










学习文法的好处
学习文法的一个好处是,它提供了一个概念性的框架和词汇拼写这些直觉。
成分结构基于对词与其他词结合在一起形成单元的观察。一个词序列形成这样一个单元被证明是可替代的——也就是说,在一个符合语法规则的句子中的词序列可以被一个更小的序列替代而不会导致句子不符合语法规则。例如下面这个句子:
eg:The little bear saw the fine fat trout in the brook.
在下图中,我们系统地用较短的序列替代较长的序列,并使其依然符合语法规则。事实上,形成一个单元的每个序列可以被一个单独的词替换,我们最终只有两个元素。

下图中,我们为我们在前面的图上看到的词增加了文法类别标签。标签 NP,VP 和PP 分别表示 名词短语, 动词短语和介词短语。

如果我们现在从最上面的行剥离出词汇,增加一个 S 节点,翻转图,最终我们得到一个标准的短语结构树。如下图所示:

上下文无关文法
一种简单的文法
按照惯例 ,第一条生产式的左端是文法的 开始符号,通常是 S,所有符合语法规则的树都必须有这个符
号作为它们的根标签。下面给出一个例子:
grammar1 = nltk.CFG.fromstring("""
S -> NP VP
VP -> V NP | V NP PP
PP -> P NP
V -> "saw" | "ate" | "walked"
NP -> "John" | "Mary" | "Bob" | Det N | Det N PP
Det -> "a" | "an" | "the" | "my"
N -> "man" | "dog" | "cat" | "telescope" | "park"
P -> "in" | "on" | "by" | "with"
""")
>>> sent = "Mary saw Bob".split()
>>> rd_parser = nltk.RecursiveDescentParser(grammar1)
>>> for tree in rd_parser.parse(sent):
... print(tree)
(S (NP Mary) (VP (V saw) (NP Bob)))句法类型:
| Symbol | Meaning | Example |
|---|---|---|
| S | sentence | the man walked |
| NP | noun phrase | a dog |
| VP | verb phrase | saw a park |
| PP | prepositional phrase(介词短语) | with a telescope |
| Det | determiner(限定词) | the |
| N | noun | dog |
| V | verb | walked |
| P | preposition | in |
VP -> V NP | V NP PP 代表这是VP -> V NP 和 VP -> V NP PP 的缩写。
上下文无关文法分析
递归下降分析
S→NP VP 生产式允许分析器替换这个目标为两个子目标:找到一个 NP,然后找到一个 VP。每个这些子目标都可以再次被子目标的子目标替代,使用左侧有 NP 和 VP 的产生式。
递归下降分析器在上述过程中建立分析树。带着最初的目标(找到一个 S),创建 S 根节点。随着上述过程使用文法的产生式递归扩展,分析树不断向下延伸(故名为递归下降)。我们可以在图形化示范 nltk.app.rdparser()中看到这个过程。

分析器以一颗包含节点 S 的树开始;每个阶段它会查询文法来找到一个可以用于扩大树的产生式;当遇到一个词汇产生式时,将它的词与输入比较;发现一个完整的分析树后,分析器会回溯寻找更多的分析树。
递归下降分析是一种 自上而下分析。自上而下分析器在检查输入之前先使用文法预测输入将是什么。
注意:RecursiveDescentParser 是无法处理形如 X -> X Y 的 左递归产生式。
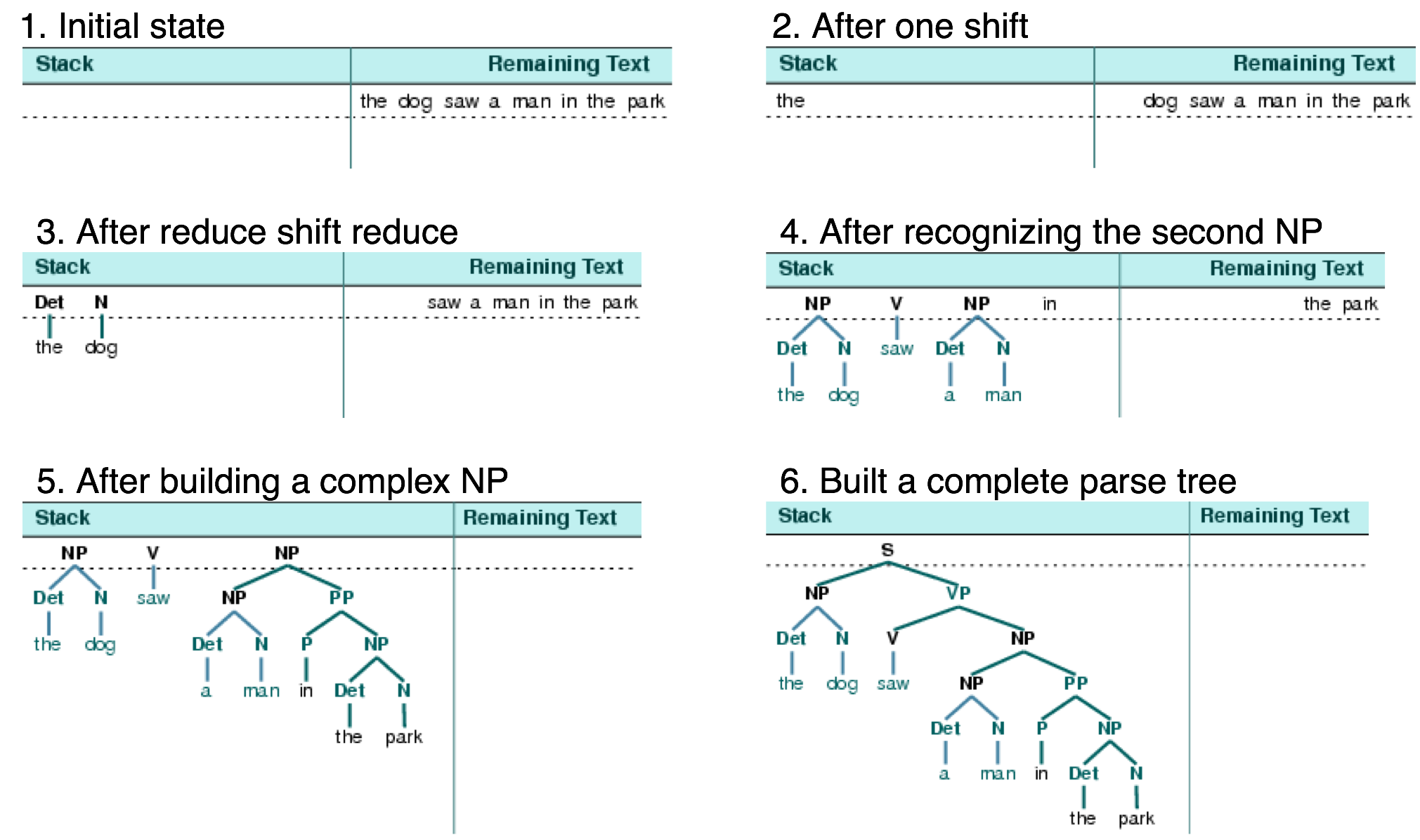
移进-规约分析
一种简单的自下而上分析器是 移进-归约分析器。与所有自下而上的分析器一样,移进-归约分析器尝试找到对应文法生产式右侧的词和短语的序列,用左侧的替换它们,直到整个句子归约为一个 S。
移位-规约分析器反复将下一个输入词推到堆栈,这是 移位(shift)操作。如果堆栈上的前 n 项,匹配一些产生式的右侧的 n 个项目,那么就把它们弹出栈,并把产生式左边的项目压入栈。这种替换前 n 项为一项的操作就是 规约(reduce)操作。
当所有的输入都使用过,堆栈中只剩余一个项目,也就是一颗分析树作为它的根的 S 节点时,分器完成。
我们可以使用图形化示范 nltk.app.srparser()看到移位-规约分析算法步骤 。
左角落分析器(The Left-Corner Parser)
递归下降分析器的问题之一是当它遇到一个左递归产生式时,会进入无限循环。这是因为它盲目应用文法产生式而不考虑实际输入的句子。左角落分析器是我们已经看到的自下而上与自上而下方法的混合体。
例如:A->B C ,则我们说B是A的左角落。

左角落分析器是一个带自下而上过滤的自上而下的分析器。不像普通的递归下降分析器,它不会陷入左递归产生式的陷阱。在开始工作之前,左角落分析器预处理上下文无关文法建立一个表,其中每行包含两个单元,第一个存放非终结符,第二个存放那个非终结符可能的左角落的集合。例如:
| Category | Left-Corners (非终结符) |
|---|---|
| S | NP |
| NP | Det, PropN |
| VP | V |
| PP | P |
分析器每次考虑产生式时,它会检查下一个输入词是否与左角落表格中至少一种非终结符的类别相容。















 4504
4504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









