







一、requests库安装
pip install requests
二、requests库导入
import requests
r.encoding
从HTTPheader中猜测的响应内容编码方式。(若网页header中不存在charset,则编码为ISO-8859-1)
r.apparent_encoding
从内容中分析出的响应内容编码方式(备选编码方式)
response.text
返回的是Unicode型的数据。—文本
response.content
返回的是bytes型也就是二进制的数据。-----图片等
r.raise_for_status
如果不是200,产生异常requests.HTTPError
三、最常用requests函数框架
import requests
#标准requests库获取html内容函数。
def getHTMLText(url):
#捕捉异常情况
try:
r=requests.get(url,timeout=30) #使用get方法url,返回response对象
#如果r.status_code不是200,则抛出异常
r.raise_for_status()
#设置最有可能的编码格式
r.encoding=r.apparent_encoding
#返回的是Unicode型的数据。---文本,
return r.text
except:
return "getHTMLText中,产生异常"
#程序的入口
if __name__ == '__main__':
#设置url
url="http://www.baidu.com"
print(getHTMLText(url))
四、案例
案例1. 爬取百度
查询一个你喜欢的明星,观察百度时,你键入“你好”关键词时,浏览器上方url的变化。

import requests
wb = input('输入一个你喜欢的明星\n')
url_baidu = f'https://www.baidu.com/s?wd={wb}'
resp = requests.get(url_baidu)
print(resp)
print(resp.text)
#保存到文件中
with open("baidu明星.html", mode="w", encoding="utf-8") as f:
f.write(resp.text)
结果如下,Response [200] 代表成功返回,但是html里的内容肯定是不符合咱们百度“星月”时的返回,这就是百度反爬。

这时需要设置headers信息,告诉百度我是浏览器发送的请求,而不是requests。
#-- snip
dic = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'
}
resp = requests.get(url_baidu, headers=dic)
# -- snip
案例2:爬取百度翻译
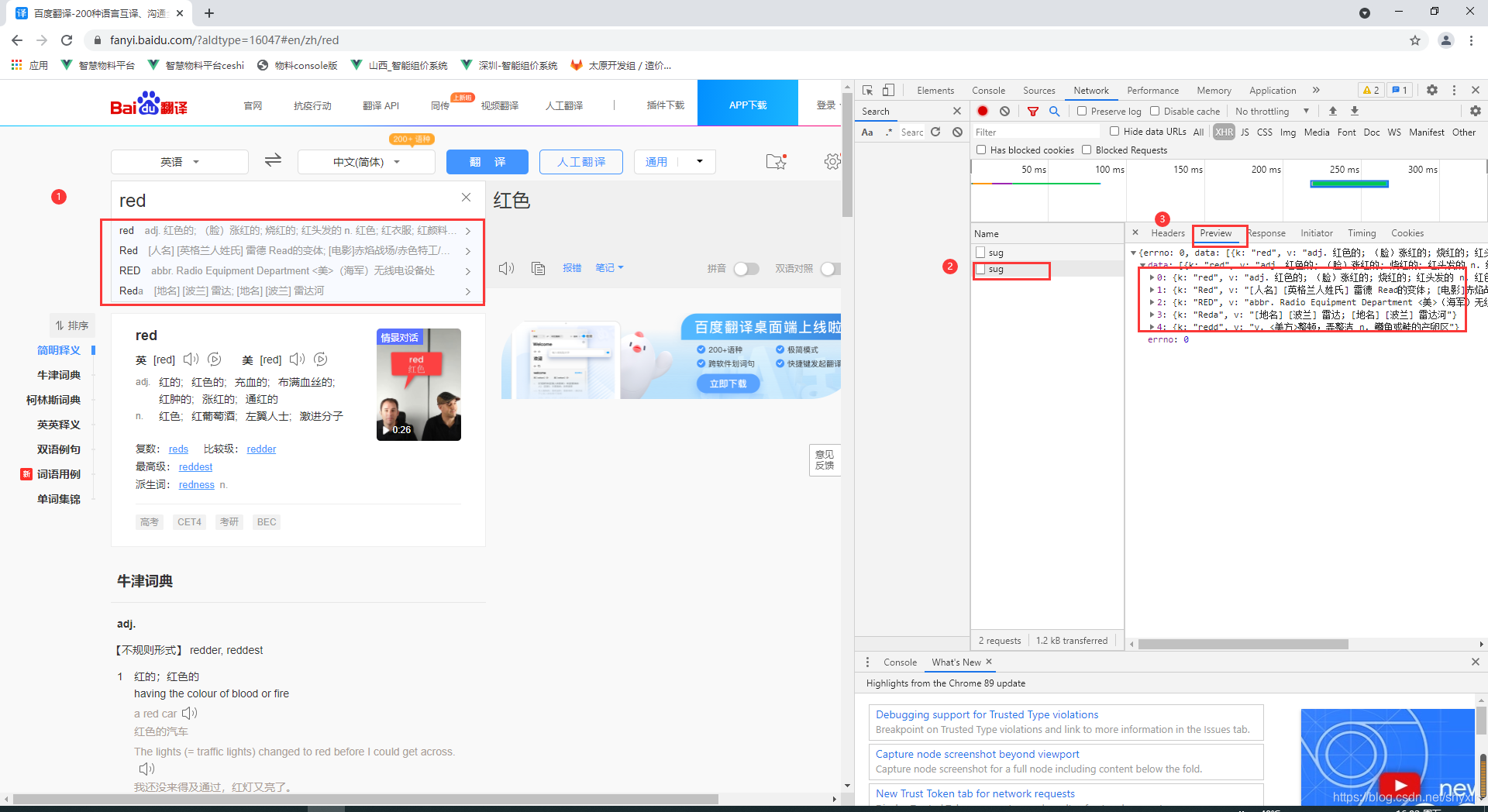

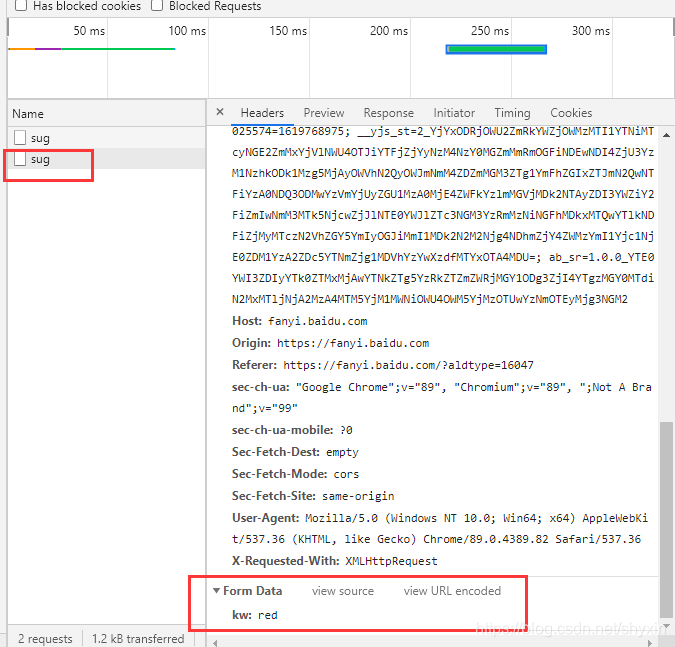
如上图,可以看到url,访问方式,Formdata
则对应requests的url, post方法,data,代码如下
import requests
url = "https://fanyi.baidu.com/sug"
s = input("请输入你要翻译的英文单词")
dat = {
"kw": s
}
# 发送post请求,发送的数据必须放在字典中,通过data参数进行传递
resp = requests.post(url, data=dat)
# 返回值是json 那就可以直接解析成json
resp_json = resp.json()
# {'errno': 0, 'data': [{'k': 'Apple', 'v': 'n. 苹果公司,原称苹果电脑公司'....
print(resp_json['data'][0]['v']) # 拿到返回字典中的内容
案例3:爬取豆瓣电影
豆瓣->电影->排行榜->分类排行榜
网址链接
F12,打开开发者工具,查找包含数据的链接
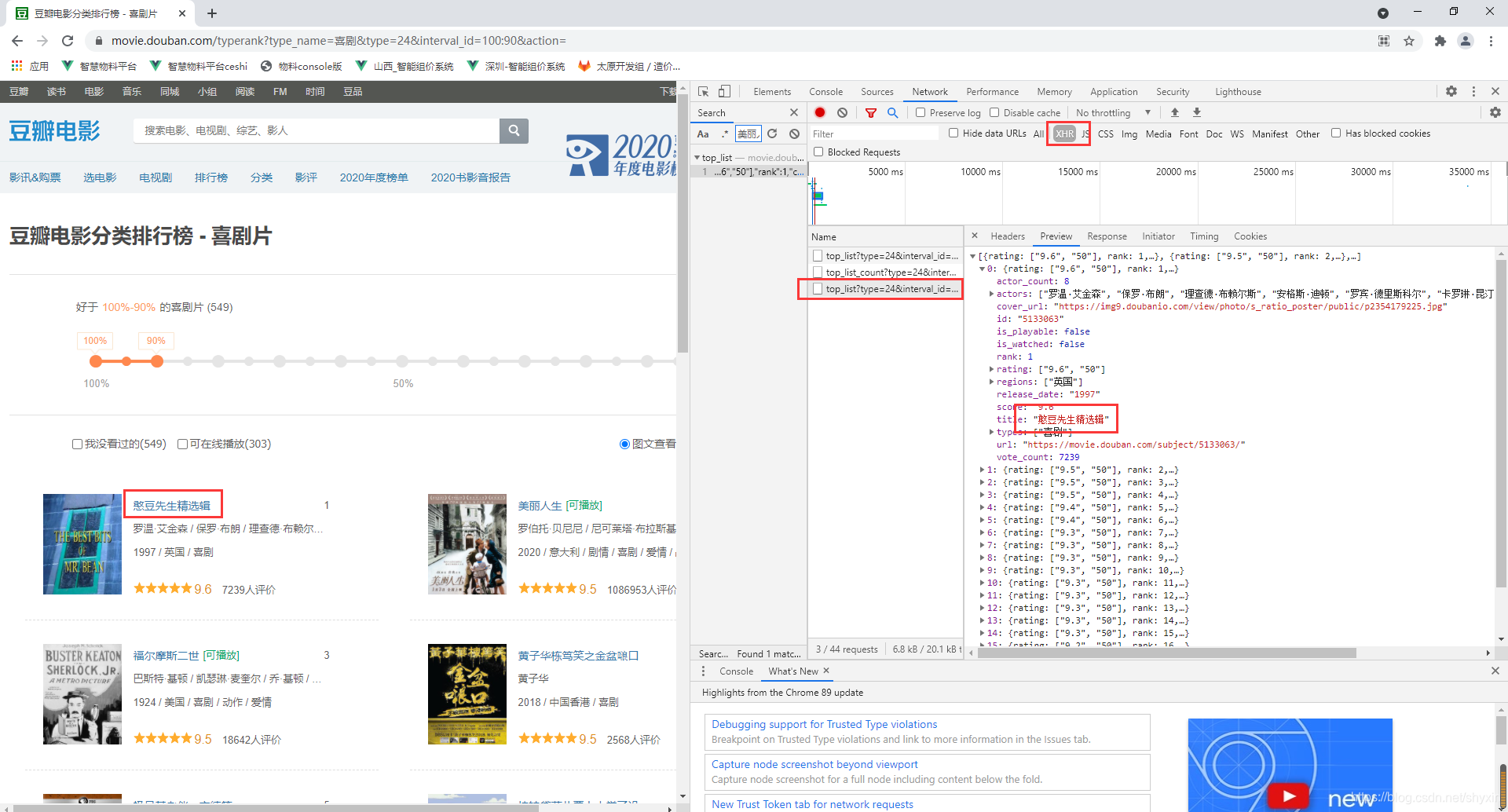
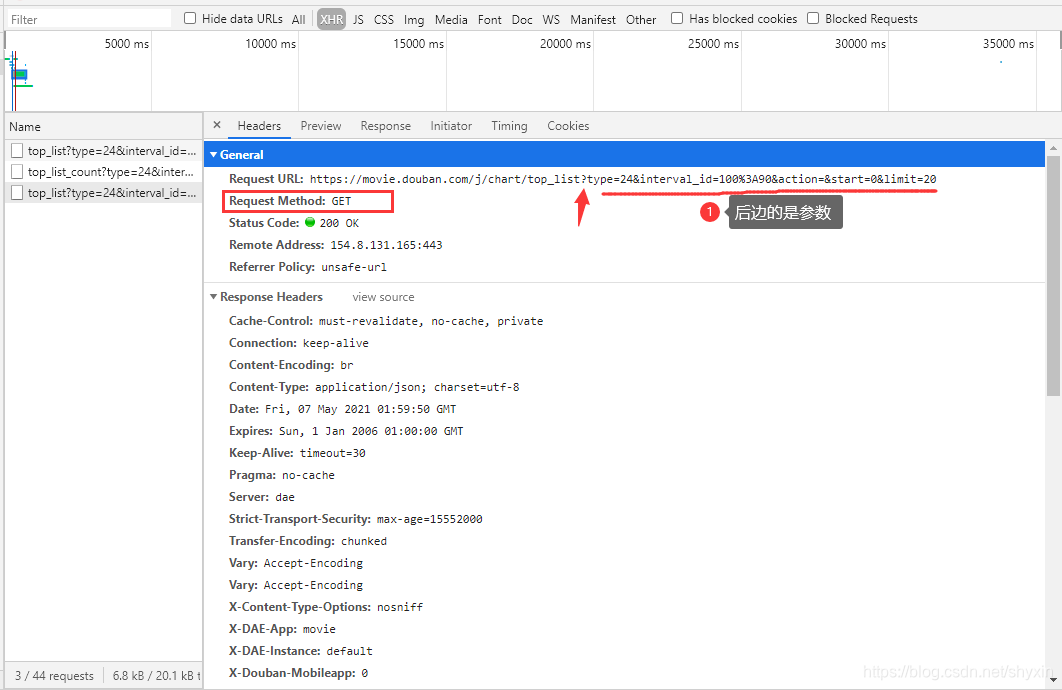
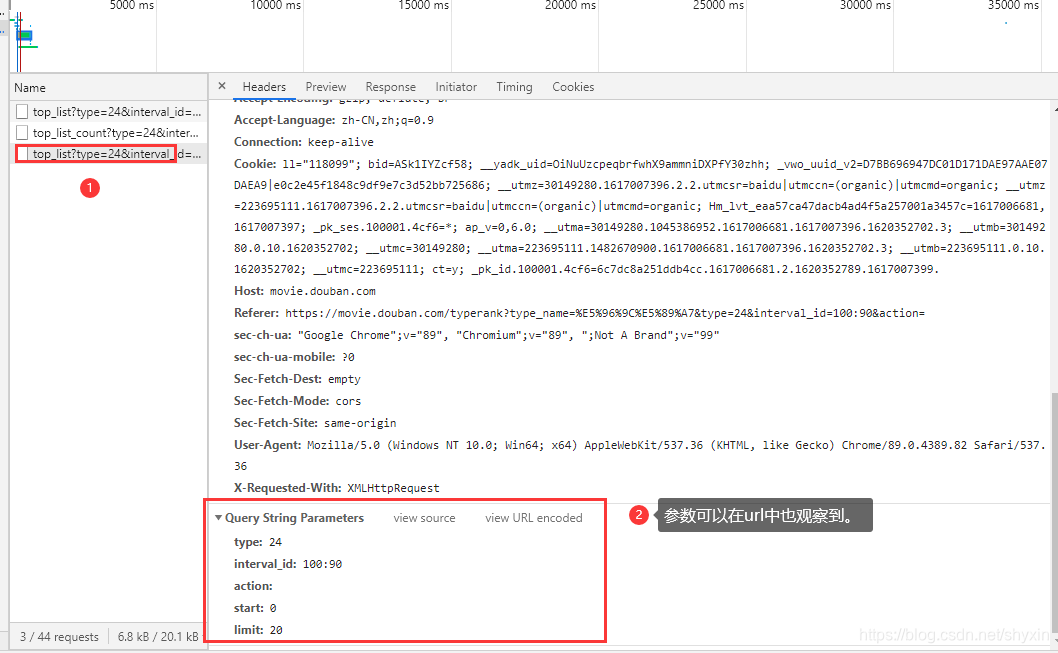
发现这个url很长,问号的参数有很多,对于这样的url可以,重新封装参数
# 豆瓣->电影->排行榜->分类排行榜
# https://movie.douban.com/typerank?type_name=%E5%96%9C%E5%89%A7&type=24&interval_id=100:90&action=
import requests
url = 'https://movie.douban.com/j/chart/top_list'
# 重新封装参数
param = {
'type': 24,
'interval_id': '100:90',
'action': '',
'start': 0,
'limit': 20,
}
resp = requests.get(url, params=param)
# 查看组成的url
print(resp.request.url)
# 查看内容
print(resp.text) # 发现什么都没有,猜测是被翻爬了
# 查找原因 ,首先考虑user-agent
print(resp.request.headers) # 'User-Agent': 'python-requests/2.23.0'
# 找到原因,我们自己设置user-agent
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'
}
resp2 = requests.get(url, params=param, headers=headers)
print(resp2.text) # 查看
print(resp2.json()) # 换成json
list_data = response.json()
#输出到文件
fp = open('./douban.json','w',encoding='utf-8')
json.dump(list_data,fp=fp,ensure_ascii=False,indent=2) #编码和 indent缩进
print('over!!!')
resp.close() #关闭请求
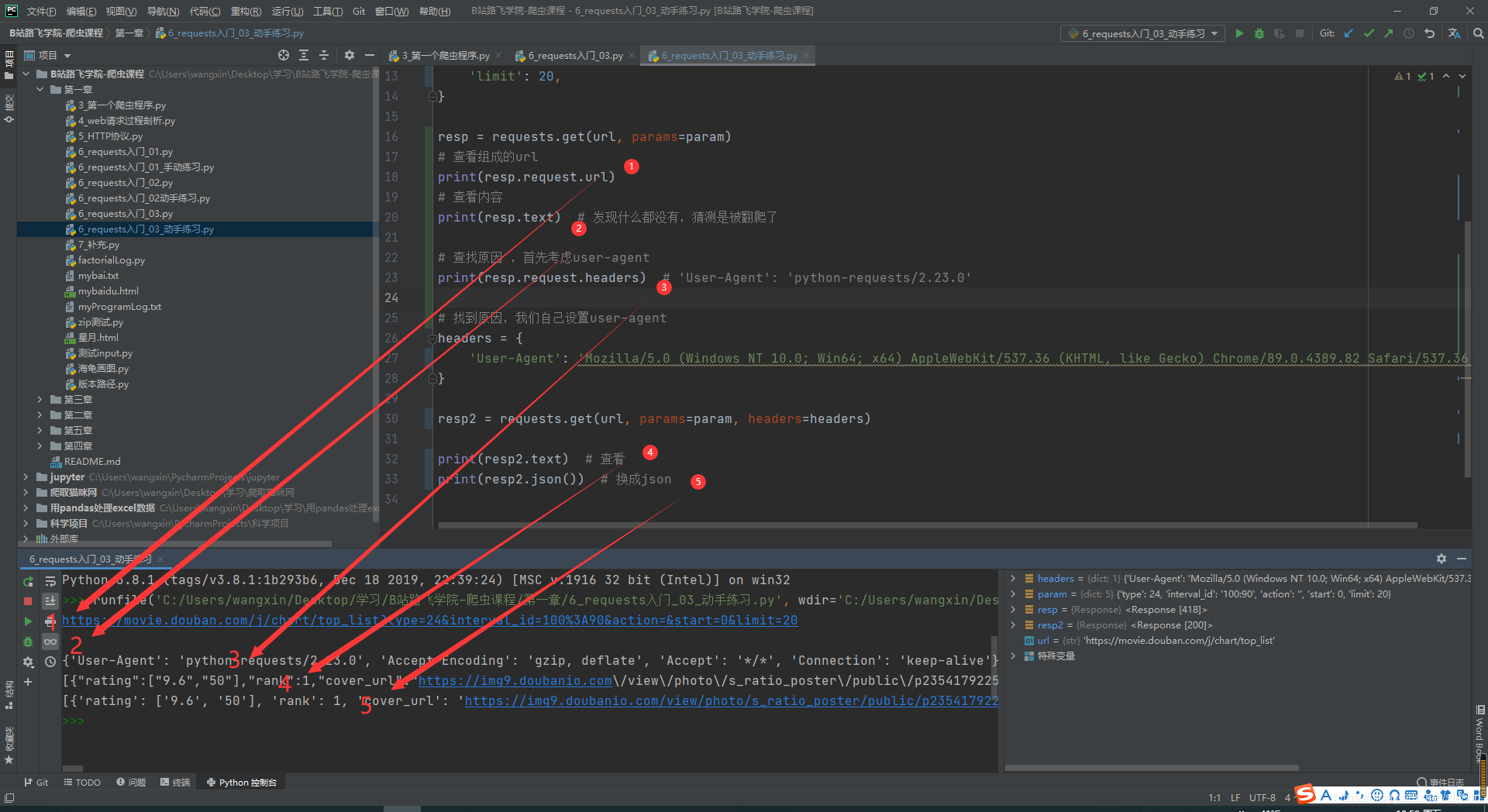
思考
当前爬取的只是20个电影,向下滑动鼠标滚轮,当快到页面底部时,会新增一些电影。用F12进行呢观察。会发现新增url,而其中变化的是【start】的数值。
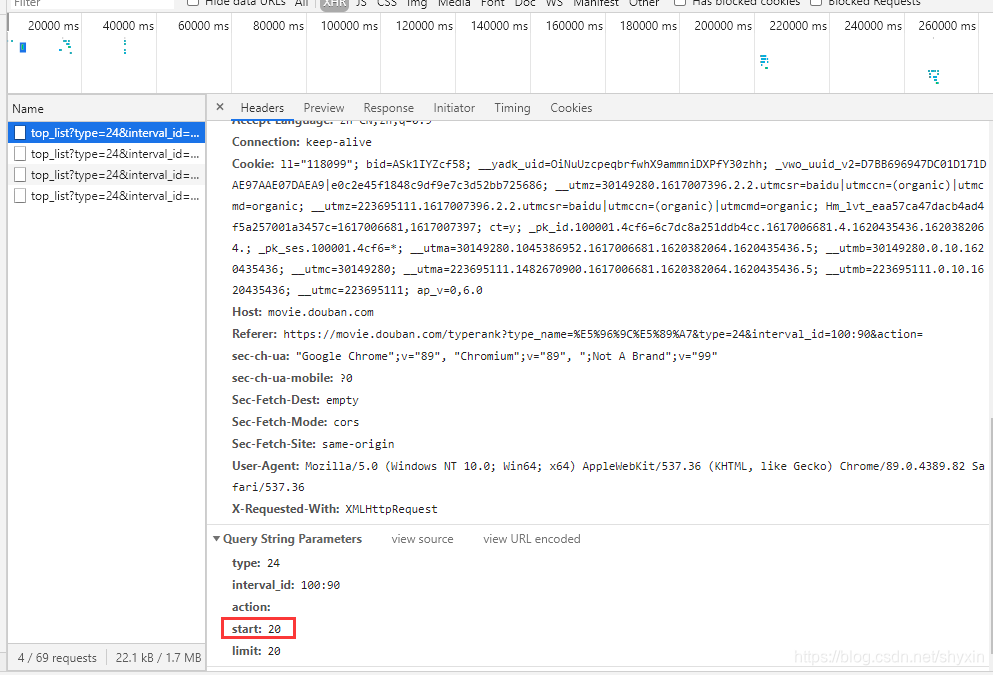
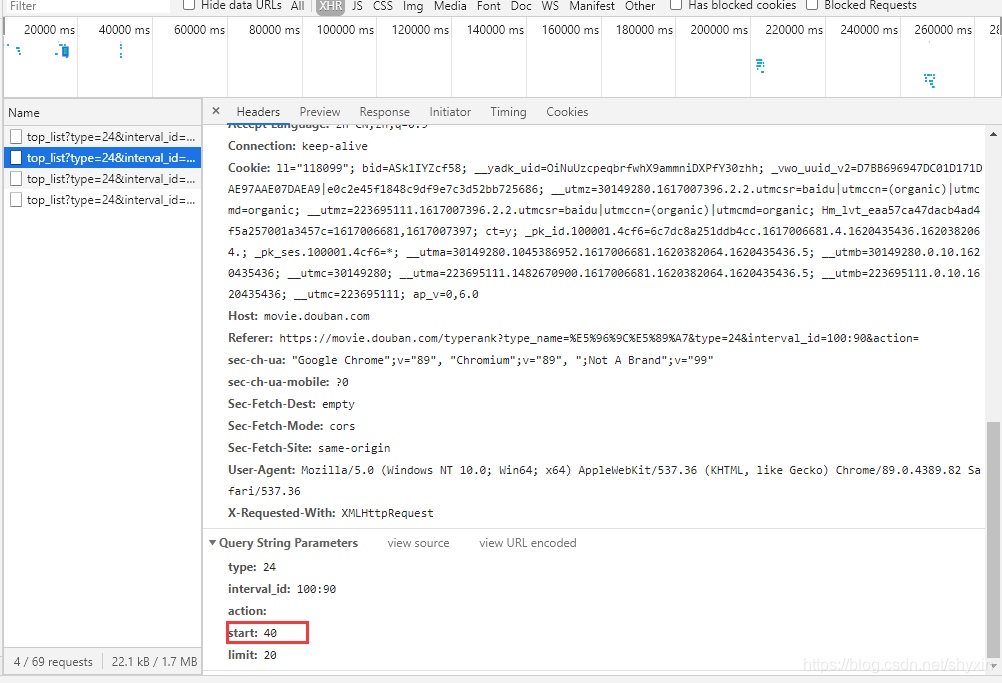
可以通过设置【start】变量进行全部提取。
import time #用来延时
for i in range(0,500,20): #生成所需的等差数
time.sleep(2)
param['start'] = i #改变start变量
resp3 = requests.get(url, params=param, headers=headers)
print(resp3.json()) # 换成json
resp3.close()
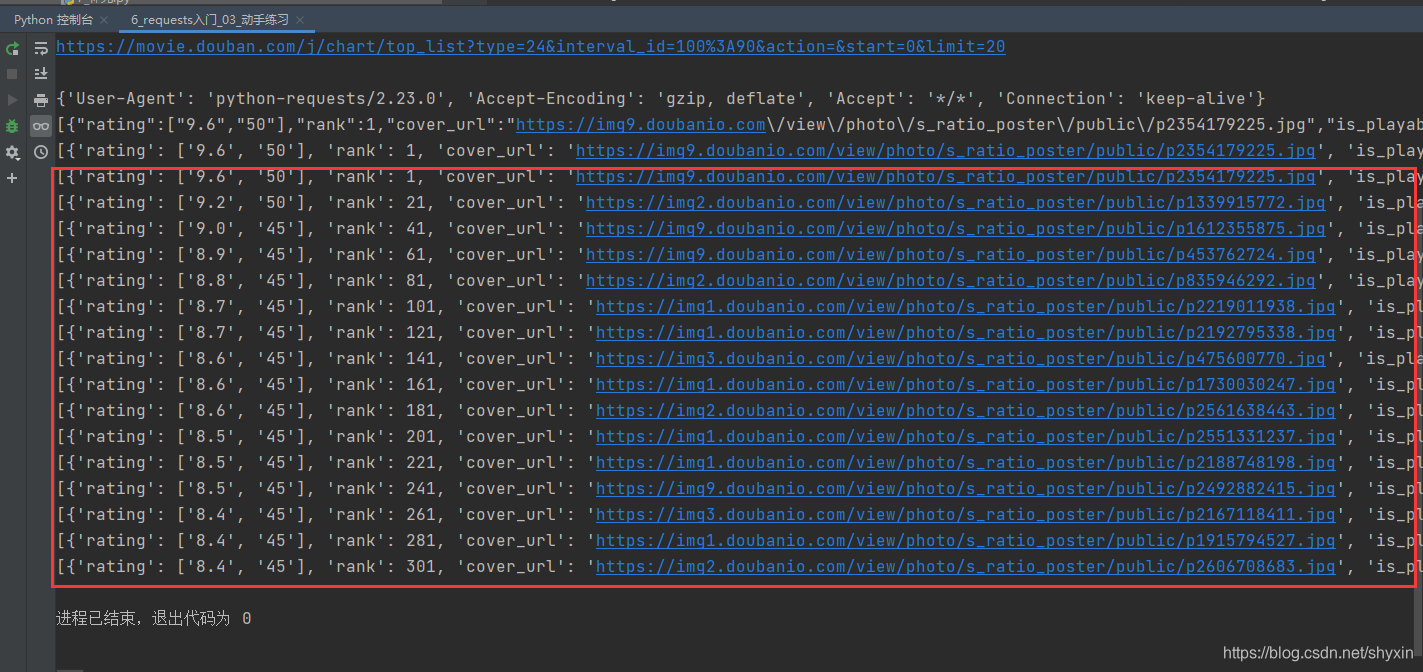
成功!
其他
慕课-嵩天老师-requests库ppt
他山之石,可以借鉴
http://httpbin.org/
网站是一个可以能测试 HTTP 请求和响应的各种信息的网站,蛮好用的,大家可以了解一下。















 3829
3829











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









