







一分钟精华速览
“只知道系统有问题,但是找不到问题到底出在哪里”,这几乎是大家都面临过、或正在面临的问题。用户在投诉,但是我的指标都是正常的,到底是哪一环出问题了? 本文详细介绍了中国联通在智能运维领域的应用实践,从架构师视角讲述了如何通过构建稳定性保障体系和数字化监控平台,来支撑庞大分布式系统的端到端故障处理能力,做到故障1分钟发现,5分钟定位,15分钟快速抢通。  作者介绍
作者介绍

中国联通软研院副总架构师——吴天昊 TakinTalks稳定性社区特邀讲师。中国联通软件研究院副总架构师,主导中国联通数字化监控平台的整体架构设计及演进,并负责中国联通数字化生产运营保障体系的建设与落地工作。致力于完善“平台+应用”生态体系,打造联通集团自动化生产和智慧化运营的生产运营平台。
温馨提醒:本文约7000字,预计花费10分钟阅读。
后台回复 “交流” 进入读者交流群;回复“1019”获取课件资料;
背景
作为中国的三大通信运营商之一,中国联通可以说家喻户晓。每次大家去营业厅办理业务,或者在手机上交话费、月租的扣除等等,所有这些都是由中国联通软件研究院(以下简称“联通软研院”)建设和维护的系统在背后默默支撑。这套系统我们称之为cBSS(Center Business Support System),也就是集约化业务系统,中国联通也是唯一一个全国31省份的业务系统集中化的运营商。
集约化带来的好处无需赘述,但同时也带来了不少挑战——系统庞大,运维难度自然提升。作为联通软研院的副总架构师,我负责联通软研院数字化生产运维保障体系的建设和落地,包括数字化监控平台的整体架构设计及演进。我们的目标是构建一个“平台+应用”的生态体系,共同打造联通集团自动化生产和智慧化运营的工作台。
而数字化转型意味着系统的重构和升级,也意味着新的运维问题将如影随形。那么,中国联通面临的问题和挑战到底有哪些?以及如何应对?接下来一起探讨,中国联通如何通过建设监控平台,实现智能运维,提升系统稳定性。
一、联通数字化转型运维遇到哪些挑战?
1.1 一些常见的问题和典型故障
这里先列举了许多可能的问题和挑战。也想先请大家思考一下,你们是否在自己的公司、团队或个人工作中遇到过这些问题和挑战?如果你们确实遇到了这些问题,希望下面中国联通的实践经验可以为你提供一些新的思考方向,从中获得一些新的启示和收获。
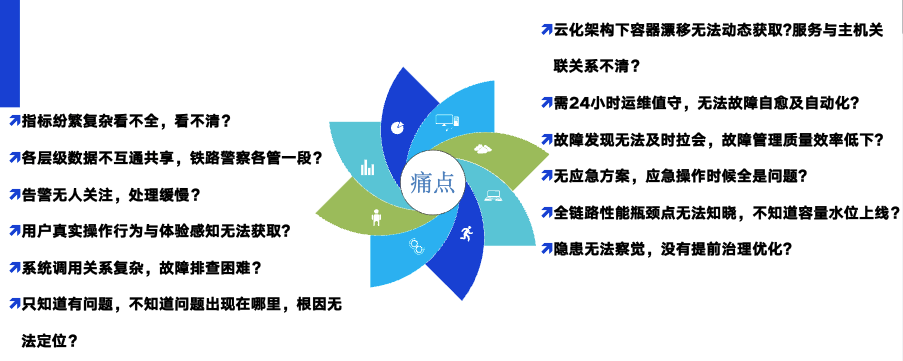 在云原生环境下,我们也经常会遇到一些典型的故障,我这里举几个例子:
在云原生环境下,我们也经常会遇到一些典型的故障,我这里举几个例子:
单实例故障:假设有一个服务,这个服务有十个实例,其中只有一个实例出现了问题。此时,它可能会影响到上游的很多关联服务,导致这些服务变得不可用。例如,服务的JVM出现问题,或者由于一条链路的数据出现问题,导致服务实例异常。这样的问题如何发现和定位?
下游组件故障:有时候,服务本身没有问题,但是依赖的下游组件出现了故障。例如,依赖的Redis突然出现了雪崩,或者调用的ES突然查询变慢。这些问题又该如何处理?
主机故障:还有一些问题可能出在主机上,比如主机突然死机,或者主机出现故障。这将影响到主机上运行的所有组件,甚至导致上层的服务无法提供,进而影响业务,导致业务中断或者业务损失。
外部接口故障:除了自身系统内部的问题,还可能会遇到外部因素的干扰。例如,依赖的第三方接口出现了问题。这样的问题又该如何快速发现,快速感知,快速排查呢?
针对这些典型的故障,需要有一套有效的处理和定位机制。
1.2 运维面临的挑战
中国联通的系统架构从传统的IT架构转变为云原生架构,这无疑为运维带来了许多挑战。
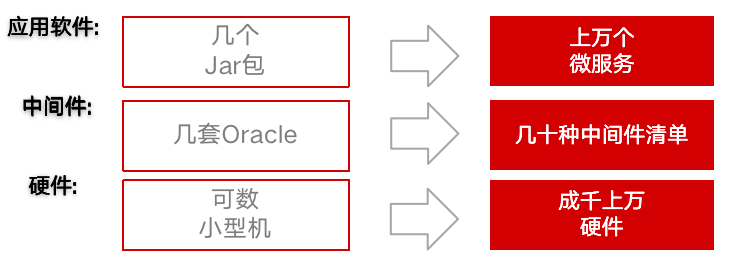
1.2.1 分布式架构挑战
原本只需要几个JAR包就可以提供服务的系统,现在已经被解耦为成千上万个微服务。这意味着我们需要管理和维护的对象数量是几何级增加的,这无疑大大增加了运维的难度。同时,如何梳理这些微服务之间的调用关系也成了一个难题。诸如数据分片、异地存储等这类传统维护模式也难以为继。
1.2.2 运维生态挑战
由于各个系统都会建设自己的运维工具,而这些工具往往是烟囱式的建设,没有进行整体的拉通,导致运维能力分散,不成体系。另外,各层面的数据(如应用、数据库、中间件、云平台、基础设施等)存在孤岛,没有进行有效的整合,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 867
867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









