







《SQL必知必会》笔记
- 不能部分使用distinct
distinct作用于所有的列,不仅仅是跟在其后的那一列。
实例:user表
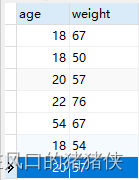
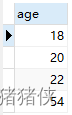
DISTINCT 作用单个属性
select DISTINCT age FROM user;
DISTINCT 作用多个属性
select DISTINCT age, weight FROM user;
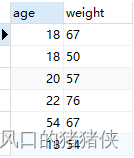
通过案例可知,DISTINCT 作用于其后面所有的列的组合。案例中为 age和weight,只有两行的age和weight都相同时,才会去重。
-
order by 需要保证为select语句中最后一个子句
-
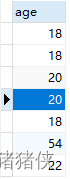
通常,order by 子句的使用是为了显示而选择的列。但是非检索的列排序也是合法的。
实例:user表
select age FROM user order by weight;
4. 存储过程就是为了以后使用而保存的一条或多条SQL语句,可以视其为批文件
5. 事务可以回退哪些语句?
事务处理用来管理insert、update、delete语句。不能回退select语句(也没有必要),也不能回退create或drop操作。
正则表达式
regexp匹配字串,like匹配整个串,利用^个$可以使regexp和like一样
- 入门案例
-- 查询role表中name字段中包含‘员’的所有行
select * from role where name regexp '员';
- 空白元字符
| 元字符 | 说明 |
|---|---|
| \\f | 换页 |
| \\n | 换行 |
| \\r | 回车 |
| \\t | 制表 |
| \\v | 纵向制表 |
- 正则公式
| 符号 | 含义 |
|---|---|
| . | 匹配任一字符 |
| | | 进行or匹配 |
| [] | 匹配几个字符之一, [1-9] 匹配1到9 |
| // | 转义符,用来匹配特殊字符,例如 \\. |
| [:alnum:] | 任意字母和数字(同[a-zA-Z0-9]) |
| [:alpha:] | 任意字符(同[a-zA-Z]) |
| [:blank:] | 空格和制表 |
| [:cntrl:] | ASCII控制字符(ASCII0到31和127) |
| [:digit:] | 任意数字(同[0-9]) |
| [:graph:] | 与[:print:]相同,但不包括空格 |
| [:lower:] | 任意小写字母(同[a-z]) |
| [:print:] | 任意可打印字符 |
| [:punct:] | 既不在[:alnum:]又不在[:cntrl:]中的任意字符 |
| [:space:] | 包括空格在内的任意空白字符(同[\\f\\n\\r\\t\\v]) |
| [:upper:] | 任意大写字母(同[A-Z]) |
| [xdigit] | 任意十六进制数字(同[a-fA-F0-9]) |
| * | 0个或多个匹配 |
| + | 1个或多个匹配(等于{1,}) |
| ? | 0个或1个匹配(等同于{0,1}) |
| {n} | 指定数目的匹配 |
| {n,} | 不少于指定数目的匹配 |
| {n,m} | 匹配数目范围(m不超过25) |
- 定位元字符
| 元字符 | 说明 |
|---|---|
| ^ | 本文的开始, 此外[^0-9]表示匹配不是0到9的数字 |
| $ | 本文的结尾 |
| [[:<:]] | 词的开始 |
| [[:>:]] | 词的结尾 |
-- 查询role表中name字段中包含 任一字符 + ‘员’ 的所有行
select * from role where name regexp '.员';
-- 查询role表中name字段中包含‘员’或'管' 的所有行
select * from role where name regexp '员|管';
-- 查询role表中name字段中包含‘员’或'管' 的所有行
select * from role where name regexp '[员管]';
--
select * from role where name regexp '[1-9]';
- 正则案例
| 正则公式 | 含义 |
|---|---|
| \\( [0-9] sticks?\\) | 匹配\\(匹配), sticks或stick |
| [[:digit:]]{4} | 匹配连在一起的四位数字 |
| ^ [0-9\\.] | 匹配以 .或任意数字为第一个字符的字符串 |
函数
| 函数明 | 说明 |
|---|---|
| CONCAT(str1,str2,…) | 拼接字符串 |
| trim(str1) | 去除字符串首尾空格 |
| ltrim(str1) | 去除字符串左侧空格 |
| rtrim(str1) | 去除字符串右侧空格 |
LEFT(str,len) | 返回str串左侧len个字符 |
| LENGTH(str) | 返回字符串的长度 |
| LOCATE(substr,str) | str中第一个substr的下标 |
| LOCATE(substr,str,pos) | str中从pos起,找到的substr的下标 |
RIGHT(str,len) | 返回str串右侧len个字符 |
| soundex(str) | 相同发音的字符串返回的结果相同 |
select left(name, 1) from role;
select locate('bar', 'foolbarbar', 6);
select lower('ABDC');
select right('abcds', 0);
-- soundex('Y Lee') 等于soundex('Y Lie')
select * from role where soundex(name) = soundex('Y Lie');
select SUBSTRING('123456',2);
| 函数明 | 说明 |
|---|---|
| ADDDATE(date,INTERVAL expr unit) | data 加上 expr个unit单位 |
| ADDDATE(expr,days) | expr加上days天 |
| ADDTIME(expr1,expr2) | 返回各个时间相加 |
| date(expr) | 返回expr中的日期部分 |
| Now() | 返回当前日期和时间 |
| curtime() | 返回当前日期 |
| DATEDIFF(expr1,expr2) | 返回expr1 - expr2的天数 |
| DATE_ADD(date,INTERVAL expr unit) | 高度灵活的日期运算函数 |
| DATE_FORMAT(date,format) | 返回date的format格式 |
| DAYOFWEEK(date) | 返回date对应的星期几 |
| day(date) | 返回日期的天数部分 |
| hour(date) | 返回日期的小时部分 |
| minute(date) | 返回日期的分钟部分 |
| month(date) | 返回日期的月份部分 |
| Second(date) | 返回日期的秒数部分 |
| Time(date) | 返回日期的时间部分 |
| Year(date) | 返回日期的年份部分 |
SELECT ADDTIME('2018-10-31 23:59:59','0:1:1'),ADDTIME('10:30:59','5:10:37');
SELECT DATE_ADD('2008-01-02', INTERVAL 31 DAY);
-- 返回当前日期,例如 2022-06-10
select CURDATE();
SELECT DATE('2003-12-31 01:02:03');
select DATEDIFF('2007-12-31 01:02:03','2005-12-31 01:02:03');
-- 返回2018-05-02
SELECT DATE_ADD('2018-05-01',INTERVAL 1 DAY);
-- 返回Sunday October 2009
SELECT DATE_FORMAT('2009-10-04 22:23:00', '%W %M %Y');
-- 1对应星期天
select DAYOFWEEK('2009-10-04 22:23:00');
-- 2022-06-10 17:30:25
select Now();
-- 22:23:00
select Time('2009-10-04 22:23:00');
-- 4
select day('2009-10-04 22:23:00');
-- 22
select hour('2009-10-04 22:23:00');
-- 23
select minute('2009-10-04 22:23:00');
-- 10
select month('2009-10-04 22:23:00');
-- 0
select second('2009-10-04 22:23:00');
-- 2009
select year('2009-10-04 22:23:00');
| 函数 | 说明 |
|---|---|
| abs(num) | 返回num绝对值 |
| cos(degree) | 返回degree余弦 |
| exp(num) | 返回以e为底的num指数值 |
| mod(num1, num2) | 返回num1 % num2 |
| pi() | 返回圆周率 |
| rand() | 返回一个随机数 |
| sin(degree) | 返回一个数的正弦 |
| sqrt(num) | 返回平方根 |
-- 2
select MOD(29,3);
-- 返回0-9
select floor(rand() * 10);
-- 7.38905609893065
select EXP(2);
-- 3.141593
select pi();
连接
- union规则
a. union必须由2条或2条以上的select语句组成,语句之间用union分割
b. union中的每个查询必须包含相同的列、表达式或聚集函数(不过各个列不需要以相同的次序列出)
c. 数据列类型必须兼容:类型不必完全相同。
d. union分割是,默认过滤掉重复的行;union all 分割时,保留所有行
e. 排序时,order by 放在最后一个select结尾
视图
-
视图的优势
(1)重用SQL语句。
(2)简化复杂的SQL操作。在编写查询后,可以方便地重用它而不必知道它的基本查询细节。
(3)使用表的组成部分而不是整个表。
保护数据。可以给用户授予表的特定部分的访问权限而不是整个表的访问权限。
(4)更改数据格式和表示。视图可返回与底层表的表示和格式不同的数据。 -
视图使用限制
(1)与表一样,视图必须唯一命名(不能给视图取与别的视图或表相同的名字)。
(2)对于可以创建的视图数目没有限制。
(3)为了创建视图,必须具有足够的访问权限。这些限制通常由数据库管理人员授予。
(4)视图可以嵌套,即可以利用从其他视图中检索数据的查询来构造一个视图。 -
视图操作
(1)视图用CREATE VIEW语句来创建。
(2)使用SHOW CREATE VIEW viewname;来查看创建视图的语句。
(3)用DROP删除视图,其语法为DROP VIEW viewname;。
(4)更新视图时,可以先用DROP再用CREATE,也可以直接用CREATE OR REPLACE VIEW。如果要更新的视图不存在,则第2条更新语句会创建一个视图;如果要更新的视图存在,则第2条更新语句会替换原有视图。
-- 创建myView视图
create view myView as select * from role;
-- 查询
show create view myView;
drop view myView;
CREATE OR REPLACE VIEW myView as select * from role;
性能问题 因为视图不包含数据,所以每次使用视图时,都必须处理查询执行时所需的任一个检索。
存储过程
MySQL 5添加了对存储过程的支持
-
存储过程的优点
简单、安全、高性能。显然,它们都很重要。 -
缺陷。
(1)一般来说,存储过程的编写比基本SQL语句复杂,编写存储过程需要更高的技能,更丰富的经验。
(2)你可能没有创建存储过程的安全访问权限。许多数据库管理员限制存储过程的创建权限,允许用户使用存储过程,但不允许他们创建存储过程。 -
存储过程操作
(1)create procedure proName();
(2)call proName();
(3)drop procedure proName; -
定义变量
(1)declare定义的变量 相当于一个局部变量 在end之后失效,而且declare只能在begin,end中定义。DROP PROCEDURE IF EXISTS test1; delimiter // CREATE PROCEDURE test1() BEGIN DECLARE n int DEFAULT 1; WHILE n < 100 DO insert into user(username,password,create_time) values('000','1111',now()); set n = n + 1; END WHILE; END // delimiter ; call test1();(2) set @变量名=值
变量不需要声明,MySQL会自动根据值类型来确定类型,这种变量要在其前面加上“@”符号,称之为会话变量,代表在整个会话过程起作用,有点类似于全局变量。set @val = 9; -
案例一
-- 设置mysql分隔符为//,也就意味着,当遇到下一个//时,整体执行SQL语句
DELIMITER //
DROP PROCEDURE if EXISTS ‘test’; # 如果存在test存储过程则删除
CREATE procedure test() # 创建无参存储过程,名称为test
BEGIN
DECLARE i INT; # 申明变量
SET i = 0; # 变量赋值
WHILE i<5 DO # 结束循环的条件: 当i大于5时跳出while循环
INSERT INTO test VALUES(i+11,'test','20'); # 往test表添加数据
SET i = i+1; # 循环一次,i加1
END WHILE; # 结束while循环
SELECT * FROM test; # 查看test表数据
END
// # 结束定义语句
CALL test(); # 调用存储过程
DELIMITER ; # 重新将分隔符设置为;
- 案例二
drop procedure if exists rolePro;
create procedure rolePro(
in roleId int,
out count int,
out roleName varchar(45)
)
BEGIN
-- 查询role的行数
select count(*) from role into count;
-- 查询role表中id等于roleId的角色名称
select name from role where id = roleId into roleName;
END;
set @count= 0;
set @roleName='';
call rolePro(7, @count, @roleName);
select @count, @roleName;
-- 列出所有存储过程
show procedure status;
-- 筛选
show procedure status like 'rolePro';
-- 显示rolePro创建语句
show create procedure rolePro;
游标
游标(cursor)是一个存储在MySQL服务器上的数据库查询,它不是一条SELECT语句,而是被该语句检索出来的结果集。在存储了游标之后,应用程序可以根据需要滚动或浏览其中的数据。
MySQL游标只能用于存储过程(和函数)。
-
mysql游标三个特点:
(1) 敏感:服务器可能会复制结果表,也可能不会
(2)只读:不可更新
(3)不可滚动:只能在一个方向上遍历,不能跳过行 -
游标操作
创建游标:declare 命令游标,并定义相应的select语句create procedure proRole() BEGIN declare roleCusor for select * from role END打开关闭游标:open 游标名;close 游标名
continue语句:declare continue handler for sqlstate ‘02000’ set done = 1;(当sqlstate '02000’出现时,执行set done=1) -
游标案例
drop procedure if exists proRole;
CREATE PROCEDURE proRole ()
BEGIN
-- 定义done变量标识循环结束
DECLARE done boolean DEFAULT 0;
-- 游标范围内变量名称不能和字段名称重复
-- 并且Mysql是不区分大小写的,所以即使使用大写的变量名称,字段名称用小写,它们也会被认为是同一个字符串。
DECLARE var1 INT;
declare var2 int;
DECLARE roleCusor CURSOR FOR SELECT
id, pid
FROM
role;
-- 如果数据循环结束
DECLARE CONTINUE HANDLER FOR SQLSTATE '02000' SET done = 1;
CREATE TABLE
IF NOT EXISTS tempTab (
id INT,
pid int
);
OPEN roleCusor;
REPEAT
FETCH roleCusor INTO var1, var2;
select var1, var2;
INSERT INTO tempTab(id, pid)
VALUES(var1, var2);
UNTIL done END REPEAT;
CLOSE roleCusor;
END;
CALL proRole ();
SELECT
*
FROM
tempTab;
触发器
触发器的支持是在MySQL 5中增加的
- 触发器特性
(1)触发器是MySQL响应DELETE;INSERT;UPDATE语句而自动执行的一条MySQL语句(或位于BEGIN和END语句之间的一组语句),其他MySQL语句不支持触发器
(2)只有表才支持触发器,视图不支持(临时表也不支持)。
(3)mysql 5中触发器名称需要保证在表的范围内唯一;但是为了今后规则可能变得严格,触发器名称应该做到数据库内唯一
(4)触发器不能更新或覆盖。为了修改一个触发器,必须先删除它,然后再重新创建。 - insert触发器
set @val='';
-- 创建触发器
create trigger newrole after insert on role for each row select 'role added' into @val;
select @val;
-- 触发条件,执行触发器
INSERT INTO role (`id`, `pid`, `name`, `tips`, `extr`) VALUES ('71', '1', ' 管 ', '测试', '1');
-- 删除触发器
drop trigger newrole;
在INSERT触发器代码内,可引用一个名为NEW的虚拟表,访问被插入的行。对于AUTO_INCREMENT列,NEW在INSERT执行之前包含0,在INSERT执行之后包含新的自动生成值。
create trigger newrole after insert on role for each row select NEW.id into @val;
- delete触发器
在DELETE触发器代码内,你可以引用一个名为OLD的虚拟表,访问被删除的行;OLD中的值全都是只读的,不能更新。
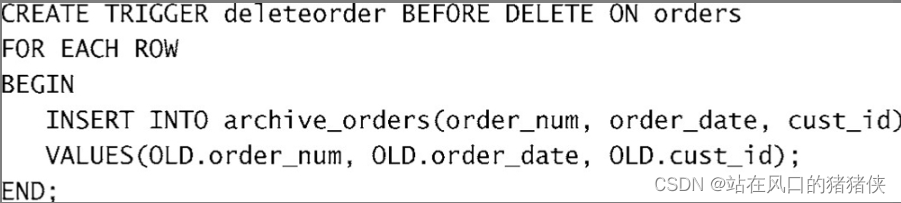
- update 触发器
❑ 在UPDATE触发器代码中,你可以引用一个名为OLD的虚拟表访问以前(UPDATE语句前)的值,引用一个名为NEW的虚拟表访问新更新的值;❑ 在BEFORE UPDATE触发器中,NEW中的值可能也被更新(允许更改将要用于UPDATE语句中的值);❑ OLD中的值全都是只读的,不能更新。

事务处理
- 术语
(1)事务(transaction)指一组SQL语句;
(2)回退(rollback)指撤销指定SQL语句的过程;
(3)提交(commit)指将未存储的SQL语句结果写入数据库表;
(4)保留点(savepoint)指事务处理中设置的临时占位符(place-holder),你可以对它发布回退(与回退整个事务处理不同)。
事务处理用来管理INSERT、UPDATE和DELETE语句。你不能回退SELECT语句。(这样做也没有什么意义。)你不能回退CREATE或DROP操作。事务处理块中可以使用这两条语句,但如果你执行回退,它们不会被撤销。
- 事务操作
-- 开启事务
start transaction;
select count(*) from role;
savepoint p0;
INSERT INTO role (`id`, `pid`, `name`, `tips`, `extr`) VALUES ('84', '1', ' 管 ', '测试', '1');
savepoint p1;
INSERT INTO role (`id`, `pid`, `name`, `tips`, `extr`) VALUES ('85', '1', ' 管 ', '测试', '1');
-- 回滚事务到p1
rollback to p1;
select count(*) from role;
-- 整体回滚事务
rollback;
select count(*) from role;
-- 提交事务
commit;
navicat快捷键
- 鼠标三击选中所在行
- ctrl + shift + r(执行选中的sql)
- ctrl + r (运行所有sql)
- shift + 上(下):选中多行
- shirt + 左(右):左右光标移动选中内容
- ctrl + l 删除所在行
- shift + home: 选中光标到行首内容
- shift + end: 选中光标到行尾内容
- ctrl + / 注释所在行
- ctrl + w (关闭当前窗口)














 614
614











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









