






 文章讲述了在使用AMD处理器运行Abaqus时遇到的兼容性和并行效率问题。首先,通过调整软件依赖库解决了Abaqus与AMD处理器的兼容性问题。接着,通过深入分析并行模式,发现并解决了并行效率低下的问题,提出混合并行模式在AMD平台上能显著提高计算效率。文章强调了正确配置并行计算模式对于优化计算性能的重要性。
文章讲述了在使用AMD处理器运行Abaqus时遇到的兼容性和并行效率问题。首先,通过调整软件依赖库解决了Abaqus与AMD处理器的兼容性问题。接着,通过深入分析并行模式,发现并解决了并行效率低下的问题,提出混合并行模式在AMD平台上能显著提高计算效率。文章强调了正确配置并行计算模式对于优化计算性能的重要性。
最近在某论坛冲浪时,我无意间点开了论坛自动推送的一些用户提问。
不得不承认现在的推送机制很精准,推给我很多跟仿真计算有关的问题。其中一些Abaqus相关的问题吸引了我的注意:
AMD处理器性价比相较Intel更高,我做有限元仿真可以入手吗?但很多人说兼容性不好;
我们今年上了AMD新集群跑Abaqus,很多算例计算速度还不如5年前的Intel集群,甚至核用得越多,计算速度越慢;
……
我又继续检索了一下,发现同类型的问题非常多,看来有很多人深受这些问题困扰。这不巧了,这个问题我们有经验!


记得在2020年,有个用户在我们平台跑Abaqus时也遇到过类似的问题,当时我们花费了不小的功夫才解决。接下来,就让我慢慢道来……
>>Abaqus兼容性问题
其实一开始遇到这个兼容性的问题,我的第一反应是软件装得不对,于是我让助理工程师小张重装一下,“认真仔细”地重装一下。
小张捣鼓了几天,以失败告终。
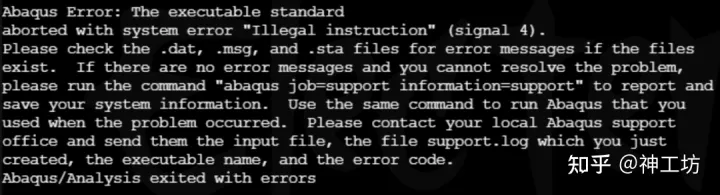
小张报告说,安装界面上也没有几个可供用户配置的选项,纯粹是下一步、下一步式的傻瓜式安装。
他给我提供了一个有效信息:同样的安装方式,老Intel集群完全没问题。想来也对,2014年AMD处理器有市场份额吗?
Abaqus开发者肯定不会考虑去兼容一个都没人用的处理器,里面肯定都是各种仅支持Intel处理器的指令集。但当时已经是2020年了,我认为高版本的软件一定是支持AMD处理器的,从小张的测试反馈来看印证了这一点。
根据我的经验,几年时间Abaqus开发者肯定不会大幅改动软件的架构,顶多是运行的时候依赖库更新了。
众所周知,有限元分析主要就是一系列矩阵运算。我赶紧查看安装目录,发现有一堆Intel MKL矩阵运算的动态链接库,而Abaqus计算过程中,容易出现兼容性问题的很可能就是这些动态链接库不支持AMD处理器。
究竟是哪些库不对呢?又要祭出程序员大招——逐行逐个比对找Bug,找出新旧版本依赖库的区别(熟练地令人心疼)。
终于,在公司和用户的双重压力下,在不占用工作时间的情况下,我完成了这一壮举!

“小张,你再去测试一下吧,我只能做那么多了!”
我看似弃疗,实则信心爆棚。在短暂而又漫长的等待后,捷报频频,之前中途报错(Illegal instruction)的几个算例都能在AMD上正常运行了。
>>Abaqus并行效率问题
祸兮福之所倚,福兮祸之所伏。用户刚夸奖了我们效率高、专业性强,新的问题又接踵而至。这次不是能不能跑的问题,是跑得慢。
有多慢呢?比4年前的Intel慢,慢很多。
我总不能跟用户讲,您回去用4年前的Intel吧?但现实情况是,我们前期投入已经巨大,无论是硬件还是软件适配,几乎已经All IN超威半导体了。
没办法,自己选择的路,跪着也要走完。

于是故事进入新篇章——提高Abaqus在AMD平台的并行效率。
并行目前主流的无非是共享内存并行和分布式并行或者是二者混合。差别是前者只有一个进程共享内存数据,无需通信;后者有多个进程,进程之间需要通信。
拿到小张给我的测试数据,我傻眼了……
一个100万个自由度的算例,采用Abaqus/Standard求解,使用直接求解器,并行规模分别选取8核、16核、32核、64核,8核增加到16核还有点提速,16核增加到32/64核不仅没有提速,速度反而越来越慢。
我赶紧让小张切换Abaqus的并行模式(其默认是MPI模式,THREADS为可选),结果居然是没有区别。
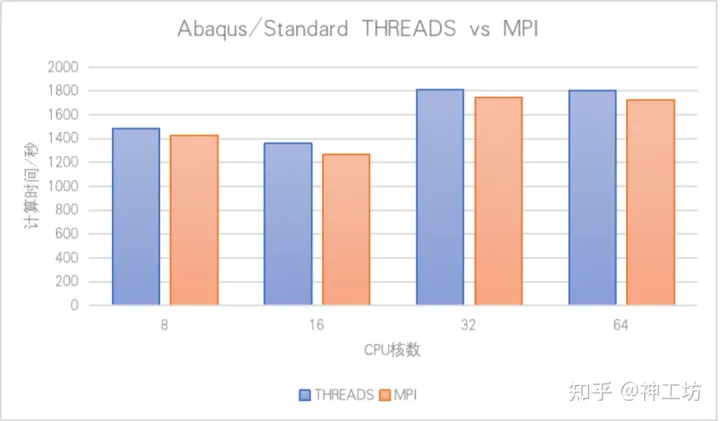
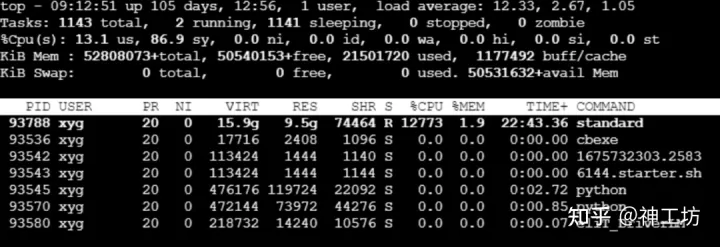
我急忙让小张多测几次,同时我登录后台查看进程情况。
果不其然,无论啥并行模式,后台只显示一个进程,也就是说MPI并行根本没有起来,都是共享内存并行。
根据我的经验,这个直接求解器很可能是混合并行模式,也就是在单个节点内部的时候,强制采用共享内存并行,节点之间是MPI通信。
很快,小张的测试验证了这一点,同时带来了一个非常Amazing的结果——16核之后的并行效率为负的情况得到了扭转。
下面是计算时间结果对比,采用相同的核数,一面是单个节点运行,一面是将作业平均分配到4个节点上。在核数相同的情况下,采用混合并行模式将大大降低计算时间。
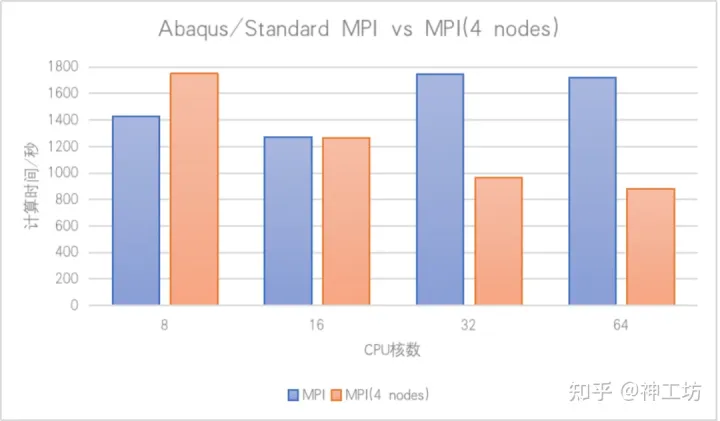
总结一下,我认为本次效率提升有以下几点原因:
1、模型被分解为多个Part,可以使得单元操作并行化;
2、全局矩阵求解分解为多个Part,充分发挥了单个节点的共享内存并行效率,规避了单节点大于16核之后共享内存并行效率低的问题;
3、神工坊集群具有现代化的HPC系统,集群计算机之间配备有Infiniband,提供了高带宽、低延迟和可靠的数据交换,这将使得MPI通信损耗降得很低。
终于破案了!

由于AMD平台的核数一般较多,像我们使用的服务器采用AMD EPYC™ 7002 Series双路、128核。调度器默认肯定是用完一个节点,再用另一个节点。这将导致灾难式的结果——核越多越慢。这就好比花了更多的钱,得到了更差的服务。
就看这个算例,用户在单节点上使用64核相对8核多花将近10倍的钱。而采用我刚才讲的跨节点并行模式,64核花一半的钱得到翻倍的计算效率。
这也反映了一些现象,比如:某仿真平台主打单位核时低廉,但是用户租用他们的平台跑仿真软件,实际上付出了将近10倍的钱,工作效率却没有提升。平台反而成为“自来水”推荐给其他同事使用,仅仅是因为表面上的价格便宜。
而神工坊平台不一样,我们对平台上的多数仿真软件进行了高性能适配,同时根据用户需求进行兼容性适配。你用更多的核,就能获得更高的并行效率,绝不花冤枉钱。
具体结论在前几期的文章里有过细致的对比,欢迎回顾:
“神工坊”性能测试系列之二:Abaqus隐式静力学分析 https://mp.weixin.qq.com/s/tIwiwEnif78QgSxrbhKH7g
https://mp.weixin.qq.com/s/tIwiwEnif78QgSxrbhKH7g
“神工坊”性能测试系列之四:Abaqus显式求解分析https://mp.weixin.qq.com/s/-4y35v-Pm0NJ8s6Kp3WZiA
本文介绍的Abaqus兼容性适配以及Abaqus并行效率优化方式只是其中的一些小技巧,更多的高性能适配方式需要很高的HPC并行计算基础,目前就不再展开,欢迎持续关注我们后续的分享。
综上所述,使用Abaqus进行有限元分析大有门道,特别是并行计算方面,即使是相同的硬件资源,不同的并行模式和任务提交方式,所能发挥出的计算效率和并行效率也是有很大差别。
“神工坊”高性能仿真平台基于超算HPC集群的硬件支撑,对仿真软件进行了CPU平台的高性能适配与优化,相较其他仿真云平台在计算效率和软件适配度方面有较大的优势,欢迎广大仿真从业者注册了解!


















 1119
1119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









