参考:
http://www.cnblogs.com/hunttown/p/5452159.html
http://www.cnblogs.com/hunttown/p/5452138.html
http://www.aboutyun.com/thread-9115-1-1.html
涉及到的问题:
1. hadoop集群依赖zookeeper集群.
1. 下载hadoop(cdh)和Zookeeper(cdh).
zookeeper-3.4.5-cdh5.4.5.tar.gz, hadoop-2.6.0-cdh5.4.5.tar.gz
2. 搭建zookeeper集群.
server.1=tsbyacehadoop1:2888:3888
server.2=tsbyacehadoop2:2888:3888
server.3=tsbyacehadoop3:2888:3888
3. 配置hadoop.
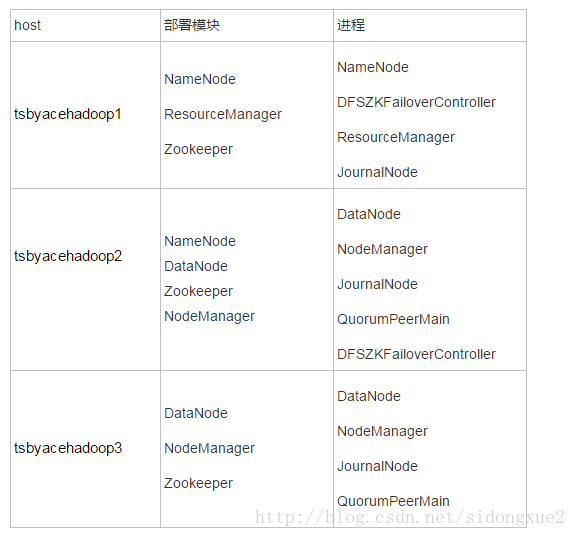
搭建的集群包括3台hadoop服务器, 集群规划如下:
31. 关闭防火墙.
[root@tsbyacehadoop1 hadoop]# service iptables stop
iptables: Setting chains to policy ACCEPT: filter [ OK ]
iptables: Flushing firewall rules: [ OK ]
iptables: Unloading modules: [ OK ]
[root@tsbyacehadoop1 hadoop]# service iptables status
iptables: Firewall is not running.
[root@tsbyacehadoop1 hadoop]#
32. 配置ssh互信.
为集群中的每台服务器生成秘钥,并且拷贝到集群所有的服务器上, 注意: 包括自己。
[root@tsbyacehadoop1 hadoop]# ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
/root/.ssh/id_rsa already exists.
Overwrite (y/n)? y
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
13:a8:21:ae:45:4c:eb:d5:e8:e4:9f:09:40:30:10:29 root@tsbyacehadoop1
The key's randomart image is:
+--[ RSA 2048]----+
|*+o |
|E= . o . |
|. * = o . |
| + B o . |
| + = S |
| o o o . |
|. + |
| |
| |
+-----------------+
[root@tsbyacehadoop1 hadoop]# ssh-copy-id -i ~/.ssh/id_rsa.pub "-p 36000 root@tsbyacehadoop2"
The authenticity of host '[tsbyacehadoop2]:36000 ([10.0.1.216]:36000)' can't be established.
RSA key fingerprint is 23:6b:d3:a7:ca:ff:fc:42:da:bc:c5:a8:5e:8b:4f:d4.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '[tsbyacehadoop2]:36000,[10.0.1.216]:36000' (RSA) to the list of known hosts.
root@tsbyacehadoop2's password:
Now try logging into the machine, with "ssh '-p 36000 root@tsbyacehadoop2'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
[root@tsbyacehadoop1 hadoop]#
配置完成后, 就可以通过ssh -p 36000 ${host_name},在不输入密码的情况下,直接连接其他服务器了.
同时还可以通过如下指令查看当前机器包含哪些服务器的秘钥.
[root@tsbyacehadoop1 sbin]# cat /root/.ssh/known_hosts
[tsbyacehadoop2]:36000,[10.0.1.216]:36000 ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAovmJx91swyx3l0B2tLo397Y2BCsc6KTff0WOKQW8nEfkFTy2e/D2BV2rLmF8vPd5kzdrlDqFNODribwW98KmzSC7/wAymqHxy3ChtTSVBV9CT1tkUBIJ3eC48j2Z7Yz3y6KJ4LyhytLmwbtZHqLQMQb2hk+kF49RFc6x8nAO1l153CBmipKw9hPeuM+5hHlRXTZqOucHIgqX+H9rFU+7dALbruzhtgpRu76tx3+aa9yQrJOWjwbqEoQDzzyA04jT5B0+W4hppLZlJt+p5lr3FhVl1mWgjNbKumx/I60BEnv4dNsx8bTU00cb39Kmo+wVk4PU9vjFpZu+edErF2fPEw==
[tsbyacehadoop3]:36000,[10.0.1.221]:36000 ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAovmJx91swyx3l0B2tLo397Y2BCsc6KTff0WOKQW8nEfkFTy2e/D2BV2rLmF8vPd5kzdrlDqFNODribwW98KmzSC7/wAymqHxy3ChtTSVBV9CT1tkUBIJ3eC48j2Z7Yz3y6KJ4LyhytLmwbtZHqLQMQb2hk+kF49RFc6x8nAO1l153CBmipKw9hPeuM+5hHlRXTZqOucHIgqX+H9rFU+7dALbruzhtgpRu76tx3+aa9yQrJOWjwbqEoQDzzyA04jT5B0+W4hppLZlJt+p5lr3FhVl1mWgjNbKumx/I60BEnv4dNsx8bTU00cb39Kmo+wVk4PU9vjFpZu+edErF2fPEw==
[tsbyacehadoop1]:36000,[10.0.1.215]:36000 ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAovmJx91swyx3l0B2tLo397Y2BCsc6KTff0WOKQW8nEfkFTy2e/D2BV2rLmF8vPd5kzdrlDqFNODribwW98KmzSC7/wAymqHxy3ChtTSVBV9CT1tkUBIJ3eC48j2Z7Yz3y6KJ4LyhytLmwbtZHqLQMQb2hk+kF49RFc6x8nAO1l153CBmipKw9hPeuM+5hHlRXTZqOucHIgqX+H9rFU+7dALbruzhtgpRu76tx3+aa9yQrJOWjwbqEoQDzzyA04jT5B0+W4hppLZlJt+p5lr3FhVl1mWgjNbKumx/I60BEnv4dNsx8bTU00cb39Kmo+wVk4PU9vjFpZu+edErF2fPEw==
......(略)......
同时注意: 为了安全,可以为hadoop创建专门的用户.
useradd hadoopuser
passwd hadoopuser
su - hadoopuser
补充:
配置ssh互信的目的是: name node节点支持远程启动其他服务器的hadoop程序。
33. 配置hadoop-env.sh文件.
# The java implementation to use.
#export JAVA_HOME=$JAVA_HOME
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_73
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.6.0-cdh5.4.5
export PATH=$PATH:$HADOOP_HOME/bin
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_SSH_OPTS="-p 36000"
注意: 这里的JAVA_HOME需要配置为全路径, 不能用$JAVA_HOME, 否则会报错误, 下面会提到.
还有就是export HADOOP_SSH_OPTS="-p 36000"里的端口必须配置正确, 否则会有问题.
34. 配置hdfs-site.xml文件.
[root@master hadoop]# cat hdfs-site.xml
...(略)...
<configuration>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
<description>
Comma-separated list of nameservices.
</description>
</property>
<property>
<name>dfs.datanode.address</name>
<value>0.0.0.0:50010</value>
<description>
The datanode server address and port for data transfer.
If the port is 0 then the server will start on a free port.
</description>
</property>
<property>
<name>dfs.datanode.http.address</name>
<value>0.0.0.0:50075</value>
<description>
The datanode http server address and port.
If the port is 0 then the server will start on a free port.
</description>
</property>
<property>
<name>dfs.datanode.ipc.address</name>
<value>0.0.0.0:50020</value>
<description>
The datanode ipc server address and port.
If the port is 0 then the server will start on a free port.
</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/root/toushibao/data/namenode</value>
<description>Determines where on the local filesystem the DFS name node should store the name table.If this is a comma-delimited list of directories,then name table is replicated in all of the directories,for redundancy.</description>
<final>true</final>
</property>
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:/root/toushibao/data/hdfs/edits</value>
<description>Determines where on the local filesystem the DFS name node
should store the transaction (edits) file. If this is a comma-delimited list
of directories then the transaction file is replicated in all of the
directories, for redundancy. Default value is same as dfs.namenode.name.dir
</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/root/toushibao/data/datanode</value>
<description>Determines where on the local filesystem an DFS data node should store its blocks.If this is a comma-delimited list of directories,then data will be stored in all named directories,typically on different devices.Directories that do not exist are ignored.
</description>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permission</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.hdfs-blocks-metadata.enabled</name>
<value>true</value>
<description>
Boolean which enables backend datanode-side support for the experimental DistributedFileSystem#getFileVBlockStorageLocations API.
</description>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
<description>
If "true", enable permission checking in HDFS.
If "false", permission checking is turned off,
but all other behavior is unchanged.
Switching from one parameter value to the other does not change the mode,
owner or group of files or directories.
</description>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
<description></description>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>master:9000</value>
<description></description>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>slave1:9000</value>
<description></description>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>master:50070</value>
<description></description>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>slave1:50070</value>
<description></description>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;slave1:8485;slave2:8485;/test</value>
<description></description>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/root/toushibao/data/journaldata/jn</value>
<description></description>
</property>
<property>
<name>dfs.journalnode.rpc-address</name>
<value>0.0.0.0:8485</value>
</property>
<property>
<name>dfs.journalnode.http-address</name>
<value>0.0.0.0:8480</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
<description></description>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/bin/true)</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>10000</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
<description>
Whether automatic failover is enabled. See the HDFS High
Availability documentation for details on automatic HA
configuration.
</description>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181</value>
<description></description>
</property>
<property>
<name>dfs.blocksize</name>
<value>64m</value>
<description>
The default block size for new files, in bytes.
You can use the following suffix (case insensitive):
k(kilo), m(mega), g(giga), t(tera), p(peta), e(exa) to specify the size (such as 128k, 512m, 1g, etc.),
Or provide complete size in bytes (such as 134217728 for 128 MB).
</description>
</property>
<property>
<name>dfs.datanode.max.transfer.threads</name>
<value>8192</value>
</property>
<property>
<name>dfs.client.socket-timeout</name>
<value>600000</value>
</property>
</configuration>
35. 配置core-site.xml文件.
[root@tsbyacehadoop1 hadoop]# cat core-site.xml
...(略)...
<configuration>
<!-- 如下的value来自hdfs-site.xml文件-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
<description>The name of the default file system. A URI whose
scheme and authority determine the FileSystem implementation. The
uri's scheme determines the config property (fs.SCHEME.impl) naming
the FileSystem implementation class. The uri's authority is used to
determine the host, port, etc. for a filesystem.</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>io.native.lib.available</name>
<value>true</value>
<description>Should native hadoop libraries, if present, be used.</description>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.Lz4Codec,org.apache.hadoop.io.compress.SnappyCodec</value>
<description>A comma-separated list of the compression codec classes that can
be used for compression/decompression. In addition to any classes specified
with this property (which take precedence), codec classes on the classpath
are discovered using a Java ServiceLoader.</description>
</property>
</configuration>
36. 配置yarn-env.sh文件.
在yarn-env.sh文件的开头加入: export JAVA_HOME=/usr/local/jdk/jdk1.8.0_73
37. 配置yarn-site.xml文件.
注意: yarn也可以配置为高可用的.
[root@tsbyacehadoop1 hadoop]# cat yarn-site.xml
...(略)...
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>6144</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>6144</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>tsbyacehadoop1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>tsbyacehadoop1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>tsbyacehadoop1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>tsbyacehadoop1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>tsbyacehadoop1:8088</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-vcores</name>
<value>1</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>8</value>
</property>
<property>
<name>yarn.resourcemanager.am.max-attempts</name>
<value>3</value>
</property>
<property>
<name>yarn.nm.liveness-monitor.expiry-interval-ms</name>
<value>60000</value>
</property>
<property>
<name>yarn.nodemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.address</name>
<value>0.0.0.0:45454</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>3.5</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
</configuration>
38. 配置slaves文件.
[root@tsbyacehadoop1 hadoop]# cat slaves
tsbyacehadoop2
tsbyacehadoop3
39.分发程序.
修改完一台hadoop集群的所有配置后, scp到其他两台hadoop服务器上。
4. 启动hadoop集群.
41. 启动JournalNode.
[root@tsbyacehadoop1 sbin]# ./hadoop-daemon.sh start journalnode
starting journalnode, logging to /usr/local/hadoop/hadoop-2.6.0-cdh5.4.5/logs/hadoop-root-journalnode-tsbyacehadoop1.out
[root@tsbyacehadoop1 sbin]# jps
2217 JournalNode
2268 Jps
1582 QuorumPeerMain
停止journalnode.
[root@tsbyacehadoop1 sbin]# ./hadoop-daemon.sh stop journalnode
stopping journalnode
42. NameNode格式化.
[root@tsbyacehadoop1 bin]# ./hdfs namenode -format
16/11/24 17:23:54 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = tsbyacehadoop1/10.0.1.215
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.6.0-cdh5.4.5
STARTUP_MSG: classpath = /usr/local/hadoop/hadoop-2.6.0-cdh5.4.5/etc/hadoop
......(略)......
格式化结束后, 将元数据同步到tsbyacehadoop2(注意: namenode只安装在tsbyacehadoop1和tsbyacehadoop2上).
[root@tsbyacehadoop1 bin]# scp -P 36000 -r /data/hadoop root@tsbyacehadoop2:/data/hadoop
VERSION 100% 155 0.2KB/s 00:00
in_use.lock 100% 19 0.0KB/s 00:00
seen_txid 100% 2 0.0KB/s 00:00
VERSION 100% 203 0.2KB/s 00:00
fsimage_0000000000000000000.md5 100% 62 0.1KB/s 00:00
fsimage_0000000000000000000 100% 351 0.3KB/s 00:00
seen_txid 100% 2 0.0KB/s 00:00
VERSION 100% 203 0.2KB/s 00:00
[root@tsbyacehadoop1 bin]#
43. 初始化zkfc.
注意: 如果hdfs-site.xml文件中的zookeeper配置错误的话,这步会失败.
[root@tsbyacehadoop1 bin]# ./hdfs zkfc -formatZK
16/11/24 17:25:32 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/11/24 17:25:32 INFO tools.DFSZKFailoverController: Failover controller configured for NameNode NameNode at tsbyacehadoop1/10.0.1.215:9000
16/11/24 17:25:32 INFO zookeeper.ZooKeeper: Client environment:zookeeper.version=3.4.5-cdh5.4.5--1, built on 08/12/2015 21:04 GMT
16/11/24 17:25:32 INFO zookeeper.ZooKeeper: Client environment:host.name=tsbyacehadoop1
44. 启动集群.
注意: ./start-all.sh指令已经不建议使用了, 替代的是start-dfs.sh and start-yarn.sh.
[root@tsbyacehadoop1 sbin]# ./start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Hadoop安装配置完成后, 启动时报Error: JAVA_HOME is not set and could not be found.
[root@tsbyacehadoop1 sbin]# ./start-dfs.sh
16/11/24 17:27:06 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [tsbyacehadoop1 tsbyacehadoop2]
The authenticity of host '[tsbyacehadoop1]:36000 ([10.0.1.215]:36000)' can't be established.
RSA key fingerprint is 23:6b:d3:a7:ca:ff:fc:42:da:bc:c5:a8:5e:8b:4f:d4.
Are you sure you want to continue connecting (yes/no)? tsbyacehadoop2: Error: JAVA_HOME is not set and could not be found.
解决办法: 修改/etc/hadoop/hadoop-env.sh中设JAVA_HOME, 应当使用绝对路径
export JAVA_HOME=$JAVA_HOME //错误.
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_73 //正确.
修改完集群中的所有hadoop服务器后, 再次启动集群,报如下错误:
[root@tsbyacehadoop1 sbin]# ./start-dfs.sh
16/11/24 17:33:06 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [tsbyacehadoop1 tsbyacehadoop2]
The authenticity of host '[tsbyacehadoop1]:36000 ([10.0.1.215]:36000)' can't be established.
RSA key fingerprint is 23:6b:d3:a7:ca:ff:fc:42:da:bc:c5:a8:5e:8b:4f:d4.
Are you sure you want to continue connecting (yes/no)? tsbyacehadoop2: starting namenode, logging to /usr/local/hadoop/hadoop-2.6.0-cdh5.4.5/logs/hadoop-root-namenode-tsbyacehadoop2.out
tsbyacehadoop1: Host key verification failed.
解决方法: 原因是tsbyacehadoop1连接自己时需要密码,所以也要将自己的公钥写到known_hosts文件中.
再次启动, 启动成功了.可以通过界面访问: http://10.0.1.215:50070
45.启动YARN.
通过 ./start-yarn.sh指令启动yarn,发现yarn没有启动成功,通过查看/usr/local/hadoop/hadoop-2.6.0-cdh5.4.5/logs日志, 发现如下错误:
2016-11-2511:10:42,745 INFO org.apache.hadoop.service.AbstractService: Service org.apache.hadoop.yarn.server.resourcemanager.AdminService failed in state STARTED; cause: org.apache.hadoop.yarn.exceptions.YarnRuntimeException: java.io.IOException: Failed on local exception: java.net.SocketException: Unresolved address; Host Details : local host is: "tsbyacehaoop1"; destination host is: (unknown):0; org.apache.hadoop.yarn.exceptions.YarnRuntimeException: java.io.IOException: Failed on local exception: java.net.SocketException: Unresolved address; Host Details : local host is: "tsbyacehaoop1"; destination host is: (unknown):0;
at org.apache.hadoop.yarn.factories.impl.pb.RpcServerFactoryPBImpl.getServer(RpcServerFactoryPBImpl.java:139)
at org.apache.hadoop.yarn.ipc.HadoopYarnProtoRPC.getServer(HadoopYarnProtoRPC.java:65)
at org.apache.hadoop.yarn.ipc.YarnRPC.getServer(YarnRPC.java:54)
解决方案是: 修改yarn-site.xml文件中的错误配置.
重新启动yarn,没有问题了.
[root@tsbyacehadoop1 sbin]# ./start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop/hadoop-2.6.0-cdh5.4.5/logs/yarn-root-resourcemanager-tsbyacehadoop1.outtsbyacehadoop2: nodemanager running as process 5542. Stop it first.
tsbyacehadoop3: nodemanager running as process 3786. Stop it first.
[root@tsbyacehadoop1 sbin]# jps5856 NameNode
9969 Jps
9715 ResourceManager
3668 JournalNode
6165 DFSZKFailoverController
1582 QuorumPeerMain
可以通过界面访问: http://10.0.1.215:8088

























 5089
5089

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









