







这次 我们来爬一个图片网站 然后保存到数据库
目标 我们选择 http://www.win4000.com/zt/fengjing.html
先打开网站看一下
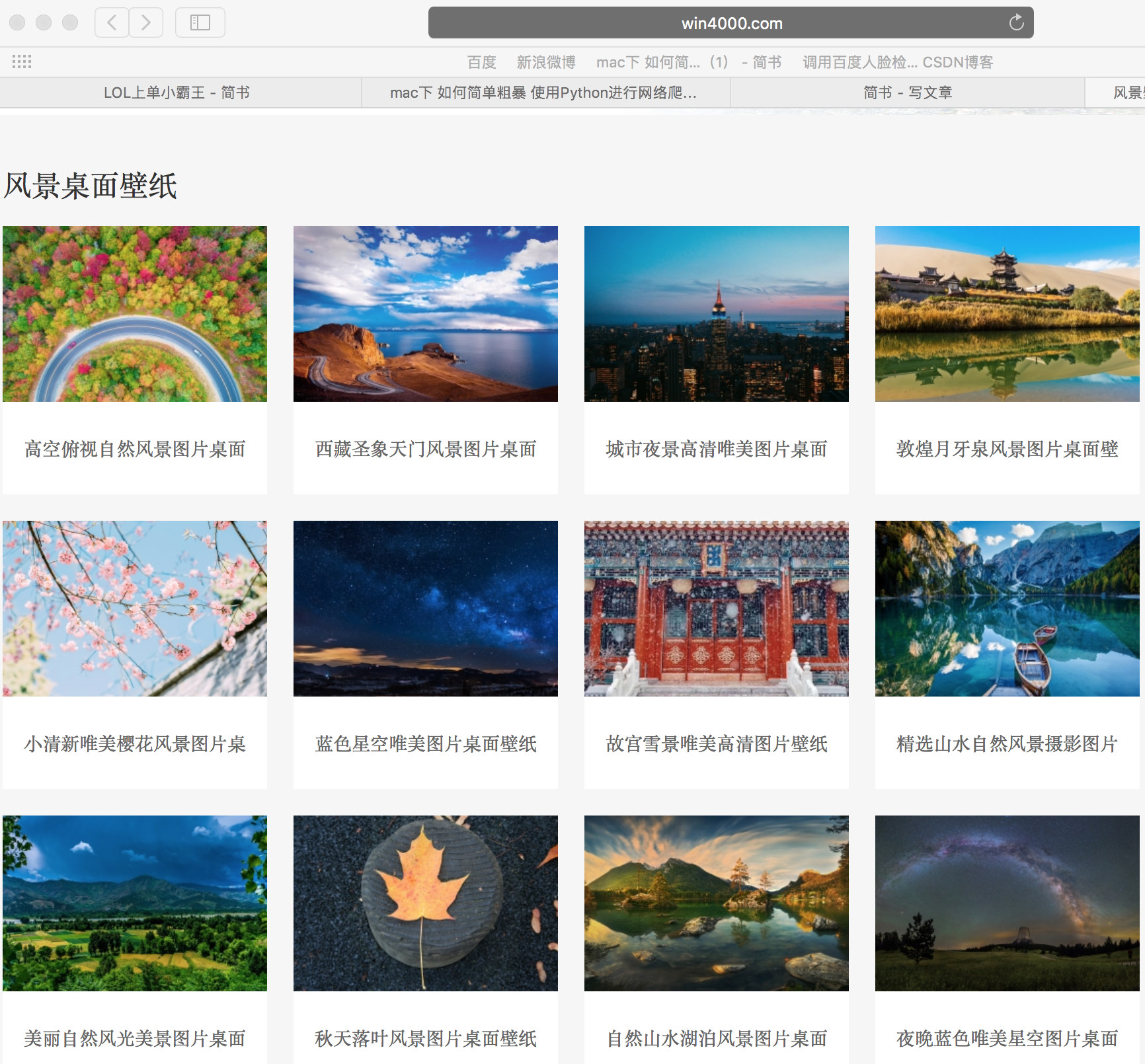
我们的目的 就是抓风景桌面的壁纸 但这些都是缩略图 大图 在点击后的详情页里面
我们再次点击 一张素略图 看看

基本上 每一个缩略图都对应8-9张大图
那么 我们的目的很明确了 根据每个缩略图 找到对应的大图 并且下载下来
回到 http://www.win4000.com/zt/fengjing.html 检查元素查看网页 源代码
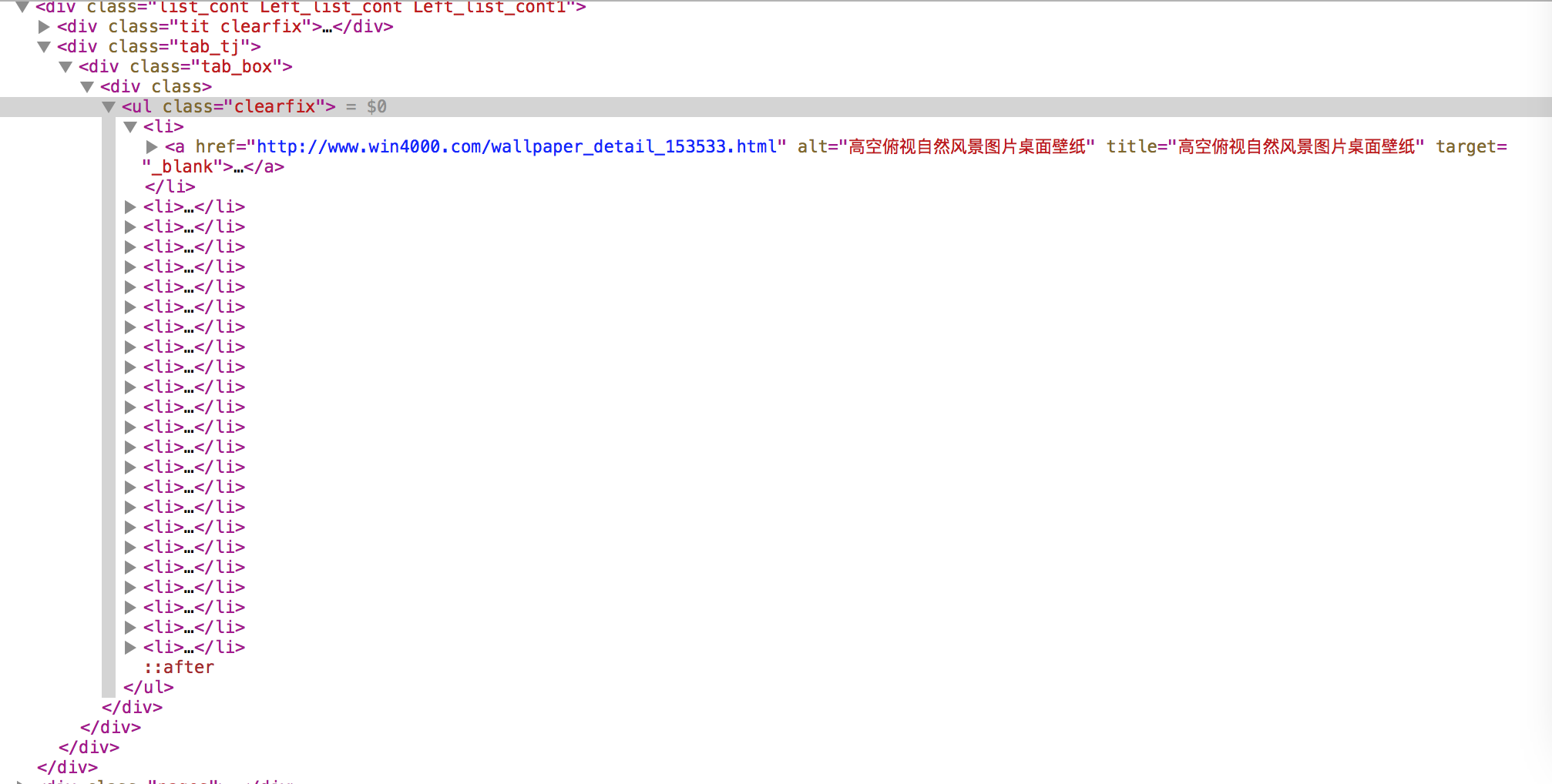
这个简直太简单了 直接用 BeautifulSoup获得每一个缩略图对应的详情
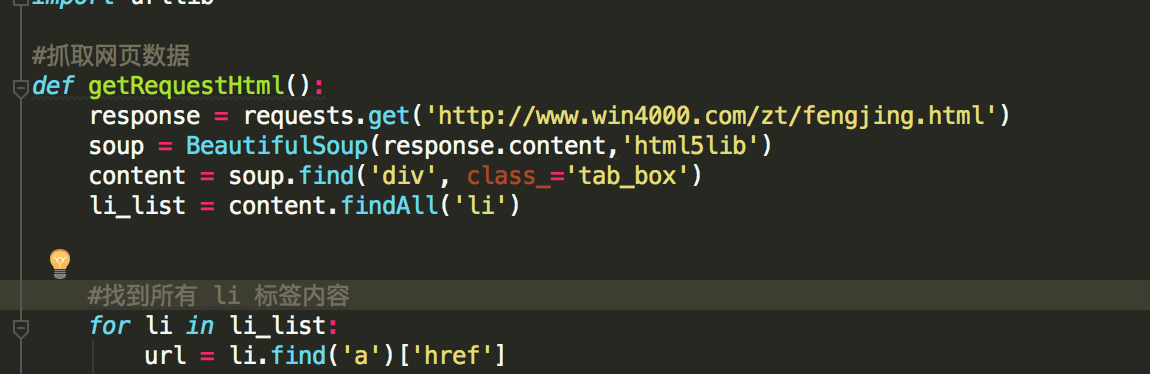
再来查看对应大图的
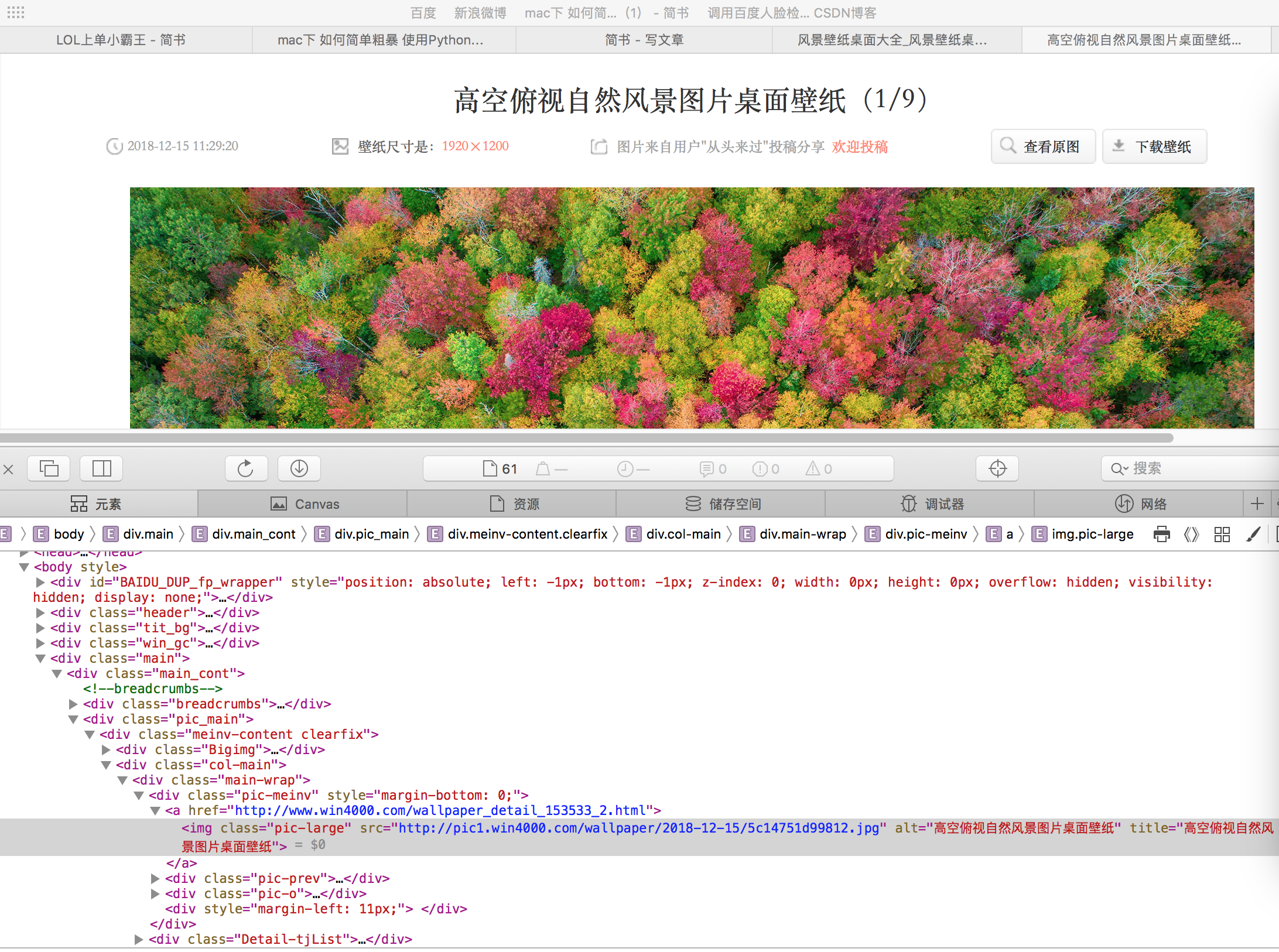
既然每张大图 大概有8-9张不等 那我们就搞一个循环直接便利
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1102
1102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









