










python爬虫之壁纸的下载
好久没有写博客了,暑假这段时间在学校里面忙着写小论文,没机会写我最喜欢的爬虫了(虽然很简单,但架不住哥喜欢。。。)
好了,废话不多说了,开始把
本次爬虫爬取的是 手机壁纸(爱换壁纸的男人伤不起啊)
目标网址就定在 伟大的贴吧里了(壁纸吧)
这里插一句,以前用的IDE都是pycharm,虽说比较好用,但是最近发现一款IDE,就是anaconda内自带的spyder,感觉比pycharm更适合编程人员,因为它可以实现同步和局部编译,十分方便地查看每一个部分的结果。。各位看官可以试试。。
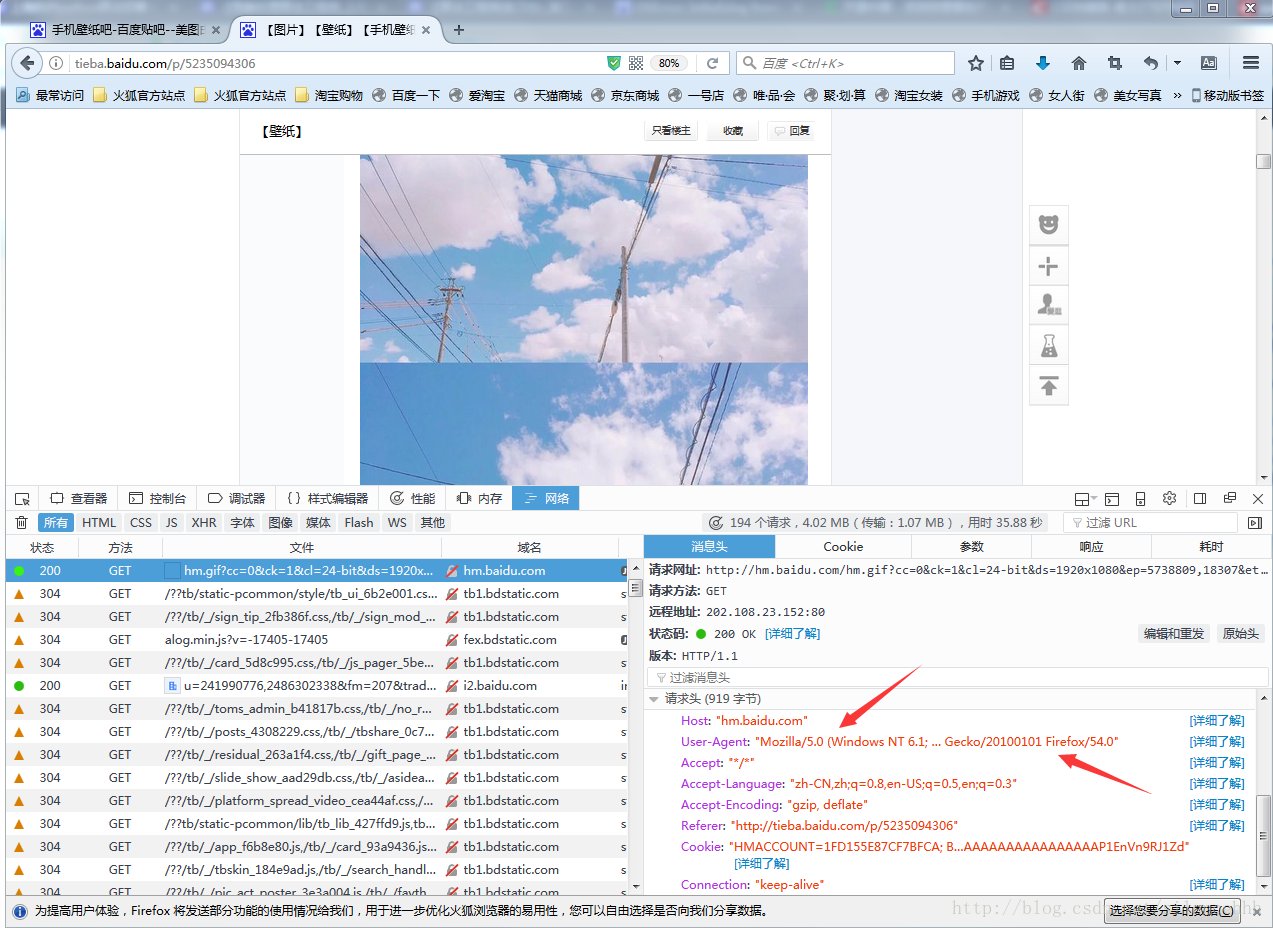
老规矩,先打开目标网页http://tieba.baidu.com/p/5235094306,本次选的是壁纸吧里面的一个精品贴,里面的壁纸还是很吸引人的

不错把,个人还是挺喜欢这种星空风格的。
来吧,让我们端一碗BeautifulSoup鸡汤。。。话说,确实很好用啊
#coding:utf-8
from bs4 import BeautifulSoup
import requests 没有安装这个酷的人,随便pip下就安装好了啊(忘记说了,本代码是基于python3.6)
简单的说,requests是为了获取网页源代码的,然后使用BS来对html格式进行修正,以便后续更方便的使用BeautifulSoup来对其中我们需要的内容进行抓取。编写你就知道了
url = 'http://tieba.baidu.com/p/5235094306'
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0"}#红色箭头的标示出了
html = requests.get(url,headers=headers)
bsObj = BeautifulSoup(html.text,'lxml') BeautifulSoup的基本用法在网上有很多,个人推荐其官方文档,附上链接:[Beautiful Soup 4.2.0 文档](https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html)
代码效果如下:

至此,我们就获得了我们满意的请求页面,接下来需要对其进行分析,找出我们需要下载的图片的位置
贴吧里,我寻找壁纸,一般只看帖子的主人,也就是 只看楼主 这个选项,其实真正我们要爬取得网页是在这个界面上如:http://tieba.baidu.com/p/5235094306?see_lz=1&pn=2
这里插一句,我们爬虫的目的是自己的兴趣,但是死记住 代码这个是不靠谱的,网页千变万化的,难道要一个个记住吗?所以,侧重思路
仔细观察上面这个链接,这是我在选中“只看楼主”选项后,调到第二页的情况下,所显示的网页链接,你不妨多点点其他的页数,会发现出现如下规律:
http://tieba.baidu.com/p/5235094306?see_lz=1&pn=2
http://tieba.baidu.com/p/5235094306?see_lz=1&pn=3
http://tieba.baidu.com/p/5235094306?see_lz=1&pn=4
我们可以将其看成是三部分组成:
1 baseUrl = 'http://tieba.baidu.com/p/5235094306'
2 seeLZ = '?see_lz'
3 PN = '&pn='
利用一个for循环即可实现我们所需要的多页

再说关键点,我们需要将页面中壁纸的链接所找到并下载下来,第一步就得将壁纸链接抓取下来:

观察发现,所有的壁纸的链接都隐藏在 3 号箭头所指的地方,该链接王权可以用BeautifulSoup解析出来,上代码:
bsObj = BeautifulSoup(html.text,'lxml')
imgs = bsObj.find_all('img',class_="BDE_Image")
for i in imgs[0:4]:
print(i)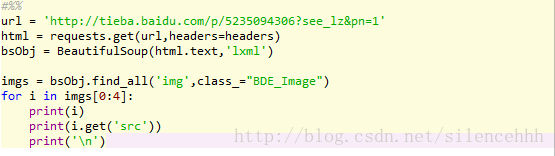
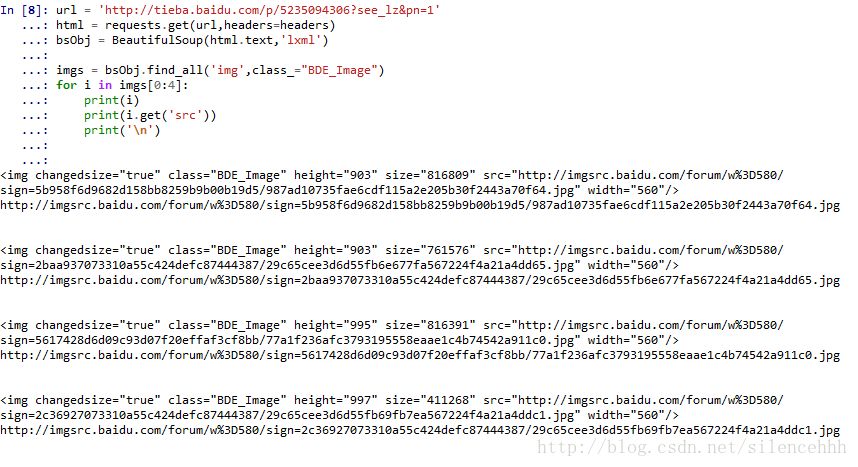
接下来只需进行下载的步骤就好了:
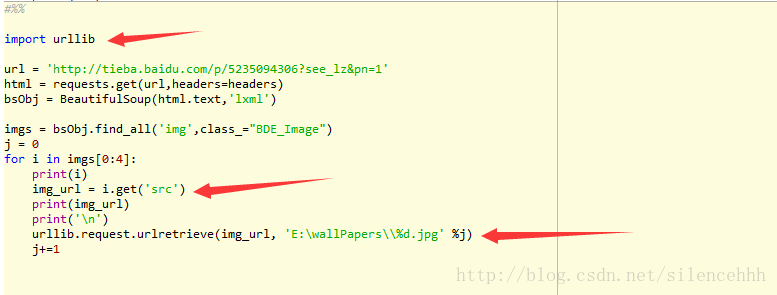
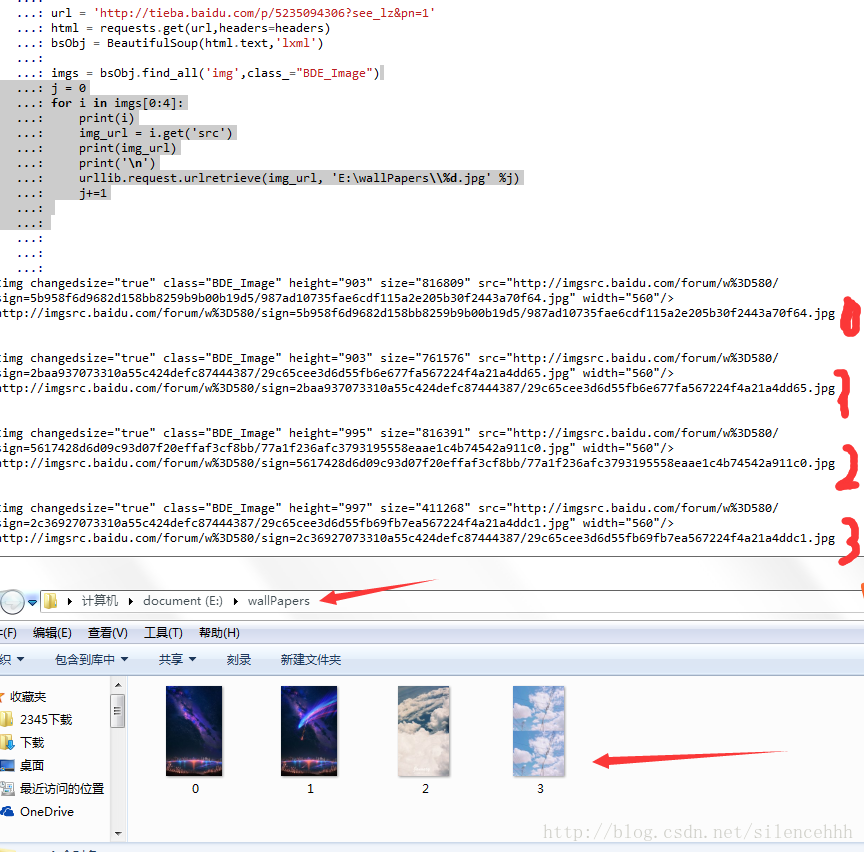
上图只是部分测试代码,以辨明下载效果,文章末尾处会补充完整代码:
# -*- coding: utf-8 -*-
"""
Created on Wed Aug 23 20:20:33 2017
@author: hhh
"""
#%%
import requests
from bs4 import BeautifulSoup
import urllib
import time
base_url = 'https://tieba.baidu.com/p/4645322258?see_lz=1&pn='
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0'}
#%%
def get_text(url,headers):
return requests.get(url,headers)
#%%
def download(img_url,j,k):
urllib.request.urlretrieve(img_url, 'E:\\wallPapers\\%d_%d.jpg' %(j,k))
#%%
for i in range(1,5):
page_url = base_url+str(i)
html = get_text(page_url,headers=headers)
bsObj = BeautifulSoup(html.text,'lxml')
imgs = bsObj.find_all('img',class_="BDE_Image")
k=1
for link in imgs:
download(link.get('src'),i,k)
time.sleep(1.000)
k+=1
print(link.get('src'))
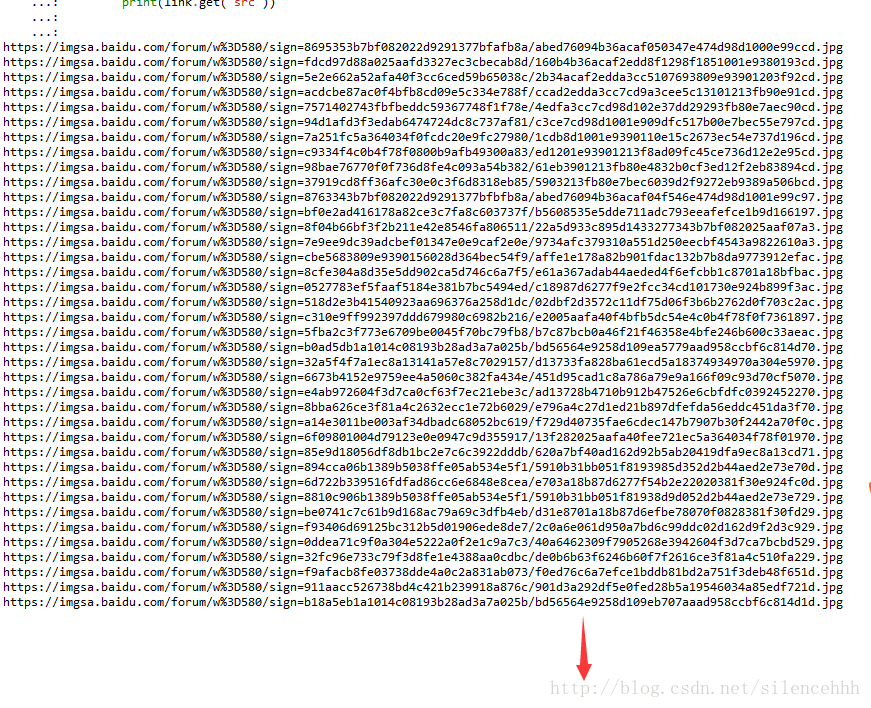
基本完成了,写这样图片多的博客好麻烦啊,爬虫类的以后还是少写点。
PS:在用这个markdown编辑器的时候,get了一个小窍门,更改上传图片的大小
一般我们上传图片后,会得到一个如下图所示的部分:

此时,我们只需要将其改成:
width:宽度百分比
height:高度百分比
就能随心所欲的控制你的图片大小了















 624
624

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









