









 在阿里云将COLA纳入Java应用架构选项之际,作者回顾并优化了COLA框架,摒弃了不必要的复杂性,遵循奥卡姆剃刀原理,简化了设计,提升了可读性和维护性。
在阿里云将COLA纳入Java应用架构选项之际,作者回顾并优化了COLA框架,摒弃了不必要的复杂性,遵循奥卡姆剃刀原理,简化了设计,提升了可读性和维护性。
最近,阿里云的同学告诉我,COLA作为应用架构,已经被选入阿里云的Java应用初始化的应用架构选项之一。
This is really something,于是,在这个里程碑节点上,我开始回过头来,重新审视COLA一路走来的得与失。
COLA作为一种架构思想无疑是成功的。但是作为框架,个人感觉有点鸡肋之嫌。 特别是在简洁性上做的不好,感觉做了不少画蛇添足的事情。
试想一下,有些功能我作为作者都很少去使用,我实在想不到,它为什么还有存在的理由。
基于上面的思考,我做了这一次COLA 2.0 到 COLA 3.0的升级。在本次升级中,我没有增加任何新的功能,而是尽量多删减了一些概念和功能。让COLA可以更加纯粹的focus在应用架构上,而不是框架支持和架构约束上。
支持我做这些决策的背后原因只有一个——奥卡姆剃刀原理。
奥卡姆剃刀原理
奥卡姆剃刀原理,是指如无必要,勿增实体(Entities should not be multiplied unnecessarily),即“简单有效原理”。正如奥卡姆在《箴言书注》2卷15题说“切勿浪费较多东西去做,用较少的东西,同样可以做好的事情。”

在具体的应用过程中,我们可以遵循以下原则去做事情:
“如果同一个现象有n种理论,最简单的那个便是最正确的。能用n做好事情,那就不要有第n+1个动作。”
比如,《皇帝的新衣》的皇帝到底穿没穿衣服呢?如果你在现场,你很有可能就是大臣之一。

如果懂得了奥卡姆剃刀原理,可以用逻辑手段,判断谁是真理。
第一种逻辑如下:假设皇帝是真的穿了衣服→假设愚蠢的人看不见→假设你就是愚蠢的人→所以你没看见皇帝穿衣服。
第二种逻辑如下:假设皇帝没穿衣服→所以你没看见皇帝穿衣服。
同样看见光身子的皇帝,第二种解释简单明了。而第一种解释,可能正因为它是错误的,就需要更多假设来补救漏洞,就像说谎圆谎一样。
真相不需要伪装掩饰,简单明了。
再比如,地心说和日心说,托勒密的地心说模型是一个本轮均轮模型。人们可以按照这个模型,定量计算行星的运动,据此推测行星所在的位置。
到了中世纪后期随着观察仪器的不断改进,人们能够更加精确地测量出行星的位置和运动,观测到行星实际位置与这个模型的计算结果存在偏差,一开始还能勉强应付,后来小本轮增加到八十多个,却仍然不能精确地计算出行星的准确位置。

1543年,波兰天文学家哥白尼在临终时发表了一部具有历史意义的著作—《天体运行论》。这个理论体系提出了一个明确的观点:太阳是宇宙的中心,一切行星都在围绕太阳旋转。该理论认为,地球也是行星之一,它一方面像陀螺一样自转,一方面又和其他行星一样围绕太阳转动。
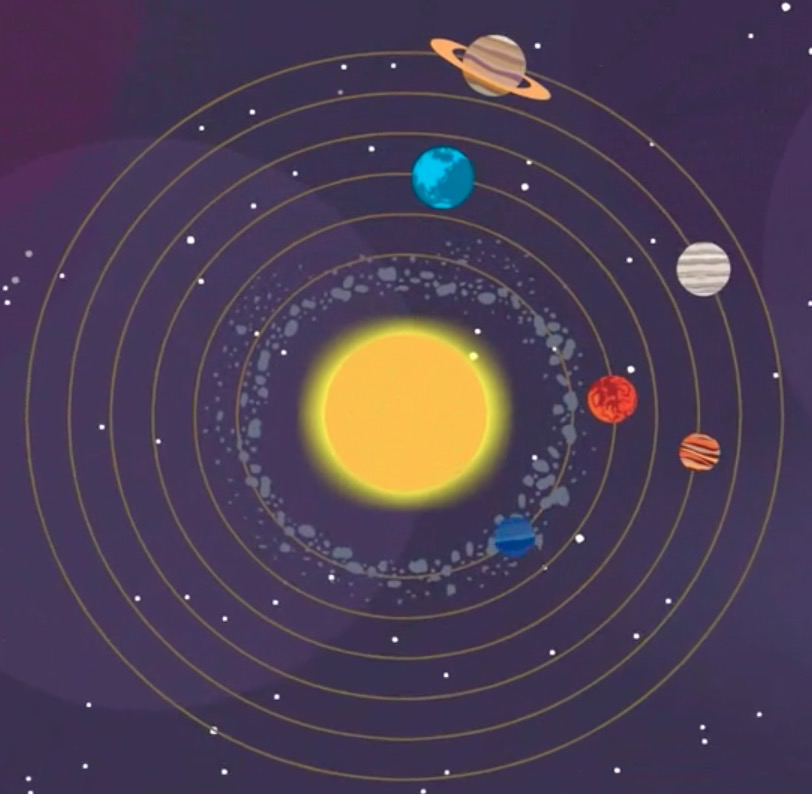
哥白尼的计算不仅结构严谨,而且计算简单,与已经加到八十余个圈的地心说相比,哥白尼的计算与实际观测资料能更好地吻合。因此,地心说最终被日心说所取代。
设计中的弯弯绕
深入考察一下,我们系统中,类似于“地心说”这样的弯弯绕的设计,实在是不在少数。
从系统架构的角度看,有些弯弯绕是因为系统边界划分不合理,导致职责不清,依赖混乱。
从应用架构的角度看,有些弯弯绕是因为过度设计,为了追求所谓的灵活性和可扩展性,使用了不恰当的设计。导致本来可以直观呈现的代码逻辑,被各种包装,各种隐藏,各种转发… 无形中极大的阻碍了代码的可读性和可理解性,增加了维护成本。
举个例子,我看过无数的业务系统,喜欢拿业务流程编排说事情。因此,在业务系统中,可以看到各种五花八门的“弯弯绕设计”。
比如,在一个业务系统中,我看到了如下的pipeline设计。这个设计的本质是说把一个复杂的业务操作进行结构化拆解为多个小的处理单元。
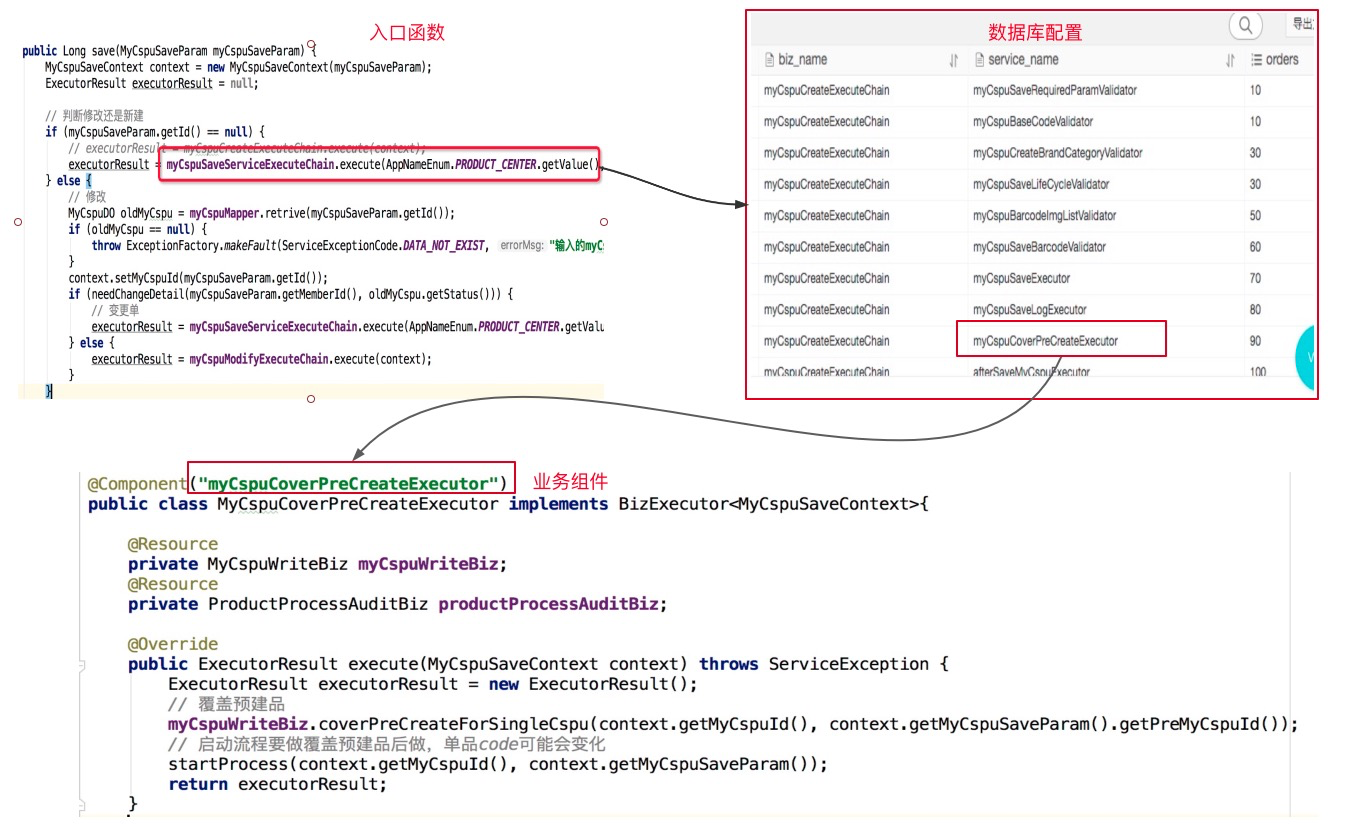
拆解是正确的,但是这种处理方式显然不够“奥卡姆”(关于更多结构化分解的内容,可以看我的另一篇文章)。作为维护人员,进入“入口函数”后,还要去查数据库,然后才能知道哪些组件被调用了,太绕了,不够直观,也不简洁。
同样的逻辑,按照下面的方式写不香吗?
public class CreateCSPUExecutor {
@Resource
private InitContextStep initContextStep;
@Resource
private CheckRequiredParamStep checkRequiredParamStep;
@Resource
private CheckUnitStep checkUnitStep;
@Resource
private CheckExpiringDateStep checkExpiringDateStep;
@Resource
private CheckBarCodeStep checkBarCodeStep;
@Resource
private CheckBarCodeImgStep checkBarCodeImgStep;
@Resource
private CheckBrandCategoryStep checkBrandCategoryStep;
@Resource
private CheckProductDetailStep checkProductDetailStep;
@Resource
private CheckSpecImgStep checkSpecImgStep;
@Resource
private CreateCSPUStep createCSPUStep;
@Resource
private CreateCSPULogStep createCSPULogStep;
@Resource
private SendCSPUCreatedEventStep sendCSPUCreatedEventStep;
public Long create(MyCspuSaveParam myCspuSaveParam){
SaveCSPUContext context = initContextStep.initContext(myCspuSaveParam);
checkRequiredParamStep.check(context);
checkUnitStep.check(context);
checkExpiringDateStep.check(context);
checkBarCodeStep.check(context);
checkBarCodeImgStep.check(context);
checkBrandCategoryStep.check(context);
checkProductDetailStep.check(context);
checkSpecImgStep.check(context);
createCSPUStep.create(context);
createCSPULogStep.log(context);
sendCSPUCreatedEventStep.sendEvent(context);
return context.getCspu().getId();
}
}
这种写法简单直观,易维护,与前一种方式相比,具有同样的组件复用性。符合奥卡姆剃刀的精神,相比较而言,前面那种弯弯绕设计,虽然看起来有点设计感,带来了一点点OCP的好处。但是无端增加了理解和认知成本,孰优孰劣,不难分辨。
COLA 3.0 升级
做了这么长的铺垫,终于到了批斗COLA中“弯弯绕设计”的时候了。
去掉Command
在COLA的初始阶段,因为受到CQRS的影响,于是想到了使用命令模式来处理用户请求。设计的初衷是想通过框架,一方面强制约束Command和Query的处理方式,另一方面把Service里面的逻辑,强制拆分到CommandExecutor中去,防止Service膨胀过快。
和上面介绍过的pipeline设计类似,这种设计有点绕,不够直观,如下所示:
public class MetricsServiceImpl implements MetricsServiceI{
@Autowired
private CommandBusI commandBus;
@Override
public Response addATAMetric(ATAMetricAddCmd cmd) {
return commandBus.send(cmd);
}
@Override
public Response addSharingMetric(SharingMetricAddCmd cmd) {
return commandBus.send(cmd);
}
@Override
public Response addPatentMetric(PatentMetricAddCmd cmd) {
return commandBus.send(cmd);
}
@Override
public Response addPaperMetric(PaperMetricAddCmd cmd) {
return commandBus.send(cmd);
}
}
看起来还挺干净的,可是ATAMetricAddCmd到底是被哪个Executor处理的呢,不直观。我还要去理解CommandBus,以及CommandBus是如何注册Executor的。无形中增加了认知成本,不好。
既然这样,为何不用奥卡姆剃刀把这个CommandBus剔除呢。如下所示,去除CommandBus之后,代码是不是直观了很多,唯一的损失是我们会失去框架层面提供的Interceptor功能,然而,Interceptor正是我下一个要动刀的地方。
public class MetricsServiceImpl implements MetricsServiceI{
@Resource
private ATAMetricAddCmdExe ataMetricAddCmdExe;
@Resource
private SharingMetricAddCmdExe sharingMetricAddCmdExe;
@Resource
private PatentMetricAddCmdExe patentMetricAddCmdExe;
@Resource
private PaperMetricAddCmdExe paperMetricAddCmdExe;
@Override
public Response addATAMetric(ATAMetricAddCmd cmd) {
return ataMetricAddCmdExe.execute(cmd);
}
@Override
public Response addSharingMetric(SharingMetricAddCmd cmd) {
return sharingMetricAddCmdExe.execute(cmd);
}
@Override
public Response addPatentMetric(PatentMetricAddCmd cmd) {
return patentMetricAddCmdExe.execute(cmd);
}
@Override
public Response addPaperMetric(PaperMetricAddCmd cmd) {
return paperMetricAddCmdExe.execute(cmd);
}
}
去掉Interceptor
当时设计Interceptor,是因为有CommandBus作为基础,为了更好的利用命令模式带来的好处,便添加了Interceptor功能。其本质是一个AOP处理。
鉴于Spring的AOP功能已经很完善了,这个设计也是有点鸡肋。事实证明,大家在使用COLA框架的时候,很少会使用Interceptor,包括我自己也是一样。既然如此,剔除也罢。
去掉Convertor、Validator、Assembler
关于命名的重要性,这里就不赘述了。当时想着是否能从框架层面,规范一下一些常用功能的命名。但是在实际使用中,发现这个想法也是有些过于理想化了。
我记得,在团队实践COLA的初期,还经常为什么是Convertor(转换器),什么是Assembler(组装器)的事情,争论不休。
后面我仔细想了想,命名虽然很重要,但其作用域最多也就是一个团队规范,你校验器是叫Validator还是Checker并没有什么本质区别,团队自己定义就好了。尝试从框架层面去解决团队约定问题,其效果不会太好,因此也果断挥刀剔除。
类扫描优化
业务身份和扩展点的思想,是TMF的核心理念,也是阿里业务中台的进行多业务支持的核心方法论。
COLA致力于提供一种轻量级的扩展实现方式,因此该功能得以在奥卡姆的屠刀下得以保存。因为COLA的扩展点设计是借鉴了中台的TMF,因此在前面的设计中,其类扫描方案是直接照搬TMF的做法。
实际上,TMF的类扫描方案对COLA来说有点多余。因为COLA本身就是架设在Spring的基础之上,而Spring又是建立在类扫描的基础之上。因此,我们完全可以复用Spring的类扫描,没必要自己写一套。
在原生的Spring中,至少有3种方式可以获取到用户自定义Annotation的Bean,最简洁的是通过ListableBeanFactory.getBeansWithAnnotation方法,或者使用ClassPathScanningCandidateComponentProvider进行扫包。
在这次改版中,我选用的是getBeansWithAnnotation方法,主要是为了获取@Extension的Bean,用来实现扩展点功能,废弃了原来的TMF类扫描实现。
总结
触发这次升级的动机,主要是因为,自己在实践COLA的过程中,的确发现有些华而不实的功能。在COLA作为阿里云的基础应用架构,其影响力越来越大的时候,我有责任给到大家一个正确的引导——去伪存真,简洁有效,而不是引入更多的复杂度。
实际上,COLA是有两部分组成的:
一方面COLA是一种架构思想,是整合了洋葱圈架构、适配器架构、DDD、整洁架构、TMF等架构思想的一种应用架构。

在这次升级中,架构思想部分基本没有变化,唯一一点是因为去除了Command概念,因此CQRS也成了可选项,而不再是一种强要求。
另一方面COLA也是框架组件,通过这次升级,我使用奥卡姆剃刀砍掉了绝大部分的组件能力,仅仅保留了扩展点功能。其用意是不希望COLA作为框架给到应用开发者太多的约束,这不符合简单有效的风格。
所以,总结下来,与其说这是一次升级,不如说它是功能“降级”,是在做减法。
但我相信,减法可以让COLA更加符合奥卡姆精神,帮助COLA轻装上阵,走的更远。
COLA开源地址:https://github.com/alibaba/COLA

















 1768
1768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









