








作者:橘子派
声明:版权所有,转载请注明出处,谢谢。
本项目为机器学习的学习笔记 用iris.csv作为数据集 测试了一下功能代码
实验环境:
Windows10
Sublime
Anaconda 1.6.0
Python3.6
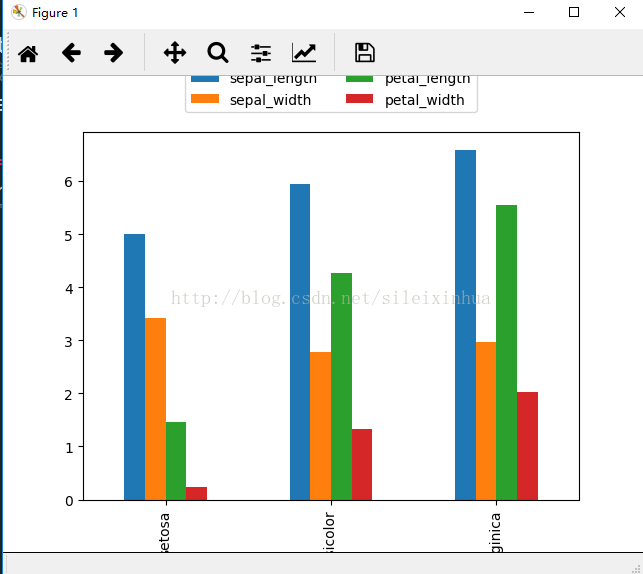
1.条状图显示组平均数,可以从图上看出不同的花种类中,他们的属性特点。
#条状图显示组平均数,可以从图上看出不同的花种类中,他们的属性特点。
import pandas as pd
from matplotlib import pyplot as plt
iris_data=pd.read_csv("iris.csv")
#读取数据
grouped_data=iris_data.groupby("species")
#用不同的花的类别分成不同的组,此数据为三组
group_mean=grouped_data.mean()
#求组平均值
group_mean.plot(kind="bar")
plt.legend(loc="upper center",bbox_to_anchor=(0.5,1.2),ncol=2)
plt.show()
#画图
运行结果
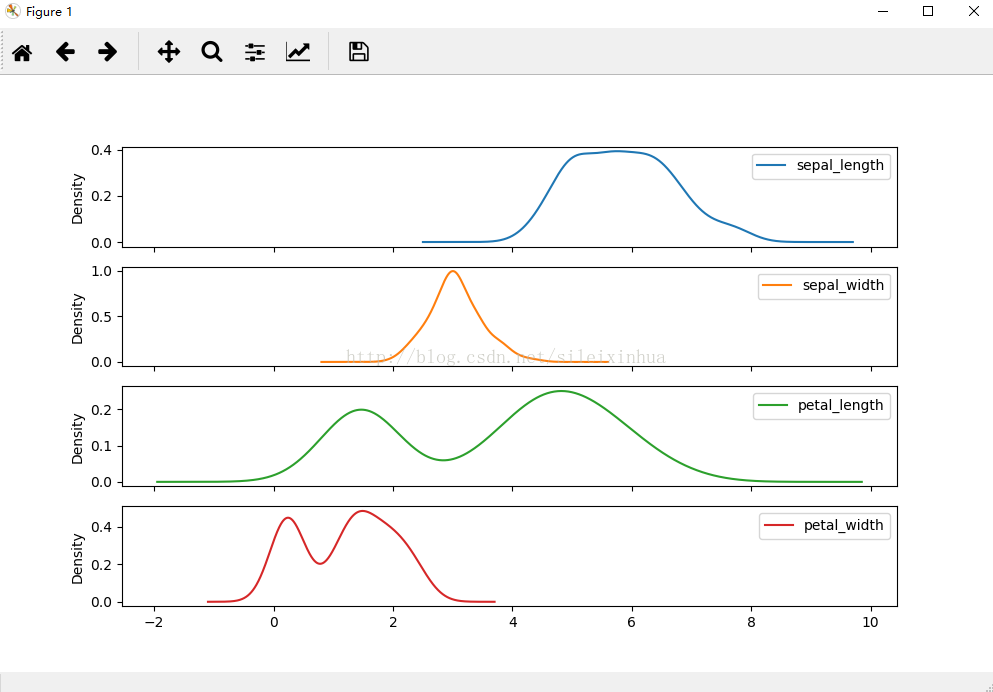
2.画kde图
#画kde图
import pandas as pd
from matplotlib import pyplot as plt
iris_data=pd.read_csv("iris.csv")
iris_data.plot(kind="kde",subplots=True,figsize=(10,6))
plt.show()
运行结果
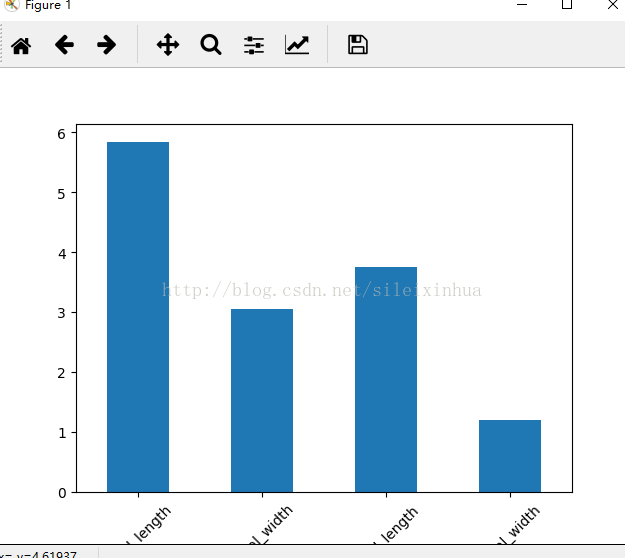
3.四种属性特征的平均值 条状图
#四种属性特征的平均值 条状图
import pandas as pd
from matplotlib import pyplot as plt
iris_data=pd.read_csv("iris.csv")
iris_mean=iris_data.mean()
iris_mean.plot(kind="bar",rot=45)
plt.show()
运行结果
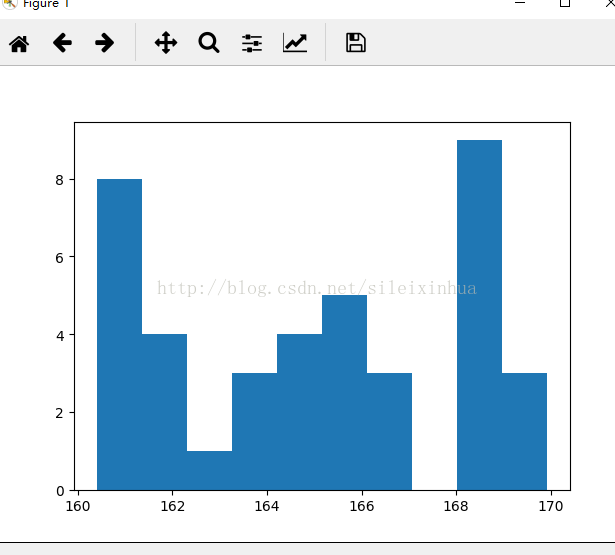
4.用numpy创建随机值,测试,与数据项目无关
#用numpy创建随机值,测试,与数据项目无关
import numpy as np
from matplotlib import pyplot as plt
n,m,s=40,160,10
data=np.random.random(n)*s+m
#print(data)
c,x,_=plt.hist(data,10)
print(c)
print(x)
plt.show()
运行结果
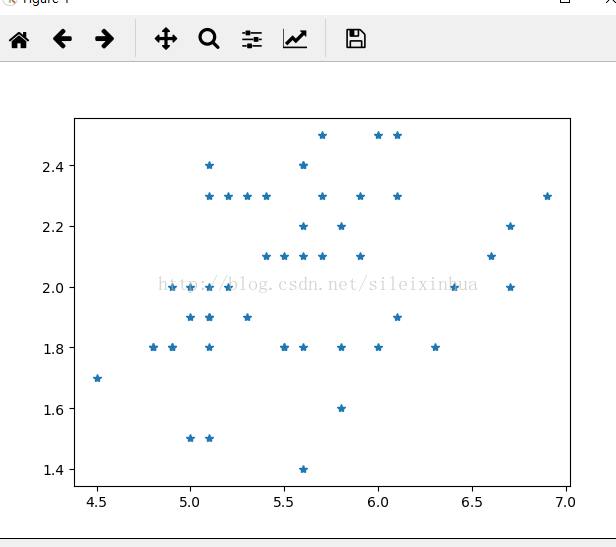
5.绘制样本图
#绘制样本图
import pandas as pd
from matplotlib import pyplot as plt
iris_data=pd.read_csv("iris.csv")
for name,symbol in zip(("setosa","versicolor","virginica"),("o","s","*")):
data=iris_data[iris_data["species"]==name]
plt.plot(data["petal_length"],data["petal_width"],symbol)
plt.show()
运行结果
6.用sqlite3读取数据
#用sqlite3读取数据
import sqlite3
con=sqlite3.connect("iris.db")
cursor=con.execute("SELECT * FROM iris WHERE Species = 'virginica'")
for row in cursor:
print(rwo[0],rwo[1],rwo[2],rwo[3],rwo[4])
7.用pandas读取数据
#用pandas读取数据
import pandas as pd
iris_data=pd.read_csv("iris.csv")
print(iris_data.head(5))
8.用原生Python读取数据
#用原生Python读取数据
fp=open("iris.csv","r")
next(fp)
iris_data=[]
for line in fp:
record = line.strip().split(".")
iris_data.append(record)
print(iris_data[:5])
9.用sqlalchemy 读取数据
#用sqlalchemy 读取数据
import sqlalchemy
engine=sqlalchemy.create_engine("sqlite:///iris.db")
iris_data=pd.read_sql("SELECT * FROM iris",engine)
print(iris_data)
10.用sklearn的交叉验证 训练数据集
#用sklearn的交叉验证 训练数据集
import pandas as pd
from sklearn import cross_validation
from sklearn.neighbors import KNeighborsClassifier
x=pd.read_csv("iris.csv")
y=x.pop("species")
x_train,x_test,y_train,y_test=cross_validation.train_test_split(x.values,y.values,test_size=0.1)
scores=cross_validation.cross_val_score(KNeighborsClassifier(3),x,y,cv=5)
mean_score=scores.mean()
print(mean_score)
运行结果
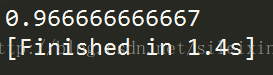
验证精度为0.97
11.用sklearn的KNN 训练数据集
#用sklearn的KNN 训练数据集
import pandas as pd
from sklearn import cross_validation
from sklearn.neighbors import KNeighborsClassifier
x=pd.read_csv("iris.csv")
y=x.pop("species")
x_train,x_test,y_train,y_test=cross_validation.train_test_split(x.values,y.values,test_size=0.1)
knn=KNeighborsClassifier(3).fit(x_train,y_train)
for y_pred,y_true in zip(knn.predict(x_test),y_test):
print(y_pred,y_true)
print(knn.score(x_test,y_test))
运行结果
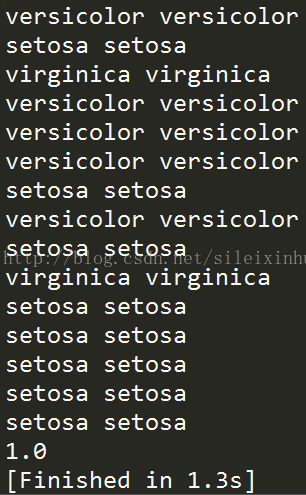
验证精度为1.0
12.用sklearn的逻辑斯蒂回归 训练数据集
#用sklearn的逻辑斯蒂回归 训练数据集
import pandas as pd
from sklearn import cross_validation
from sklearn.linear_model import LogisticRegression
x=pd.read_csv("iris.csv")
y=x.pop("species")
x_train,x_test,y_train,y_test=cross_validation.train_test_split(x.values,y.values,test_size=0.1)
lr=LogisticRegression(multi_class="multinomial",solver="lbfgs").fit(x_train,y_train)
print(lr.predict_proba(x_test))
运行结果
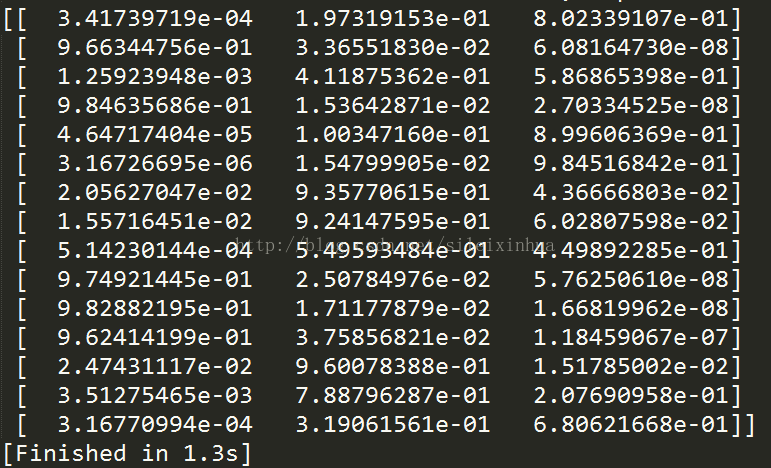
图上为预测的数据
13.用sklearn的朴素贝叶斯 训练数据集
#用sklearn的朴素贝叶斯 训练数据集
import pandas as pd
from sklearn import cross_validation
from sklearn.naive_bayes import GaussianNB
x=pd.read_csv("iris.csv")
y=x.pop("species")
x_train,x_test,y_train,y_test=cross_validation.train_test_split(x.values,y.values,test_size=0.1)
gnb=GaussianNB().fit(x_train,y_train)
print(gnb.predict_proba(x_test))
print(gnb.class_prior_)
运行结果
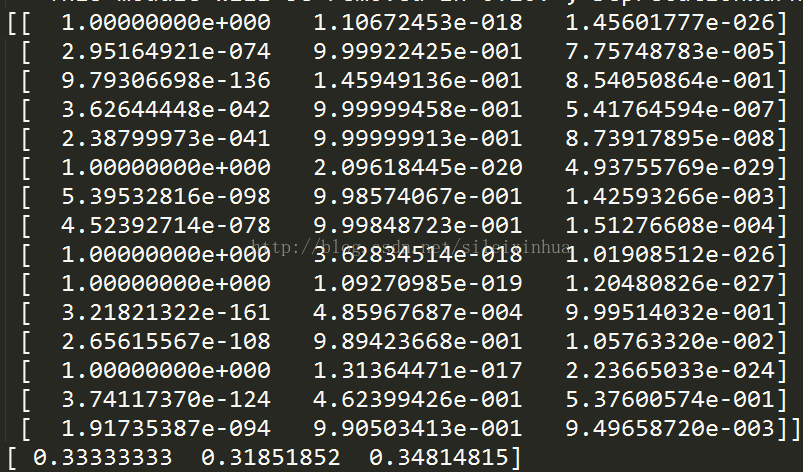
图上为预测的数据和分组的结果
14.用sklearn的交叉验证 KNN 逻辑蒂斯回归 三种方式 训练数据集 并对比
#用sklearn的交叉验证 KNN 逻辑蒂斯回归 三种方式 训练数据集 并对比
import pandas as pd
from sklearn import cross_validation
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
x=pd.read_csv("iris.csv")
y=x.pop("species")
x_train,x_test,y_train,y_test=cross_validation.train_test_split(x.values,y.values,test_size=0.1)
models={
"knn":KNeighborsClassifier(6),
"gnb":GaussianNB(),
"lr":LogisticRegression(multi_class="multinomial",solver="lbfgs")
}
for name,model in models.items():
score=cross_validation.cross_val_score(model,x,y,cv=5).mean()
print(name,score)
运行结果
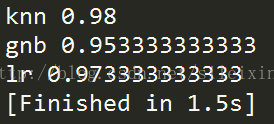
KNN算法的验证精度为0.98
朴素贝叶斯算法的验证精度为0.95
逻辑斯蒂回归算法的验证精度为0.97
15.
用sklearn的SVM 训练数据集
import pandas as pd
from sklearn import svm,metrics,cross_validation
iris_data=pd.read_csv("iris.csv")
x=iris_data[["sepal_length","sepal_width","petal_length","petal_width"]]
y=iris_data["species"]
x_train,x_test,y_train,y_test=cross_validation.train_test_split(x.values,y.values,test_size=0.1)
clf=svm.SVC()
clf.fit(x_train,y_train)
pre=clf.predict(x_test)
score=metrics.accuracy_score(y_test,pre)
print(score)
运行结果
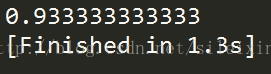
验证精度为0.93
参考文献:
《统计学习方法》
《
Web scraping and machine learning by python》















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









