







最近因项目需要,需要开发Apache druid插件解析kafka推过来的流量,格式为protobuf,字段存储为二进制类型(注意,普通数据类型 druid已支持) ,废话不多说,上思路。
第一步:实现ByteBufferInputRowParser类 XXXParser,业务逻辑的实现在parsePatch()方法
第二步 :创建一个实现DruidModule 类 XXXThriftExtensionsModule, 在getJacksonModules里注册实现的Modle和Parser

第三步(重点):在资源文件下建立个service文件夹,下面建立一个文件,文件名称:org.apache.druid.initialization.DruidModule,否则apache druid加载不了插件,卡了很久蛋疼
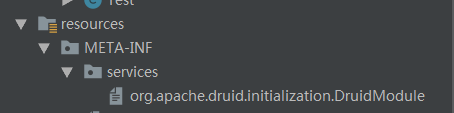
记住路径一定是这样,用来加载插件的初始化,文件名称写上第二步创建的Module类,记住 全路径!!!
第四步:打包上传至安装路径extensions的下,记住名字ABC
第五步:修改配置文件 _common文件夹下的common.runtime.properties 文件,druid.extensions.loadList 加上ABC
第六步:如环境变量没配置,把生产的jar文件也丢一份至lib下即可
第七步:编写json,提交运行
编写json文件,提交supervisors,
给一份json文件,其中type是第二步注册NameType键值对中的值,具体如下图所示:
{
"type": "kafka",
"dataSchema": {
"dataSource": "tabPncIptest",
"parser": {
"type": "pnc_agent",
"parseSpec": {
"format": "json",
"timestampSpec": {
"column": "timestamp",
"format": "auto",
"missingValue": "2020-04-22"
},
"dimensionsSpec": {
"dimensions": [
"agent_id",
"conn_ip",
"create_time",
"proto",
"src_addr",
"src_port",
····
"tid"
]
}
}
},
"granularitySpec": {
"type": "uniform",
"segmentGranularity": "HOUR",
"queryGranularity": "HOUR"
}
},
"ioConfig": {
"topic": "xxxtopic",
"replicas": 1,
"taskCount": 2,
"taskDuration": "PT3600S",
"consumerProperties": {
"bootstrap.servers": "xxx"
}
},
"tuningConfig": {
"type": "kafka",
"maxRowsPerSegment": 8000000,
"resetOffsetAutomatically": true
}
}
提交json文件命令:
curl -XPOST -H'Content-Type: application/json' -d @xxx.json http://xxxIp/druid/indexer/v1/supervisor















 1852
1852











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









