







 本文探讨了图像溯源的关键步骤,包括使用SIFT、SURF和DELF等特征提取方法,以及如何通过几何一致性匹配和卷积神经网络构建差异矩阵。此外,还介绍了基于互信息量和元数据的边方向矩阵构造,以及最小生成树和聚类方法在构建溯源图中的应用。实验数据集和评估方法展示了各种方法在图像检索和溯源分析中的性能。
本文探讨了图像溯源的关键步骤,包括使用SIFT、SURF和DELF等特征提取方法,以及如何通过几何一致性匹配和卷积神经网络构建差异矩阵。此外,还介绍了基于互信息量和元数据的边方向矩阵构造,以及最小生成树和聚类方法在构建溯源图中的应用。实验数据集和评估方法展示了各种方法在图像检索和溯源分析中的性能。
1.引言
时值新冠肺炎疫情关键时期,大家一定要少出门,勤通风,多洗手,注意个人卫生,出门时一定要戴好口罩。让我们众志成城,打赢这场疫情攻坚战!
在这个特殊时期,有不法分子试图通过造谣来混淆公众视听,引导舆论走向,大家一定要擦亮双眼,理性客观的看待事情。其中,最常见的造谣手段就是p图。所谓“开局一张图,内容全靠编”。举个例子,前段时间不法分子造谣周杰伦乘坐隔离舱在福州出席活动,一时间引来不明真相的吃瓜群众一顿谩骂。而事实上,周杰伦当时在澳洲的娘家准备过新年。
这样的情况在国外也是数见不鲜。有证据表明,很多不法分子在16年美国总统大选期间,将p过的图在推特上传播,来影响大选结果,左右民众舆论走向。
因此,检测图像是否被篡改并找出其原图,成为国内外研究的一个热门话题。该课题被命名为图像检索和溯源(image retrieval and provenance)。
最近,我学习了这方面的好几篇论文,在此做个总结。
涉及这方面研究的几个专用名词如下:
血缘关系:对于图片a,对其进行一系列修改操作(例如:裁剪,选择,调整对比度…),得到一张新图片b。再对b进行一系列修改操作,得到一张新图片c。我们称,图片a,b,c之间存在血缘关系。即,存在修改关系的图片之间,存在血缘关系。另外,称a和b,b和c之间存在直接血缘关系。
检索(retrieval)和溯源(provenance):给定一张查询图k和一个图片集Q,找出Q中与k存在血缘关系的图片,称为检索。在检索到的图片集中,找出查询图k的原图,称为溯源。
查询图(query),主图(host),供图(donor):进行查询检索的图称为查询图。一般而言,查询图都是由多个图片合成的。这些图片中,提供查询图的大部分区域或者背景的图片称为主图。仅提供一小部分来组从查询图的图片称为供图。
溯源图:将查询图与检索到的图中,存在直接血缘关系的图对,连接起来,得到一个无向无环图,称为无向溯源图。如果能得知修改方向(即b是由a修改后得到的,则a->b),则可以得到一个有向无环图,称为有向溯源图。统称为溯源图。
下图是一个简单的例子。(配图来源于参考文献1)
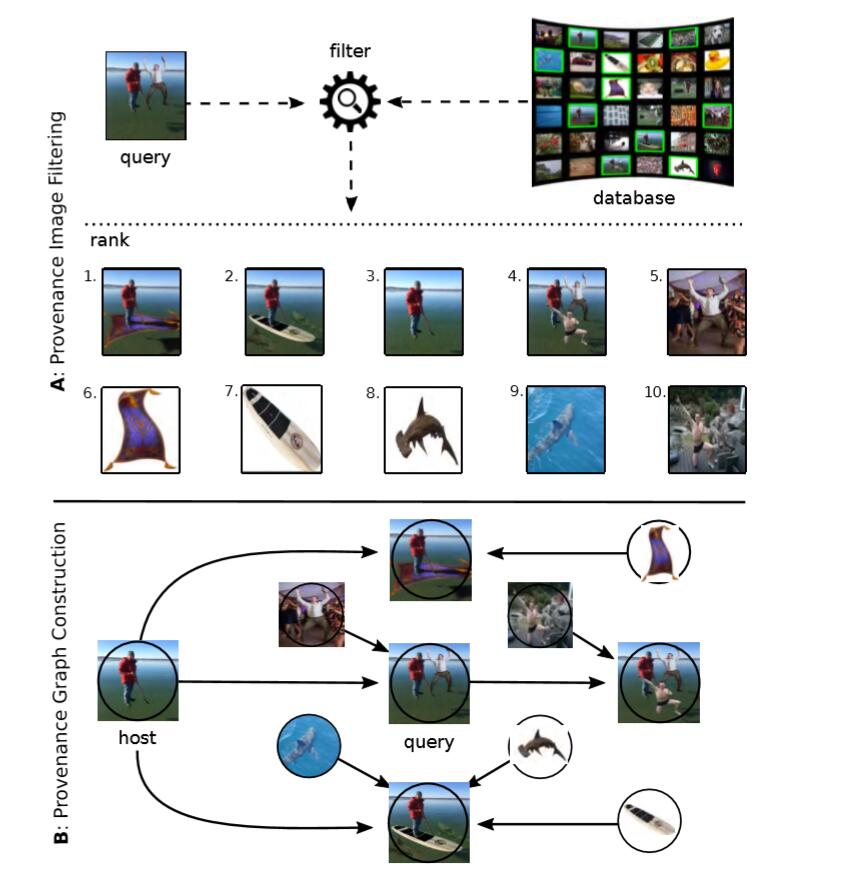
如图,将查询图(query)在数据库(database)中进行检索(retrieval),找出10张与查询图最相似的图片。然后将这11张图按照修改方向构造出溯源图。箭头表示修改方向。
2.处理方式
整个溯源图的构建,分为两个步骤,溯源图过滤(从数据库中找出和查询图相关的图)和溯源图的构造(将查询图与相关图以图的形式展示出修改关系)。
2.1 溯源图集过滤
这一步主要是两个目的:将图像转变为可比较的形式和计算图片之间的差异度。随便给定两张图,是没有办法直接比较的,只有将图片用特征(向量)表示出来(局部特征1),才可以进行比较。另外,找到k个最相似的图片之后,a,b都与查询图c相似。最后要怎么连接呢?通过计算图片之间的差异度(不相似程度)来连接是最好的方法。
2.1.1 局部特征提取
在图像中提取特征点(向量),目前有两类方法:特征点提取算法和神经网络。
① 特征点提取算法
这一节主要介绍传统的特征点提取算法SIFT和SURF,以及文中用到的改进的SURF。
1)SIFT(Scale Invariant Feature Transform,尺度不变特征变换)
为什么选择介绍SIFT算法,因为在SIFT算法诞生之前,角点检测算法霸占了特征点检测和匹配的江湖,而SIFT的诞生,标志着特征点检测算法进入了新时代,之后,又相继诞生了MSER(Maximally Stable Extremal Regions,最大稳定极值区域),SURF(Speeded Up Robust Features,加速稳定特征)。因此,SIFT作为新时代特征点检测算法的老大哥,还是值得一提的。
SIFT具有如下几个优点:
- 对旋转、尺度缩放、亮度变化保持不变性,对视角变化、噪声等也存在一定程度的稳定性;
- 独特性,信息量丰富,适用于在海量特征数据中进行快速,准确的匹配;
- 多量性,即使少数几个物体也可以产生大量的Sfit特征向量;
- 可扩展性,可以很方便的与其他形式的特征向量进行联合。
其流程可用下图概括(下图来源于参考文献12):
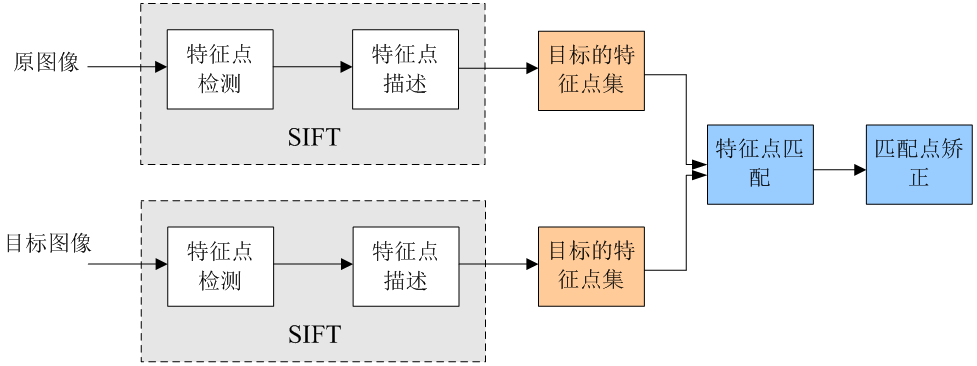
但其缺点也很明显,生成的特征维度太高了,128维,在进行检索比较的时候,需要耗费大量时间。
SIFT算法的详细步骤可参考以下博客:
https://blog.csdn.net/dcrmg/article/details/52577555;https://blog.csdn.net/dcrmg/article/details/52561656;https://www.jianshu.com/p/9487e98a8c45
2)SURF(Speeded Up Robust Features,加速稳定特征)
该算法在保持 SIFT 优良性能特点的基础上,同时解决了 SIFT 计算复杂度高、耗时长的缺点,对兴趣点提取及其特征向量描述方面进行了改进,且计算速度得到提高。
具体步骤为:
- 构造Hessian矩阵,计算特征值α 。Sift采用的是DOG图像,而SURF采用的是Hessian矩阵行列式近似值图像。有了这个近似的模板以后,计算高斯滤波和二阶导数两个步骤就可以一个步骤完成,同时,为了提高计算效率,还引入了积分图像的概念,提高了速度。
- 构造高斯金字塔。对于SURF算法,图像的大小总是不变的,改变的只是高斯模糊模板的尺寸,当然,尺度σ也是在改变的。
- 定位特征点。将经过hessian矩阵处理过的每个像素点与其3维领域的26个点进行大小比较,如果它是这26个点中的最大值或者最小值,则保留下来,当做初步的特征点。
- 确定特征点主方向。为了保证旋转不变性,在SURF中,不统计其梯度直方图,而是统计特征点领域内的Harr小波特征。这也是为什么可以说特征点是特征向量,因为它具有了方向。
- 构造特征描述子。在特征点周围取一个正方形框,框的边长为20s(s是所检测到该特征点所在的尺度)。该框带方向,方向是第4步检测出来的主方向。然后把该框分为16个子区域,每个子区域统计25个像素的水平方向和垂直方向的haar小波特征,这里的水平和垂直方向都是相对主方向而言的。该haar小波特征为水平方向值之和,水平方向绝对值之和,垂直方向之和,垂直方向绝对值之和。
详细说明可参考以下博客:
https://blog.csdn.net/ecnu18918079120/article/details/78195792;
https://www.cnblogs.com/gfgwxw/p/9415218.html;
3)改进的SURF
SURF提取特征点,简单说是提取Hessian值最大的m个点。文中1设定一个参数p(p<m),前p个特征点提取方式不变,但是后m-p个点提取时,只提取那些不会覆盖已提取的特征点的特征点。这样做的好处是,除了能够在强响应区域(Hessian值大)提取特征点外,还能在其他一些地方(如:边缘,背景)提取到少量特征点,使得特征点能够更好的表示一张图。如下图所示(来源于参考文献1),左边是常规的SURF提取到的特征点,右边是改进后的,可以看到,提取的特征点更为全面。 
② 卷积神经网络提取特征点(DELF)
文章《Large-Scale Image Retrieval with Attentive Deep Local Features》是今天早上准备写博客时,无意中翻到的。该文章提出一种用于大规模图像检索的注意力局部特征表达,称之为DELF(DEep Local Feature)。这种新型特征是从训练好的卷积神经网络中提取出来的,该卷积网络是在一个地标数据上使用图像级的标注完成训练的。为了能够获得具有语义信息的、对图像检索有利的局部特征,文章还提出一种用于关键点提取的注意力机制,该机制和特征表达共享大部分的网络层。本文的方法可以取代图像检索中其他的关键点检测和表达方法,获得更为准确的特征匹配和几何验证。文章的系统通过生成可信的置信得分来减少假阳率,这在当数据库中没有和查询图像相匹配的结果时具有较好的鲁棒性。整个过程如下所示(图来源于参考文献10)。
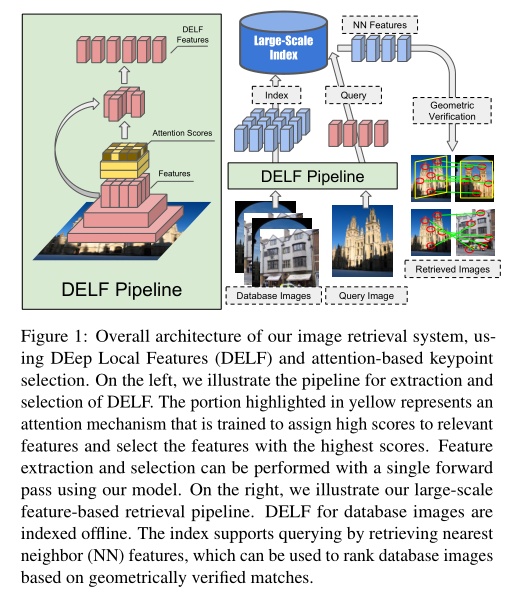
2.1.2 构造差异矩阵
构造差异(dissimilarity)矩阵也有两个可行的方法,分别是:基于几何一致性匹配1和基于卷积神经网络3。
①基于几何一致性匹配1
在用改进的SURF算法提取完特征后,对特征先进性粗量化。通过K-means进行聚类,计算每个特征和类中心的残差向量,这样可以快速将全局遍历锁定为感兴趣区域,舍去不必要的全局计算以及排序。之后再进行PQ(乘积量化)(PQ是通过划分子空间来加速索引速度,因此文中还在划分子空间时引入Optimized PQ来找到最优子空间划分)来建立码本,量化编码。之后,对查询图进行相同操作,计算对称距离。(一般来说,用非对称距离多一些,因为其损失小)。过程如下所示(图来源于参考文献7):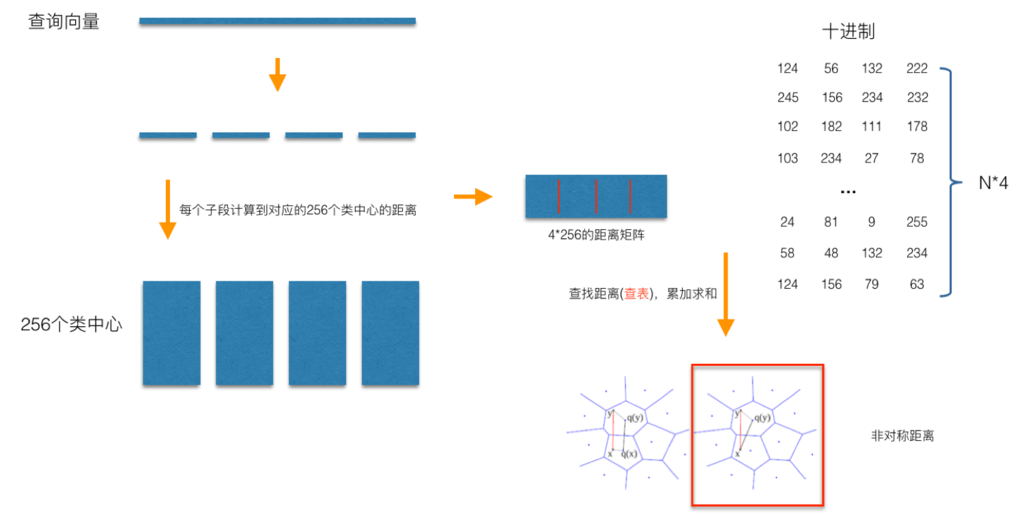
(关于PQ的详细介绍可参考博客:https://blog.csdn.net/langb2014/article/details/99715684)
然后进行迭代搜索,将搜索到的图作为新的搜索图进入迭代搜索,直到搜不到图后停止。迭代搜索的好处是不但可以搜索到与查询图直接相关的图,还能搜索到间接相关的图。
接下里是基于几何一致性匹配计算不相似度。对于任意两张图,找出两个最佳匹配,不妨设为p1,p2∈图I1,q1,q2∈图I2。则计算p1与p2的L2距离和角度,同理,计算q1与q2的L2距离和角度,以此来估计I1与I2间的变换(只估计缩放,旋转,平移这三种变换)。然后根据估计到的变换,来计算特征的匹配个数,取其倒数作为不相似度(匹配数越多越相似)。
其中,文中指出,如果某个特征和其最佳匹配的两个特征的距离都小于一个阈值t,则舍弃该特征,因为该特征的可辨识度很差。
②基于卷积神经网络3
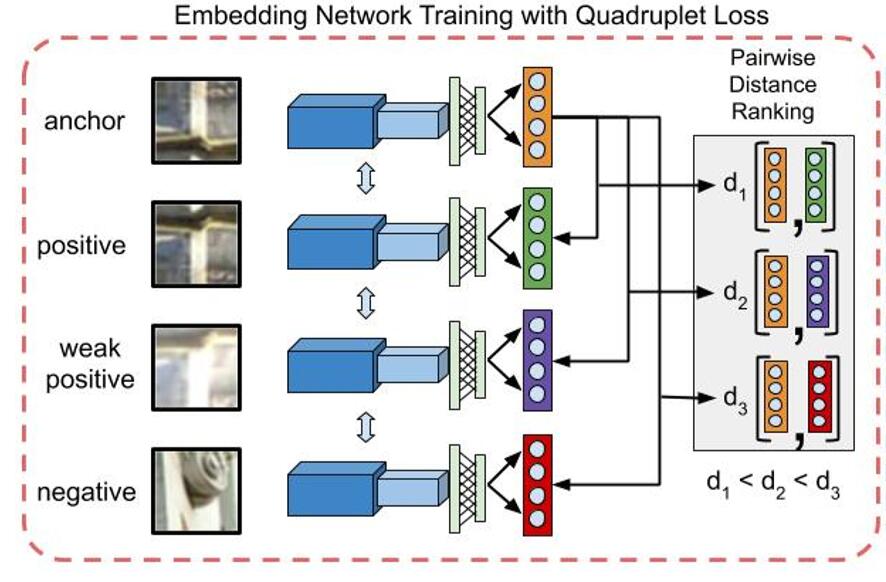
文中构建了一个13层的卷积神经网络(CNN),包括5个卷积层,5个最大池化层,2个完全连接层和1个批规范化层。激活函数是ReLU,即f(x)=max{0, x}。
文中用于训练网络的思想很新颖。他们用四类图片块(patches)来训练网络。
- 第一类:原始图(anchor patch)。
- 第二类:正样本(positive patch),每个样本经过M次修改操作。
- 第三类:弱正样本(weak positive patch),每个样本经过M+N次修改操作。
- 第四类:负样本(negative patch),每个样本和原始图毫无关系。
并且,修改操作包含很多种,主要分为以下四类:1)投影变化(如:缩放,旋转,翻转,间接,投影);2)颜色空间变换(如:亮度变化,对比度,伽马校正,灰度变化);3)频率空间变化(如:模糊和锐化);4)数据损失压缩。每次变换随机选择其中一种进行。
由这么多操作得到的模型,如果泛化性能很好,则意味着,在计算不相似度方面,远远优于其他模型(上述基于几何一致性匹配的只支持3种操作)。训练过程如下图所示(图来源于参考文献3)。
最小化损失函数:
L ( a , p , p ′ , n ) = m a x ( 0 , − y ∗ ( d ( a , p ′ ) − d ( a , n ) )
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 877
877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









