC BlendState;
UINT SampleMask;
D3D12_RASTERIZER_DESC RasterizerState;
D3D12_DEPTH_STENCIL_DESC DepthStencilState;
D3D12_INPUT_LAYOUT_DESC InputLayout;
D3D12_PRIMITIVE_TOPOLOGY_TYPE PrimitiveTopologyType;
UINT NumRenderTargets;
DXGI_FORMAT RTVFormats[8];
DXGI_FORMAT DSCFormat;
DXGI_SAMPLE_DESC SampleDesc;
} D3D12_GRAPHICS_PIPELINE_STATE_DESC; // 书中并未对此结构的参数完全介绍
// pRootSignature:
指向一个与此PSO相绑定的根签名的指针。该根签名一定要与此PSO指定的着色器相兼容。
// VS PS DS HS GS:
typedef struct D3D12_SHADER_BYTECODE {
const void *pShaderBytecode; // 已编译好的字节码数据的指针
SIZE_T BytecodeLength; // 子节目数据所占的字节大小
} D3D12_SHADER_BYTECODE;
// StreamOutput:
用于作为一种作为流输出的高级技术,目前我们将此段清零
// BlendState:
blending操作所用的混合状态,目前指定为默认的CD3DX12_BLEND_DESC(D3D12_DEFAULT)
// SampleMask:
多重采样最多可采集32个样本,借助此参数的32位整数值,一位控制一个样本的采集情况
比如禁止采取第5个样本,则将第五位设置为0
当然,要禁用第5位的先决条件是,多重采样至少有5个样本
假设一个应用程序仅使用了单采样,那么只能针对该参数的第一位设置
一般来说,使用的默认值都是0xffffffff,表示对所有的采样点都进行采样
// RasterizerState:
光栅器状态
// DepthStencilState:
深度模板状态 目前设置为默认的CD3DX12_DEPTH_STENCIL_DESC(D3D12_DEFAULT)
// InputLayout:
输入布局
// PrimitiveTopology:
图元拓扑
// NumRenderTargets:
同时所用的渲染目标数量(即RTVFormats数组中渲染目标格式的数量)
// DSVFormat:
深度模板缓冲区的格式,使用此PSO的深度模板缓冲区的格式设定应当与该参数相匹配
// SampleDesc:
采样数量和质量级别的结构
在D3D12_GRAPHICS_PIPELINE_DESC实例填写完毕后,我们可用ID3D12Device::CreateGraphicsPipelineState方法来创建ID3D12PipelineState对象
ComPtr<ID3D12RootSignature> mRootSignature;
std::vector<D3D12_INPUT_ELEMENT_DESC> mInputLayout;
ComPtr<ID3DBlob> mvsByteCode;
ComPtr<ID3DBlob> mpsByteCode;
...
D3D12_GRAPHICS_PIPELINE_STATE_DESC psoDesc;
ZeroMemory(&psoDesc, sizeof(D3D12_GRAPHICS_PIPELINE_STATE_DESC));
psoDesc.InputLayout = { mInputLayout.data(), (UINT)mInputLayout.size() };
psoDesc.pRootSignature = mRootSignature.Get();
psoDesc.VS =
{
reinterpret_cast<BYTE*>(mvsByteCode->GetBufferPointer()),
mvsByteCode->GetBufferSize()
};
psoDesc.PS =
{
reinterpret_cast<BYTE*>(mpsByteCode->GetBufferPointer()),
mpsByteCode->GetBufferSize()
};
psoDesc.RasterizerState = CD3DX12_RASTERIZER_DESC(D3D12_DEFAULT);
psoDesc.BlendState = CD3DX12_BLEND_DESC(D3D12_DEFAULT);
psoDesc.DepthStencilState = CD3DX12_DEPTH_STENCIL_DESC(D3D12_DEFAULT);
psoDesc.SampleMask = UINT_MAX;
psoDesc.PrimitiveTopologyType = D3D12_PRIMITIVE_TOPOLOGY_TYPE_TRIANGLE;
psoDesc.NumRenderTargets = 1;
psoDesc.RTVFormats[0] = mBackBufferFormat;
psoDesc.SampleDesc.Count = m4xMsaaState ? 4 : 1;
psoDesc.SampleDesc.Quality = m4xMsaaState ? (m4xMsaaQuality - 1) : 0;
psoDesc.DSVFormat = mDepthStencilFormat;
ThrowIfFailed(md3dDevice->CreateGraphicsPipelineState(&psoDesc, IID_PPV_ARGS(&mPSO)));
ID3D12PipelineState对象集合了大量的流水线状态信息。为了保证性能,我们将所有这些对象都集总在一起,一并送至渲染流水线。通过这样一个集合,D3D便可以确定所有的状态是否彼此兼容,而驱动程序能够据此而提前生成硬件本地指令及其状态。
※在D3D11的状态模型中,这些渲染状态片段都是要分开配置的。然而这些状态实际都有一定的联系,以致如果其中的一个状态发生改变,那么驱动程序可能就要为了另一个相关的独立状态而对硬件重新进行编程。由于一些状态在配置流水线时需要改变,因而硬件状态也就可能被频繁的改写。为了避免这些冗余的操作,驱动程序往往会推迟针对硬件状态的编程动作,直到明确整条流水线的状态发起绘制调用后,才正式生成对应的本地指令与状态。但是,这种延迟操作需要驱动在运行时进行额外的记录工作,即追随状态的变化,而后才能在运行时生成改写硬件状态的本地代码。
在Direct3D 12的新模型中,驱动程序可以在初始化期间生成流水线状态编程的全部代码,这便是我们将大多数的流水线状态指定为一个集合而带来的好处。
由于PSO的验证和创建操作过于耗时,所以应在初始化期间就生成PSO。除非有特别的需求,比如,在运行时创建PSO伊始就要立即对它进行第一次引用的这种情况。随后,我们就可以将它存于如散列表(哈希表)这样的集合里,以便在后续使用时快速获取。
并非所有的渲染状态都封装于PSO内,如视口和裁剪矩形等属性就独立于PSO。由于这些状态的设置与其他的流水线状态分隔开来会更有效,所以把它们强行集中在PSO内也并不会为之增添任何优势。
D3D实质上就是一种状态机,里面的事物会保持它们各自的状态,直到我们将其改变。如果我们以不同的PSO去绘制不同的物体,需要像下面那样来组织代码:
// 重置命令列表并指定初始PSO
mCommandList->Reset(mDirectCmdListAlloc.Get(), mPSO1.Get());
/* --- 使用PSO 1绘制物体 --- */
// 改变PSO
mCommandList->SetPipelineState(mPSO2.Get());
/* --- 使用PSO 2绘制物体 --- */
// 改变PSO
mCommandList->SetPipelineState(mPSO3.Get());
/* --- 使用PSO 3绘制物体 --- */
只要把一个PSO与命令列表相绑定,那么,在我们设置另一个PSO或重置命令列表之前,会一直沿用当前的PSO绘制物体
考虑到程序的性能问题,我们应当尽可能减少改变PSO状态的次数。为此,若能以一个PSO绘制出所有的物体,绝不用第二个PSO。切记,不要在每次绘制调用时都修改PSO!
10.几何图形辅助结构体:
在本书中,我们通过创建一个同时存有顶点缓冲区和索引缓冲区的结构体来方便地定义多个几何体。另外,借此结构体即可将顶点和索引数据置于系统内存之中,以供CPU读取。该结构体还缓存了顶点缓冲区和索引缓冲区的一些重要属性,并提供返回缓冲区视图的方法。
MeshGeometry结构体定义于d3dUtil.h头文件中:
// 利用SubmeshGeometry来定义MeshGeometry中存储的单个几何体
// 此结构体适用于将多个几何体数据存于一个顶点缓冲区和一个索引缓冲区
// 该结构提供单个几何体进行绘制所需要的数据和偏移量
struct SubmeshGeometry
{
UINT IndexCount = 0;
UINT StartIndexLocation = 0;
INT BaseVertexLocation = 0;
// bounding box在此定义,后续章节会用到此数据
DirectX::BoundingBox Bounds;
};
struct MeshGeometry
{
// 指定此几何体网络集合的名称,我们通过名称来找到它
std::string Name;
// 系统内存副本,由于顶点/索引可以是泛型格式(具体格式依用户而定),所以用Blob类型来表示待用户在使用时再将其转换为适当的类型
Microsoft::WRL::ComPtr<ID3DBlob> VertexBufferCPU = nullptr;
Microsoft::WRL::ComPtr<ID3DBlob> IndexBufferCPU = nullptr;
Microsoft::WRL::ComPtr<ID3D12Resource> VertexBufferGPU = nullptr;
Microsoft::WRL::ComPtr<ID3D12Resource> IndexBufferGPU = nullptr;
Microsoft::WRL::ComPtr<ID3D12Resource> VertexBufferUploader = nullptr;
Microsoft::WRL::ComPtr<ID3D12Resource> IndexBufferUploader = nullptr;
// 与缓冲区相关数据 -- 顶点缓冲区和索引缓冲区desc中的成员
UINT VertexByteStride = 0;
UINT VertexBufferByteSize = 0;
DXGI_FORMAT IndexFormat = DXGI_FORMAT_R16_UINT;
UINT IndexBufferByteSize = 0;
// 一个MeshGeometry结构体能够存储一组顶点/索引缓冲区中的多个几何体
// 若利用下列容器来定义子网络几何体,我们就能单独地绘制出其中的子网络(单个几何体)
std::unordered_map<std::string, SubmeshGeometry> DrawArgs;
D3D12_VERTEX_BUFFER_VIEW VertexBufferView()const
{
D3D12_VERTEX_BUFFER_VIEW vbv;
vbv.BufferLocation = VertexBufferGPU->GetGPUVirtualAddress();
vbv.StrideInBytes = VertexByteStride;
vbv.SizeInBytes = VertexBufferByteSize;
return vbv;
}
D3D12_INDEX_BUFFER_VIEW IndexBufferView()const
{
D3D12_INDEX_BUFFER_VIEW ibv;
ibv.BufferLocation = IndexBufferGPU->GetGPUVirtualAddress();
ibv.Format = IndexFormat;
ibv.SizeInBytes = IndexBufferByteSize;
return ibv;
}
// 待数据上传至GPU后,我们就能释放上传缓冲区内存了
void DisposeUploaders()
{
VertexBufferUploader = nullptr;
IndexBufferUploader = nullptr;
}
};11.立方体演示程序:
其中部分代码的个人理解(可能不正确)~
// radian = pi * angle / 180
float mTheta = 1.5f*XM_PI; // 3pi/2
float mPhi = XM_PIDIV4; // pi/4
float mRadius = 5.0f;
// update()函数中:
float x = mRadius*sinf(mPhi)*cosf(mTheta);
float z = mRadius*sinf(mPhi)*sinf(mTheta);
float y = mRadius*cosf(mPhi);
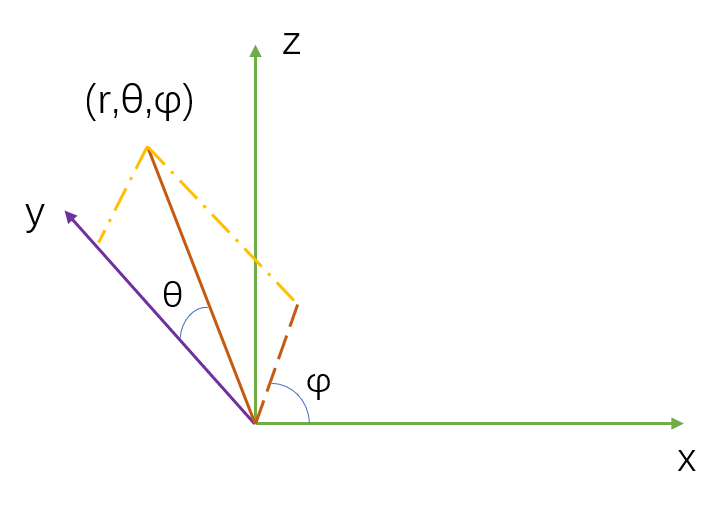
这是将坐标从球坐标系转换为直角坐标系,球坐标系中,点是由来表示的其中:
θ为天顶角,是向量与竖直向上方向之间的夹角
φ为方位角,是向量投影到水平平面内,与"+x"轴的夹角
但经过分析此坐标系的坐标轴不是以xyz的绕序展开的,在我看来为了便于理解,这个坐标系实际上应该是这么画的(考虑到摄像机,+y轴正上方,+z轴正前方):
XMVECTOR pos = XMVectorSet(x, y, z, 1.0f); // 摄像机置于世界空间的坐标
XMVECTOR target = XMVectorZero(); // 观测世界空间的原点
XMVECTOR up = XMVectorSet(0.0f, 1.0f, 0.0f, 0.0f);虽然在摄像机空间中,摄像机自己处于原点位置,但我们还需要确定这个摄像机在世界空间中的摆放位置。pos就是摄像机位于世界空间的坐标,target为摄像机的观察点。
因为我们将这个立方体的world矩阵设置为单位矩阵,所以该立方体的中心在原点位置,对称的放置在原点位置。
XMFLOAT4X4 mWorld = MathHelper::Identity4x4();12.OnMouseMove、OnMouseDown、OnMouseUp:
void BoxApp::OnMouseDown(WPARAM btnState, int x, int y)
{
mLastMousePos.x = x;
mLastMousePos.y = y;
SetCapture(mhMainWnd); // win32函数,鼠标捕获输入 -- 在鼠标悬停在捕获窗口上而按钮仍处于关闭状态时按下鼠标按钮时捕获鼠标输入
}
void BoxApp::OnMouseUp(WPARAM btnState, int x, int y)
{
ReleaseCapture(); // win32函数 -- 从当前线程中的窗口释放鼠标捕获,并恢复正常的鼠标输入处理
}
void BoxApp::OnMouseMove(WPARAM btnState, int x, int y)
{
if((btnState & MK_LBUTTON) != 0) // 左键
{
// 根据鼠标的移动距离计算旋转角度
float dx = XMConvertToRadians(0.25f*static_cast<float>(x - mLastMousePos.x));
float dy = XMConvertToRadians(0.25f*static_cast<float>(y - mLastMousePos.y));
// 根据鼠标的输入来更新摄像机绕立方体旋转的角度
mTheta += dx;
mPhi += dy;
// 限制角度mPhi的范围
mPhi = MathHelper::Clamp(mPhi, 0.1f, MathHelper::Pi - 0.1f); // 0< mphi <Π
}
else if((btnState & MK_RBUTTON) != 0) // 右键
{
// 使场景中的每个像素按鼠标移动距离的0.005倍进行缩放
float dx = 0.005f*static_cast<float>(x - mLastMousePos.x);
float dy = 0.005f*static_cast<float>(y - mLastMousePos.y);
// 根据鼠标的输入更新摄像机的可视范围半径
mRadius += dx - dy;
// 限制可视范围半径的范围
mRadius = MathHelper::Clamp(mRadius, 3.0f, 15.0f);
}
mLastMousePos.x = x;
mLastMousePos.y = y;
}
// 其中mLastMousePos:
POINT mLastMousePos; // POINT结构成员是两个long13.Update函数(利用CopyData更新上传缓冲区):
void BoxApp::Update(const GameTimer& gt)
{
// Convert Spherical to Cartesian coordinates.
// 球坐标系转换到直角坐标系
// (r,θ,φ) -- θ天顶角 竖直向上方向与该向量的夹角 φ方位角
// 明显可以看出,这是一个xzy坐标系 y竖直方向 x左右方向 z前后方向 -- 就是基于摄像机
float x = mRadius*sinf(mPhi)*cosf(mTheta);
float z = mRadius*sinf(mPhi)*sinf(mTheta);
float y = mRadius*cosf(mPhi);
// Build the view matrix.
XMVECTOR pos = XMVectorSet(x, y, z, 1.0f); // 摄像机置于世界空间的坐标
XMVECTOR target = XMVectorZero(); // 观测世界空间的原点
XMVECTOR up = XMVectorSet(0.0f, 1.0f, 0.0f, 0.0f);
XMMATRIX view = XMMatrixLookAtLH(pos, target, up);
XMStoreFloat4x4(&mView, view);
XMMATRIX world = XMLoadFloat4x4(&mWorld);
XMMATRIX proj = XMLoadFloat4x4(&mProj);
XMMATRIX worldViewProj = world*view*proj;
// Update the constant buffer with the latest worldViewProj matrix.
ObjectConstants objConstants;
XMStoreFloat4x4(&objConstants.WorldViewProj, XMMatrixTranspose(worldViewProj));
objConstants.TotalTime = gt.TotalTime();
mObjectCB->CopyData(0, objConstants);
}
遗留问题:DrawInstanced没有给定索引,是如何绘制图像的?
遗留问题2:PSO和CommandList->Set...操作,发现PSO中绑定了描述符(堆),但却在draw阶段用CommandList的set..命令去再次设置描述符,和这种情况类似的还有图元拓扑,这是为什么?
解答:(84 封私信 / 81 条消息) 为什么directX 12使用pso要比以前使用上下文切换状态更快? - 知乎 (zhihu.com)
目前而言,我的理解是,PSO封装了一系列状态转换操作,因为单个状态转换(set操作)会影响其他状态,影响性能,所以不冲突
(84 封私信 / 81 条消息) DX12 PSO PrimitiveTopologyType的相关问题? - 知乎 (zhihu.com)
其他可能的解释:
1.PSO是在device下面创建的,创建后要帮到cmdList上面,一个PSO可以给多个cmdList使用
2.PSO创建时,设置的RootSignature只是为了验证,但是创建好的pso并没有携带该RootSignature的信息,所以后续cmd还要set一次
3.by design


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









