







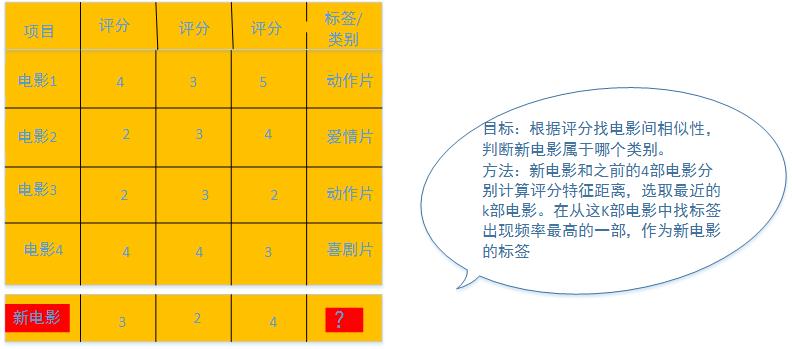
KNN(K-NearestNeighbor)是分类算法中最简单的一种,用来计算特征的相似性。以电影评分系统为例,每个电影都会有一个评分向量,每部电影也都有一个类标签-动作、爱情等。通过KNN算法可以计算出不同电影之间的评分向量的距离,以此来判断不同电影间的相似性,当有一部新电影进来时,就可以将其归为最相似电影所属的那一类。本文首先介绍KNN(K-近邻)算法的原理,然后给出其实现的伪代码,最后结合具体实例,给出java实现代码。
- KNN算法的原理:
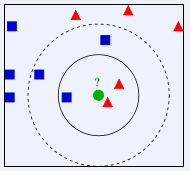
抽象为如下图像,判断“?”属于哪个类标签。首先找离它最近的k个类标签,然后看这k各类标签中哪个类别出现的频率最高,根据少数服从多数的原则,“?”就属于哪个类别。如下图,当K取4时,离其最近的4的标签是一个蓝方块,一个绿圆和两个红三角,这4各类别中红三角出现频率最高,那么“?”就应该属于红三角类别。同理,K若取5,“?”应属于蓝色方块类别。由此可见,不同的K值,会有不同的结果,我们要谨慎选择K值,可以通过交叉验证选择效果最好的K值。(李航的《统计学导论》有说明,K取小了会产生过拟合,取大了会欠拟合)
- 伪代码:
目标:判断测试数据集中的类标签。
- 计算已知类别数据集中的向量与当前向量之间的距离
- 按照距离递增次序排序
- 选取与当前点距离最小的K个点
- 确定前k个点所在类别的出现频率
- 返回前k各点中出现频率最高的类别作为当前点的预测分类。
- 可运行java代码:
package knn;
import java.util.*;
public class KNN
{
// the data
static double[][] instances = {
{0.35,0.91,0.86,0.42,0.71},
{0.21,0.12,0.76,0.22,0.92},
{0.41,0.58,0.73,0.21,0.09},
{0.71,0.34,0.55,0.19,0.80},
{0.79,0.45,0.79,0.21,0.44},
{0.61,0.37,0.34,0.81,0.42},
{0.78,0.12,0.31,0.83,0.87},
{0.52,0.23,0.73,0.45,0.78},
{0.53,0.17,0.63,0.29,0.72},
};
private static String findMajorityClass(String[] array)
{
Set<String> h = new HashSet<String>(Arrays.asList(array));//ss原先是字符串数组
String[] uniqueValues = h.toArray(new String[0]);
int[] counts = new int[uniqueValues.length];
for (int i = 0; i < uniqueValues.length; i++) {
for (int j = 0; j < array.length; j++) {
if(array[j].equals(uniqueValues[i])){
counts[i]++;
}
}
}
for (int i = 0; i < uniqueValues.length; i++)
System.out.println(uniqueValues[i]);
for (int i = 0; i < counts.length; i++)
System.out.println(counts[i]);
//考虑了出现多类别频率相同的情况,这部分是在找最大频率。
int max = counts[0];
for (int counter = 1; counter < counts.length; counter++) {
if (counts[counter] > max) {
max = counts[counter];
}
}
System.out.println("max # of occurences: "+max);
// how many times max appears
//we know that max will appear at least once in counts
//so the value of freq will be 1 at minimum after this loop
int freq = 0;
for (int counter = 0; counter < counts.length; counter++) {
if (counts[counter] == max) {
freq++;
}
}
int index = -1;
if(freq==1){
for (int counter = 0; counter < counts.length; counter++) {
if (counts[counter] == max) {
index = counter;
break;
}
}
return uniqueValues[index];//返回类别
}
else{//we have multiple modes
int[] ix = new int[freq];//array of indices of modes
System.out.println("multiple majority classes: "+freq+" classes");
int ixi = 0;
for (int counter = 0; counter < counts.length; counter++) {
if (counts[counter] == max) {
ix[ixi] = counter;//save index of each max count value
ixi++; // increase index of ix array
}
}
for (int counter = 0; counter < ix.length; counter++)
System.out.println("class index: "+ix[counter]);
//now choose one at random
Random generator = new Random();
//get random number 0 <= rIndex < size of ix
int rIndex = generator.nextInt(ix.length);
System.out.println("random index: "+rIndex);
int nIndex = ix[rIndex];
//return unique value at that index
return uniqueValues[nIndex];
}
}
public static void main(String args[]){
int k = 6;// # of neighbours
//list to save city data
List<City> cityList = new ArrayList<City>();
//list to save distance result
List<Result> resultList = new ArrayList<Result>();
// add city data to cityList
cityList.add(new City(instances[0],"London"));
cityList.add(new City(instances[1],"Leeds"));
cityList.add(new City(instances[2],"Liverpool"));
cityList.add(new City(instances[3],"London"));
cityList.add(new City(instances[4],"Liverpool"));
cityList.add(new City(instances[5],"Leeds"));
cityList.add(new City(instances[6],"London"));
cityList.add(new City(instances[7],"Liverpool"));
cityList.add(new City(instances[8],"Leeds"));
//data about unknown city
double[] query = {0.65,0.78,0.21,0.29,0.58};
//find disnaces for循环结束后,resultList里保存的是测试集到各标签的距离
for(City city : cityList){//for循环标签
double dist = 0.0;
for(int j = 0; j < city.cityAttributes.length; j++){//属性就是那些值
dist += Math.pow(city.cityAttributes[j] - query[j], 2) ;//pow的用法
//System.out.print(city.cityAttributes[j]+" ");
}
double distance = Math.sqrt( dist );
resultList.add(new Result(distance,city.cityName));//是result类型的,相当于python中的字典。java种也有字典吧
//System.out.println(distance);
}
//System.out.println(resultList);
Collections.sort(resultList, new DistanceComparator());//sort
String[] ss = new String[k];//取top-6
for(int x = 0; x < k; x++){
System.out.println(resultList.get(x).cityName+ " .... " + resultList.get(x).distance);
//get classes of k nearest instances (city names) from the list into an array
ss[x] = resultList.get(x).cityName;//要计算类别频率
}
String majClass = findMajorityClass(ss);//传递过去的是标签
System.out.println("Class of new instance is: "+majClass);
}//end main
//simple class to model instances (features + class)
static class City {
double[] cityAttributes;
String cityName;
public City(double[] cityAttributes, String cityName){
this.cityName = cityName;
this.cityAttributes = cityAttributes;
}
}
//simple class to model results (distance + class)
static class Result {
double distance;
String cityName;
public Result(double distance, String cityName){
this.cityName = cityName;
this.distance = distance;
}
}
//simple comparator class used to compare results via distances
static class DistanceComparator implements Comparator<Result> {
@Override
public int compare(Result a, Result b) {
return a.distance < b.distance ? -1 : a.distance == b.distance ? 0 : 1;
}
}
}















 385
385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









