







 K近邻算法是一种基于实例的学习,通过计算新实例与训练集的距离,选择最近的K个点进行分类。关键因素包括距离度量(如曼哈顿距离、欧式距离)、K值选择(影响模型复杂度和预测效果)以及分类决策规则(多数表决)。核心代码展示了如何计算欧式距离并选取最近邻进行分类。实际应用中,大数据量时可能需要利用数据结构优化计算效率,如kd树。
K近邻算法是一种基于实例的学习,通过计算新实例与训练集的距离,选择最近的K个点进行分类。关键因素包括距离度量(如曼哈顿距离、欧式距离)、K值选择(影响模型复杂度和预测效果)以及分类决策规则(多数表决)。核心代码展示了如何计算欧式距离并选取最近邻进行分类。实际应用中,大数据量时可能需要利用数据结构优化计算效率,如kd树。
1、概述:其基本思想是--对于新实例,计算其与训练集的距离,取最相近的K个,根据分类规则决定该实例的类别
2、三大要素:距离的度量、K值的选择、分类决策规则
3、距离的度量: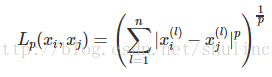
4、K值的选择:K值的选择对算法的影响很大;很明显,K值越大,模型越简单,其估计误差会减少,但同时近似误差会变大;很多无关的值会被考虑进来,影响预测的效果。相反,如果K值取的越小,模型就月复杂,此时估计误差会变大,模型对实例点非常敏感,如果该实例点是噪声,则会导致预测错误。
5、分类决策规则:一般采用多数表决的方式。
6、一般K近邻算法的实现采用的是线性扫描的方式,但是如果数据量特别大的时候需要考虑使用不同的数据结构来储存数据,以减少计算的次数;如kd树
7、<<机器学习实战>>种关于K近邻算法的实现:
from numpy import *
import operator
from os import listdir
def classify0(inX, dataSet
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 482
482

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









