






一.字典树定义
概念:字典树(TrieTree),是一种树形结构,典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串,如01字典树)。主要思想是利用字符串的公共前缀来节约存储空间。很好地利用了串的公共前缀,节约了存储空间。字典树主要包含两种操作,插入和查找。
字典树,是一种哈希树的变种。是一种用于快速查询某个字符串/字符前缀是否存在的数据结构。它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。核心思想是空间换时间。利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
二. 字典树的实现
在用代码实现字典树时,我们主要需要实现两种操作:即插入单词和查找单词,这里我们用两个函数来实现,然后我们用一个二维数组来实现字典树的建树。
在讲解两个函数之前,我们先来了解一下其中需要用到的工具
1.变量id: id代表字典树中每一个节点的编号,id的大小只与插入字典树的先后顺序有关,它的作用在下面会讲到。
2.trie[N][26]: 每个trie代表一条边,字典树其中1~N为边上方节点的编号,0代表root节点,1~26为连在i节点下方的26个字母。如果trie[i][x]=0,则代表字典树中目前没有这个点,而trie[i][x]的值代表这个点下方连有的点的编号,例如:trie[i][2]=9代表第i号点和的下方连有一个点‘c’,并且那个点的编号是9,为什么是c呢?因为 ‘c’-‘a’=2
3.cnt[N]: cnt[i]==0代表编号为i的点不是一个单词的结束点,在上面的图中代表这个点不是空点,但是没有标红,cnt[i]!=0代表编号为i的点是一个单词的结束点,即红点。cnt[i]不一定只为0或1,因为有可能多次输入了同一个单词。
4.(难点)两个函数中的变量p:
p代表查询与插入时的不断变化的当前节点编号,初始化为0,代表初始节点,在函数的循环中,我们首先用x确定接下来要找的字母,再通过变量x确定了接下来我们需要查找当前节点下是否有连接着目标字母的节点。通过每次确定的x,我们通过trie[p][x] 查找连着目标字母的节点的编号,如果目标节点存在,就把p更新成目标节点的编号(p = trie[p][x])。而如果trie[p][x] == 0,代表字典树中没有这个点,如果是查找就代表没有这个单词,查找失败。而如果是插入函数,我们就用 ++id 来把这个点存进字典树。我们在两个函数的最后用cnt[p]来涂红节点或返回节点值。原文出处:https://blog.csdn.net/qq_49688477/article/details/118879270
一.插入函数的实现
插入函数其实就是一个建树的过程,我们通过不断的插入字符串,不断的建成一颗字典树,那我们该如何建树呢?
void insert(char s[])
{
int p = 0; //p指针一开始为0,即在根节点位置
for (int i = 0; s[i]; i++) {
int q = s[i] - 'a' + 1; //将字符转换成整型数值,方便存储
if (!f[p][q]) f[p][q] = ++id; //如果没有该节点,就新建一个
p = f[p][q]; //进行往下建树
}
cnt[p]++; //插入次数
}
如果我们依依次插入“cat" “car" “busy" “cate" “bus" “car'’ 这几个字符串,我们可以得到这样一颗字典树。
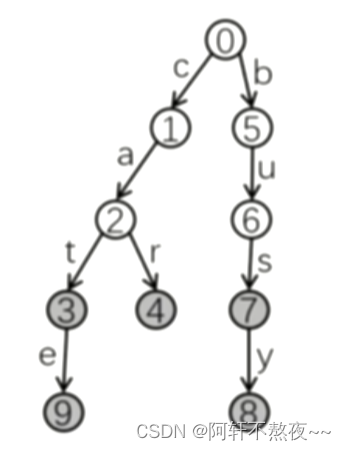
二.查找函数的实现
既然我们知道如何插入,建成一颗字典树了,那么我们查找只要在插入的基础上进行就可以,我们从根节点开始进行查询,类似于前序遍历一样,进行查找。
int find(char s[])
{
int p = 0; //p指针指向根节点
for (int i = 0; s[i]; i++) {
int q = s[i] - 'a' + 1;
if (!f[p][q]) return 0; //如果没有找到对应的字符,退出
p = f[p][q];
} //如果循环正常结束,说明已经找到
return cnt[p]; //返回插入的次数
}
三.相关例题分析
一.P8306 【模板】字典树
题目描述
给定 n 个模式串 s1,s2,…,sn 和 q 次询问,每次询问给定一个文本串 ti,请回答 1∼sn 中有多少个字符串 sj 满足 ti 是 sj 的前缀。
一个字符串 t 是 s 的前缀当且仅当从 s 的末尾删去若干个(可以为 0 个)连续的字符后与 t 相同。
输入的字符串大小敏感。例如,字符串 Fusu 和字符串 fusu 不同。
输入格式
本题单测试点内有多组测试数据。
输入的第一行是一个整数,表示数据组数 T。
对于每组数据,格式如下:
第一行是两个整数,分别表示模式串的个数 n 和询问的个数 q。
接下来 n 行,每行一个字符串,表示一个模式串。
接下来 q 行,每行一个字符串,表示一次询问。
输出格式
按照输入的顺序依次输出各测试数据的答案。
对于每次询问,输出一行一个整数表示答案。
输入输出样例
输入 #1复制
3 3 3 fusufusu fusu anguei fusu anguei kkksc 5 2 fusu Fusu AFakeFusu afakefusu fusuisnotfake Fusu fusu 1 1 998244353 9
输出 #1复制
2 1 0 1 2 1
说明/提示
数据规模与约定
对于全部的测试点,保证1≤T,n,q≤105,且输入字符串的总长度不超过3×106。输入的字符串只含大小写字母和数字,且不含空串。
说明
std 的 IO 使用的是关闭同步后的 cin/cout,本题不卡常。
这是一道字典树模版题,只要把我们刚刚介绍的东西弄懂了,就OK了,我们就通过这道题来理解一下字典树例题的解题思路(注意这道题,这里有多组数据,要清空数组)
#include<bits/stdc++.h>
using namespace std;
#define N 3000005
int s[N][126], cnt[N]; //s数组用来建数
int t, q, n, p, sum, id;
char str[N];
void clear() //清空操作,因为有多组数据
{
for (int i = 0; i <= id; i++) {
cnt[i] = 0;
for (int j = 0; j <=126; j++) {
s[i][j] = 0;
}
}
id = 0;
}
void insert(char str[]) //插入函数
{
int len = strlen(str);
p = 0;
for (int i = 0; i < len; i++) {
int j = (int)str[i]; //转换为整型
if (!s[p][j]) //如果没有该节点,新建一个
s[p][j] = ++id;
p = s[p][j]; //继续进行往下插入
cnt[p]++; //记录插入次数
}
}
int find(char str[]) //查找操作
{
int len = strlen(str);
p = 0;
for (int i = 0; i < len; i++) {
int j = (int)str[i];
if (!s[p][j]) //如果没有找到对应字符,退出
return 0;
p = s[p][j];
}
return cnt[p]; //返回插入次数
}
int main()
{
cin >> t;
while (t--) {
clear(); //一定要清空数组
cin >> n >> q;
for (int i = 1; i <= n; i++) {
cin >> str;
insert(str);
}
for (int i = 1; i <= q; i++) {
cin >> str;
cout << find(str) << endl;
}
}
return 0;
}二.P2580 于是他错误的点名开始了
题目背景
XS中学化学竞赛组教练是一个酷爱炉石的人。
他会一边搓炉石一边点名以至于有一天他连续点到了某个同学两次,然后正好被路过的校长发现了然后就是一顿欧拉欧拉欧拉(详情请见已结束比赛 CON900)。
题目描述
这之后校长任命你为特派探员,每天记录他的点名。校长会提供化学竞赛学生的人数和名单,而你需要告诉校长他有没有点错名。(为什么不直接不让他玩炉石。)
输入格式
第一行一个整数 n,表示班上人数。
接下来 n 行,每行一个字符串表示其名字(互不相同,且只含小写字母,长度不超过 5050)。
第 n+2 行一个整数 m,表示教练报的名字个数。
接下来 m 行,每行一个字符串表示教练报的名字(只含小写字母,且长度不超过 5050)。
输出格式
对于每个教练报的名字,输出一行。
如果该名字正确且是第一次出现,输出 OK,如果该名字错误,输出 WRONG,如果该名字正确但不是第一次出现,输出 REPEAT。
输入输出样例
输入 #1复制
5 a b c ad acd 3 a a e
输出 #1复制
OK REPEAT WRONG
说明/提示
- 对于 40% 的数据,n≤1000,m≤2000。
- 对于 70% 的数据,n≤104,m≤2×104。
- 对于 100% 的数据,n≤104,m≤105。
这道题也类似于模版题,只要我们熟悉插入和查找的过程,一样可以解决,这里只要注意一下第一次出现和其它次出现所输出是不一样的,这里我们只要在查找函数中返回不同的值,这样就可以解决了。
#include<bits/stdc++.h>
using namespace std;
#define N 1000005
int n, m, id, ans, num;
int f[N][27], cnt[N]; //f数组为建树用,cnt数组记录插入次数
bool vis[N]; //标记数组
char s[N];
void insert(char s[]) //插入函数
{
int p = 0; //p指针指向根节点
for (int i = 0; s[i]; i++) {
int q = s[i] - 'a' + 1;
if (!f[p][q]) f[p][q] = ++id; //如果没有该节点,就新建一个
p = f[p][q]; //继续往下插入
}
vis[p] = true; //插入完成,为下面查询时做铺垫
}
int find(char s[]) //查找函数,注意这里要返回0,1,2三个值代表不同状态
{
int p = 0;
for (int i = 0; s[i]; i++) {
int q = s[i] - 'a' + 1;
if (!f[p][q]) return 0; //如果没有查找到该字符,退出
p = f[p][q];
}
if (!vis[p]) return 0; //没有查找到该字符串
if (cnt[p]==0) { //找到该字符串,但要讨论是第几次查到
++cnt[p];
return 1;
}
return 2;
}
int main()
{
memset(vis, false, sizeof(vis));
memset(cnt, 0, sizeof(cnt));
cin >> n;
for (int i = 1; i <= n; i++) {
cin >> s;
insert(s);
}
cin >> m;
for (int i = 1; i <= m; i++) {
cin >> s;
int k = find(s);
if (k == 0) //如果没有找到
cout << "WRONG" << endl;
if (k == 1) //如果第一次找到
cout << "OK" << endl;
if (k == 2) //如果不是第一次找到
cout << "REPEAT" << endl;
}
return 0;
}OK,本次关于字典树的总结就结束了,如果对于本篇总结有疑问的欢迎讨论,同时如果有错误或者待修改完善的地方,也希望能够指出,我一定会及时改正,~QVQ~















 500
500











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









