







背景
我有两份数据, 一份是服务器功率(采集周期为15s采集一次) , 一份是服务器的cpu利用率(采集周期为1分钟); 现需要把两份数据按照服务器的sn拼接在同一个 df中。 过程中遇到的难点主要是时间戳转换, 时间对齐;
具体方法如下:Pandas resample把时间戳变为相同的采集间隔,然后根据时间戳进行merge拼接
数据格式
cpu数据如下(cpu_utils.csv):
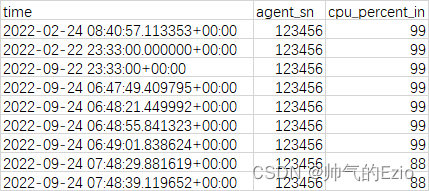
power数据格式如下:
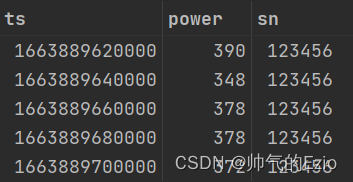
数据拼接
resample+merge代码
if __name__ == "__main__":
dict_power = {"1663889620000": "390", "1663889640000": "348", "1663889660000": "378",
"1663889680000": "378", "1663889700000": "372", "1663889740000": "372",
"1663889760000": "366", "1663889810000": "384", "1663889840000": "378",
"1663889860000": "390", "1663889870000": "384", "1663889880000": "378",
"1663889900000": "384", "1663889940000": "360", "1663889970000": "360",
"1663889980000": "402", "1663890020000": "384", "1663890030000": "372",
"1663890050000": "384", "1663890070000": "378", "1663890080000": "360",
"1663890120000": "360", "1663890140000": "360", "1663890160000": "366",
"1663890180000": "372", "1663890210000": "378", "1663890220000": "426",
"1663890260000": "354", "1663890280000": "372", "1663890290000": "360",
"1663890300000": "378", "1663890310000": "444", "1663890320000": "384",
"1663890330000": "366", "1663890360000": "360", "1663890380000": "378",
"1663890390000": "384", "1663890400000": "378", "1663890420000": "354",
"1663890430000": "378", "1663890450000": "372", "1663890490000": "384",
"1663890530000": "378", "1663890550000": "390", "1663890600000": "390",
"1663890610000": "366", "1663890630000": "348", "1663890640000": "360",
"1663890660000": "384", "1663890670000": "348", "1663890690000": "360",
"1663890740000": "384", "1663890760000": "0", "1663890800000": "378"}
sn = "123456"
result = pd.DataFrame()
new_df = pd.DataFrame()
# dict_power = value
tss = [int(x) for x in list(dict_power.keys())]
powers = [int(x) for x in list(dict_power.values())]
test_df = pd.DataFrame(data={"ts": tss, "power": powers, "sn": [sn] * len(dict_power)})
merge_data = test_df
df_temp = pd.DataFrame()
df_temp["power"] = pd.Series(dtype="object")
df_temp.at[0, "power"] = merge_data["power"].values
df_temp["sn"] = merge_data["sn"].iloc[0]
# print("df_temp", df_temp)
test_df['ts'] = pd.to_datetime(test_df['ts'], unit='ms')
test_df = test_df.set_index("ts")
new_df["power"] = test_df.power.resample(rule='1T').mean()
new_df["sn"] = sn
result = pd.concat([result, new_df.reset_index()])
print("result", result)
cpu_utils = pd.read_csv("../cpu_utils.csv")
cpu_utils["time"] = pd.to_datetime(cpu_utils["time"])
# print("cpu_utils", pd.to_datetime(cpu_utils["time"], format="%Y-%m-%d",exact="strict"))
print("cpu_utils", cpu_utils)
merge_data = pd.merge(cpu_utils, result, how='inner', left_on="time", right_on="ts")
print("merge_data", merge_data)















 1882
1882











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









