







 本文深入解析跳跃表的工作原理,对比链表和平衡二叉树的优势,详细阐述Redis中跳跃表的实现细节,包括数据结构设计和随机层级算法。
本文深入解析跳跃表的工作原理,对比链表和平衡二叉树的优势,详细阐述Redis中跳跃表的实现细节,包括数据结构设计和随机层级算法。
1 什么是跳跃表

以下是摘至维基百科关于跳跃表的描述:
跳跃列表是在基础链表的基础上按层建造的。底层是一个普通的有序链表。每个更高层都充当下面列表的“快速跑道”,这里在第
i层中的元素按某个固定的概率p出现在第i+1层中。
查找一个目标元素,从顶层列表和头元素起步,并沿着每层链表搜索。如果在一层列表中找到的元素等于目标元素,则表明该元素直接被找到。当在一层列表中查找到小于目标的元素时,就切换至该元素继续向右或向下层(向右找不到比目标小的)查找,直至底层链表。
跳跃列表的插入和删除的实现与相应的链表操作类似,除了"高层"元素必须在多个链表中插入或删除之外。
跳跃列表不像某些传统平衡树数据结构那样提供绝对的最坏情况性能保证。由于用来建造跳跃列表采用随机选取元素进入更高层的方法,在小概率情况下会生成一个不平衡的跳跃列表(最坏情况是在最底层仅有一个元素进入了更高层,此时跳跃列表的查找与普通列表一致)。但是在实际中它工作的很好,随机化平衡方案比在平衡二叉查找树中用的确定性平衡方案容易实现。
跳跃列表在并行计算中也很有用,这里的插入可以在跳跃列表不同的部分并行的进行,而不用全局的数据结构重新平衡。
这里有一篇漫画讲解的比较容易理解:
总结一下,我们为什么需要跳跃表:
- 相比于传统链表,跳跃表大大提高了查找效率,平均复杂度为O(logN);
- 相比于平衡二叉树(红黑树/AVL树等),实现简单,方便理解;
2 redis中的跳跃表
根据跳跃表的定义,接下来我们看看如何实现一个跳跃表,这里主要参考redis-5.0的实现。
先看数据结构:
typedef struct zskiplist {
struct zskiplistNode *header, *tail; // 指向底层链表的头部和尾部元素
unsigned long length;// 存储的元素个数
int level; // 当前最大的层级
} zskiplist;
zskiplist本身并没有维护多层链表,而是将层级关系放在zskiplistNode中来维护。接下来,看zskiplistNode的定义:
typedef struct zskiplistNode {
sds ele;// 存储的数据,二进制字符串
double score; // 分值,节点排序依据,分值相同时,根据ele字典序排序
struct zskiplistNode *backward;//反向指针
struct zskiplistLevel {
struct zskiplistNode *forward;//本层下一个对象
unsigned long span;//距离forward对象的跨度
} level[]; // 每个对象在创建时随机选择level值,p值为0.25
} zskiplistNode;
总结一下redis中的跳跃表的实现,如下图所示:
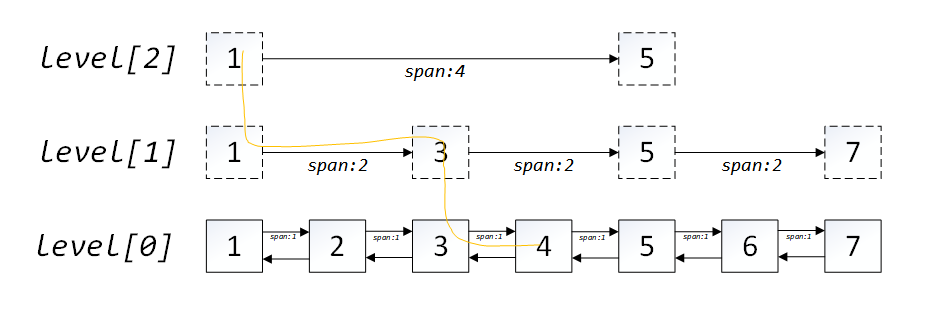
每个对象在插入到表中的时候,随机选择是否进入下一层级,代码如下:
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
其中,ZSKIPLIST_P就对应第一节理论描述中的概率p,取值为0.25。
图中黄线标识如何在跳跃表中查找节点4:
- 从header开始查找,发现header比target小,但是L2的下一个节点5比target大,所以到L1去找;
- 从L1前进到节点3,发现比target小,但是继续前进发现节点5比target大,所以到L0去找;
- 从L0前进到节点4,找到target,查找结束。
跨度span
每个forward指针都有个span属性,表示距离下一个对象的跨度。这样可以方便在查找到对象的时候直接获取到该元素在整个链表中的排序号(rank值)。
例如,节点4的查找路径是节点1->节点3->节点4,其rank值就是:2 + 1 = 3。

















 809
809

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









