







在大数据计算框架当中,MapReduce无疑是典型的代表,作为Hadoop原生的计算引擎,在批处理上尤其具备优势,而后来为我们所熟知的Spark框架,也是继承了MapReduce的核心思想。今天的大数据开发分享,我们就主要来讲讲MapReduce Shuffle过程。
MapReduce编程模型的原理,简单来说,就是Map任务的输出,Reduce任务的输入。在多任务(进程)的网络环境下,如何将M个Map任务的输出传输到N个Reduce任务所在节点是MapReduce编程模型要考虑的重要问题。
而Shuffle过程的功能就是将M个Map任务的输出按一定的规则通过网络拷贝到N个Reduce任务端。
MapReduce编程模型可以划分为Map和Reduce两个阶段,Shuffle过程与两个阶段均有重复。
Shuffle过程详情:
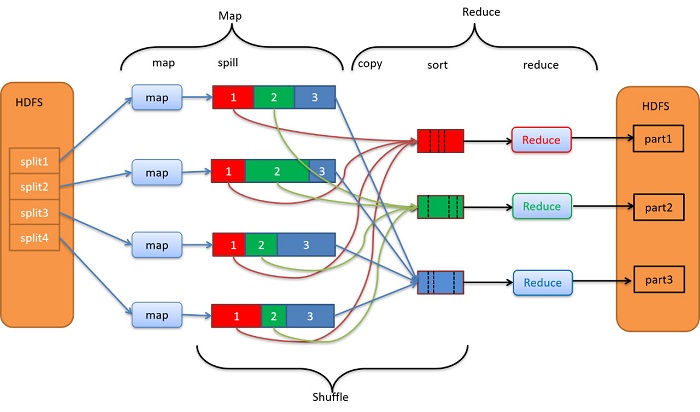
1、每个Map任务的输出都对应三个分区,对照上图,分别是红色、绿色和蓝色,每种颜色代表其属于相同颜色的Reduce任务。此处Reduce任务的个数决定了Map任务输出应该分成多少分。
2、Map任务的分区的依据由用户自己定义,并且所有的Map任务共享同一个分区规则。以单词计数wordcount为例,可以以首字母来进行划分。
3、Map任务的输出数据首先会保存到一个位于内存的环形缓冲区,该缓冲区达到触发条件以后,会将内存中的数据溢出写入(spill)到本地磁盘上。单个Map任务可能会产生很多零碎的小文件,这些小文件会被逐步合并(merge)并进行排序(sort), 最终成一个大文件。在大文内部,每个分区内的数据都有序。
4、每个Map任务的输出最终会聚集成一个数据文件,但是这个数据文件在逻辑上分为了三个分区,且附有配置文件记录每个分区的起止偏移量。Shuffle过程在拷贝数据时会参考这份配置文件,将逻辑上分区的数据拷贝到不同的Reduce端。
5、Shuffle过程是一个多对多的映射过程,每个Reduce任务要访问所有四个Map任务的输出,并将属于自己的那一部分数据远程拷贝到本地。
6、Shuffle过程将每个Map的输出按分区(颜色)拷贝到对应的Reduce任务端。Reduce任务还需要将这4份输入数据进行合并(merge)和排序操作(sort),最后才调用Reduce函数。
7、Map任务的输出数据和Reduce任务的输入数据,都可以称为中间数据。中间数据在逻辑上和物理上均不属于HDFS。对中间数据的反复合并(merge)和排序(sort)会引起大量的磁盘I/O操作。
为了避免与同一物理节点上的DataNode进程产生I/O竞争引起的程序性能下降,在配置HDFS和MapReduce时要注意两点:
①不能把物理节点的全部磁盘空间都配置给DataNode;
②为MapReduce中间数据的操作留足充足的存储空间,甚至可以配置独立的磁盘。
关于大数据开发,MapReduce Shuffle过程,以上就为大家做了简单的介绍了。MapReduce是大规模数据计算的重要指导思想,搞懂了MapReduce,对于后续的Spark学习,也是很有帮助的。















 328
328











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









