






今天研究了一下Linux 32bit程序的函数调用过程,主要是从汇编指令角度去分析函数调用前后栈帧的变化。
首先解释一下什么是栈帧。
我们知道进程在执行时的地址空间包含3部分:代码段、全局数据段、堆以及栈。其中堆和栈都是动态变化的内存区,并且堆是向上生长,栈是向下生长。
那么栈有什么作用呢?一是保存函数(过程)的本地变量:如果函数的local变量都是基本类型并且数量较少,那么可以直接保存在通用寄存器里。但是总有些特殊的情况:1)变量较多,寄存器数量不够;2)存在结构型的变量;3)如果对local变量有取址的操作(&)。那么就需要把他们放在栈里。注意:对于动态分配的内存(malloc/new),数据是存放在堆区域的,但是指向数据区域的指针是放在栈里的。
此外,函数一般是需要caller传递参数过来的,既可以通过寄存器传递,也可以通过栈传递。
这样,其实栈是服务于函数 (过程)的,每一个函数所占用的栈区域就是一个栈帧。一个栈帧的范围由两个寄存器来指定:%ebp(frame pointer)和%esp(stack pointer)。%ebp在函数执行过程中是不变的;%esp是动态变化的。因此,在传递函数参数时,需要通过%ebp来定位参数的地址。
下面分析一下函数调用的过程,主要关注以下方面:
- 参数如何传递
- 结果如何返回
- 栈帧如何转移
- 栈帧如何恢复
测试分析的代码如下:
// code.c
int accum = 0;
int sum(int x, int y)
{
int t = x + y;
accum += t;
return t;
}
int solve()
{
int x = 3;
int y = 4;
return sum(x, y);
}solve()函数是caller,sum()则是callee。看一下汇编之后的代码:
$ gcc -m32 -O1 -S code.c因为是在64bit Linux上测试,因此加上-m32选项,表示编译32bit的程序。
// code.s
.file "code.c"
.text
.globl sum
.type sum, @function
sum:
pushl %ebp
movl %esp, %ebp
movl 12(%ebp), %eax
addl 8(%ebp), %eax
addl %eax, accum
popl %ebp
ret
.size sum, .-sum
.globl solve
.type solve, @function
solve:
pushl %ebp
movl %esp, %ebp
subl $8, %esp
movl $4, 4(%esp)
movl $3, (%esp)
call sum
leave
ret
.size solve, .-solve
.globl accum
.bss
.align 4
.type accum, @object
.size accum, 4
accum:
.zero 4
.ident "GCC: (Ubuntu 4.3.3-5ubuntu4) 4.3.3"
.section .note.GNU-stack,"",@progbits上面的代码很简单,可以用来观察在进入sum()后栈帧的情况,如下图所示:
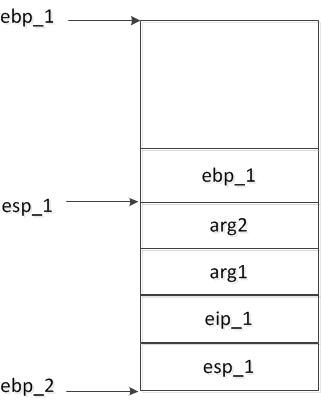
总的来说:
- caller负责在自己的栈帧中保存自己的ebp寄存器,并将传递参数之前的esp寄存器值放在ebp寄存器中;
- caller同时需要将函数参数入栈;
- callee需要将第1点中所述的caller保存在ebp中的esp值入栈,并从栈帧中取参数。
- caller执行call指令转移到callee,其中涉及到eip的保存;
- callee执行ret指令返回到caller,其中涉及到eip的恢复。但在这之前需要先将ebp寄存器的值pop出来;
- caller通过leave指令将保存在ebp中的值重新恢复到esp寄存器,从而恢复执行调用之前的现场。
需要提到的是,上面的代码实例中通过eax寄存器保存函数返回值。















 2117
2117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









