







一、 问题引入
在当下的开发中,应用的功能做的越来越复杂,工程也越来越大,所以为了尽可能缩短开发周期,不可避免的会用到许多第三方库,随之而来的也会遇到好多问题。比如,程序调用函数funa,funa函数从在于两个库liba.a,libb.a中,并且程序执行需要连接这两个库,那么程序执行时是调用liba.a中funa还是调用的libb.a中的funa呢?
其实这个取决于链接时的顺序,比如先链接的liba.a,这个时候通过liba.a的导出符号表就可以找到funa在liba.a中定义,并加入符号表中;链接libb.a的时候发现符号表已经存在funa,就不会再次更新符号表,所以调用的始终是liba.a中的funa函数。
这里的调用严重的依赖于链接库加载的顺序,很大程度上会导致混论。作为SDK的提供者,我们尤其要避免这点。
正常我们使用的库中包含了好多符号信息,如图1所示:
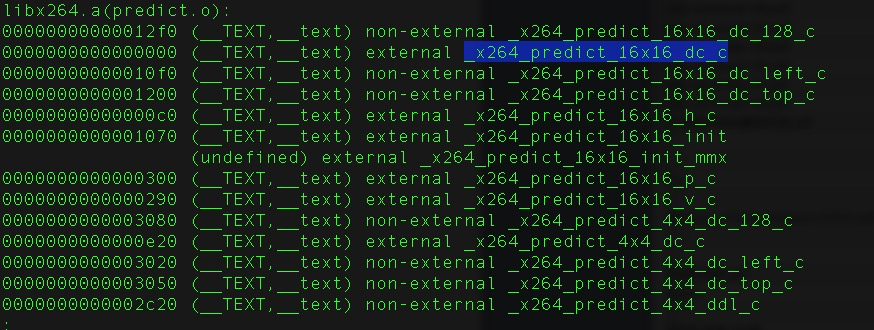
这些符号信息有以下几个弊端:
1、增大了库的体积;
2、隐蔽性较差;
3、容易带来冲突。
在开发过程中第三点带来的问题尤其严重,特别是当我们提供的SDK用到第三方库的时候(因为使用我们SDK的客户也有可能用到跟我们一样
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4437
4437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









