







系列文章目录
第一章 Linux内存池基础储备
前言
提示:这里可以添加本文要记录的大概内容:
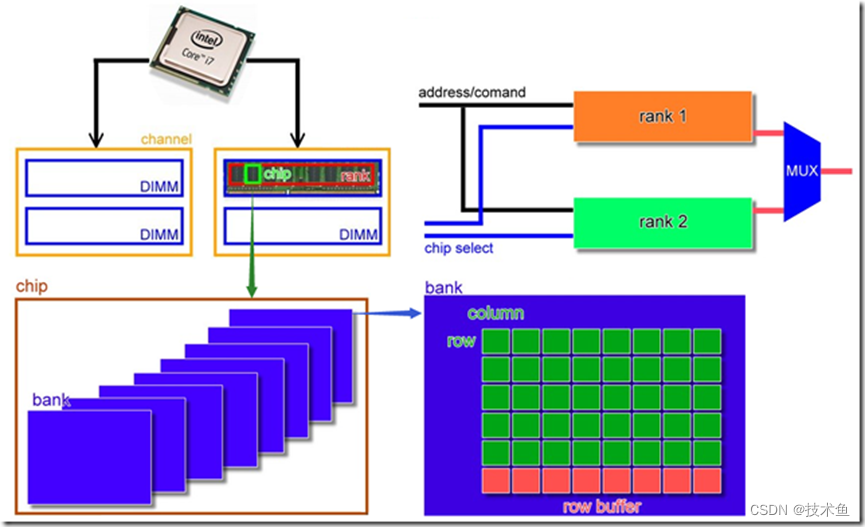
对于内存池的了解,首先要知道CPU是如何使用内存的。从CPU到实际的存储节点,依据层级划分:·Channel > DIMM > Rank > Chip > Bank > Row /Column。
提示:以下是本篇文章正文内容,下面案例可供参考
一、基本概念是什么?
channel
CPU到内存的通路是channel,每个channel对应一个CPU的内存控制器,每个channel可以配有多个DIMM。双通道:CPU外核或北桥有两个内存控制器,每个控制器控制一个内存通道。理论上内存带宽增加一倍。
四通道同理。
DIMM
全称Dual-Inline-Memory-Modules(双列直插式存储模块),是目前最常见的内存模块( 可以理解为内存条)。以前的主机是直接将存储芯片(chip)插在主板上的,然后发展出SIMM(Single In-line Memory Module),将多个chip焊在一片电路板上,成为内存模块,再将它插到主板上。
Rank
DIMM上一部分或所有chip组成一个rank(64bit),因此内存至少需要有16片4bit的chip或者8bit的chip(不存在4bit和8bit芯片混搭的情况)。
内存控制器只允许CPU每次与内存进行一组64bits的数据交换,对应的就是一个rank。rank也可以理解为连接到同一个CS(chip select)的一组chip。
rank分类:
- Single-Rank(1R),要动用到DIMM上所有的chip,这些chip由同一个片选信号控制。
- Double-Rank(2R),产生2个64位rank,由2个片选信号控制,这2个片选信号是交错的,不争抢内存总线。
- Quad-Rank(4R),产生4个64位rank,由4个片选信号控制,这4个片选信号是交错的,不争抢内存总线。
在地址选择时,只有当片选信号有效时,此片所连的地址线才有效。
chip
内存条上的黑色芯片就是chip,提供4bit/8bit/16bit/32bit的数据,提供4bit的芯片记作x4,提供8bit的芯片记作x8。
二、CPU 相关
现代CPU的基本架构
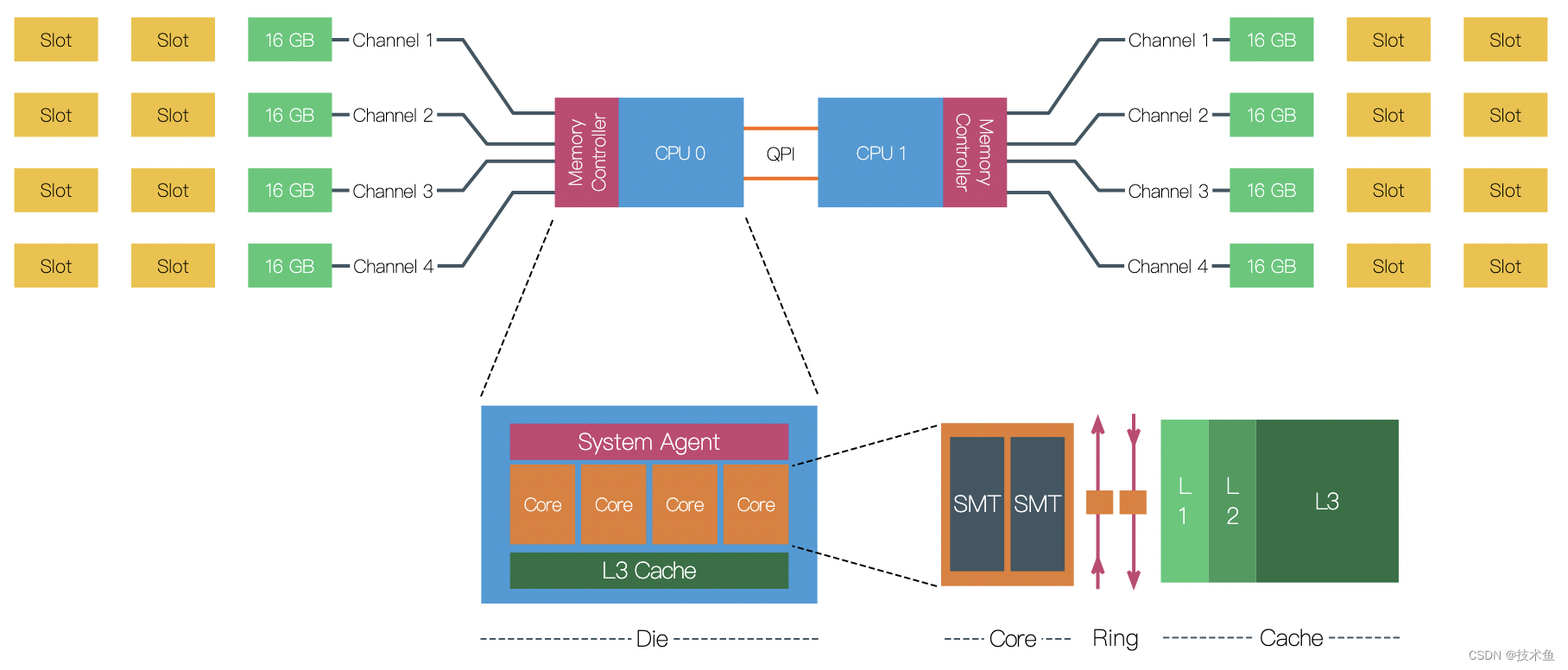
iTLB:instruct TLB
dTLB:data TLB
多个core加上L3等组成一个Die:
DIe
Die:从晶圆上切割下来的CPU(通常一个Die中包含多个core、L3cache、内存接口、GPU等,core里面又包含了L1、L2cache),Die的大小可以自由决定,得考虑成本和性能, Die做成方形便于切割和测试,服务器所用的Intel CPU的Die大小一般是大拇指指甲大小。
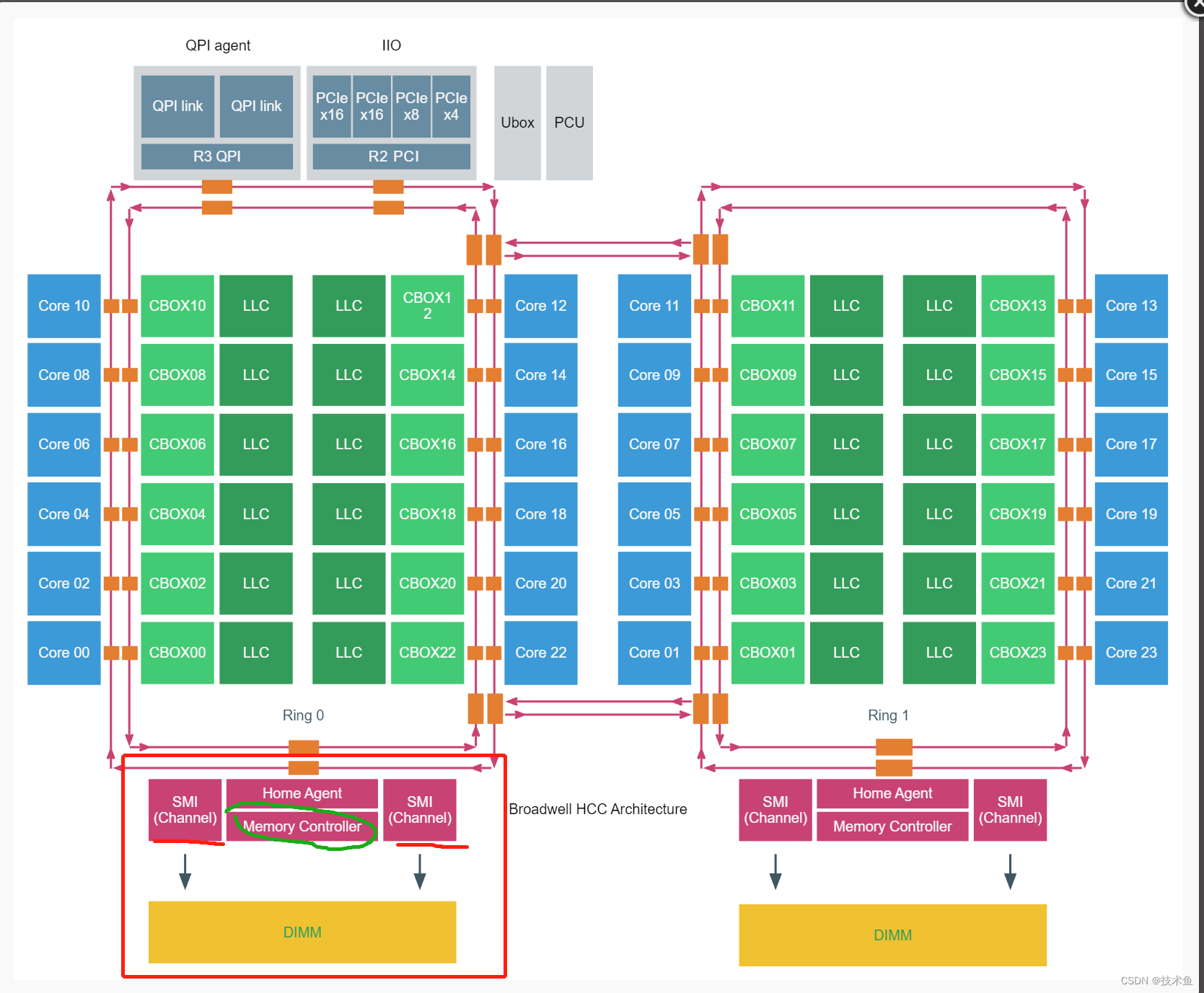
三、NUMA
(NUMA :(Non-Uniform Memory Access Architecture)
如下图,左右两边的是内存条,每个NUMA的cpu访问直接插在自己CPU上的内存必然很快,如果访问插在其它NUMA上的内存条还要走QPI,所以要慢很多。
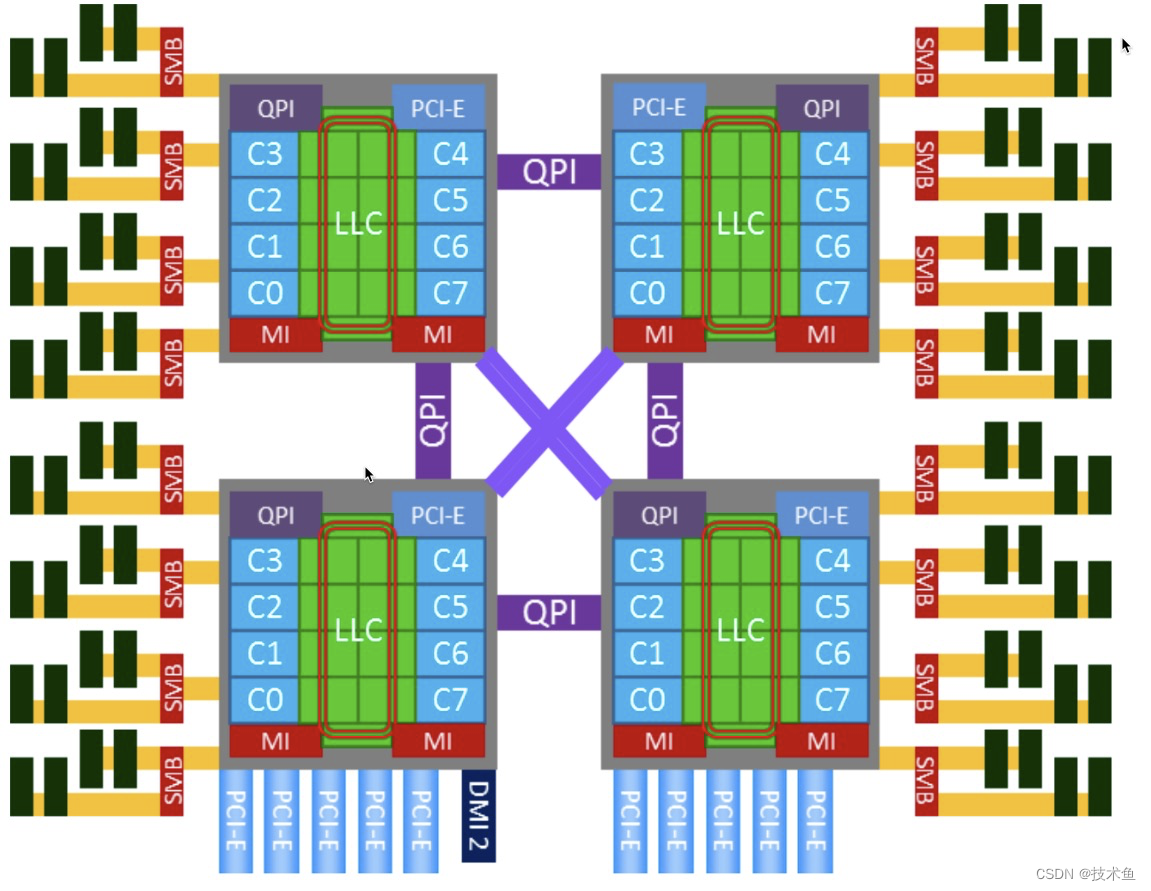
如上架构是4路CPU,每路之间通过QPI相连,每个CPU内部8core用的是双Ring Bus相连,Memory Control Hub集成到了Die里面。一路CPU能连4个SMB,每个SMB有两个channel,每个channel最多接三个内存条(图中只画了2个)。
快速通道互联[1][2](英语:Intel QuickPath Interconnect,缩写:QPI)[3][4],是一种由英特尔开发并使用的点对点处理器互联架构,用来实现CPU之间的互联。英特尔在2008年开始用QPI取代以往用于至强、安腾处理器的前端总线(FSB),用来实现芯片之间的直接互联,而不是再通过FSB连接到北桥。Intel于2017年发布的SkyLake-SP Xeon中,用UPI(UltraPath Interconnect)取代QPI。
socket
socket对应主板上的一个插槽(socket),也可以简单理解为一块物理CPU。同一个socket对应着 /proc/cpuinfo 里面的physical id一样。
一个socket至少对应着一个或多个node/NUMA
连接器
链接器: 扫描所有输入的目标文件,然后把所有符号表里的信息收集起来,构成一个全局的符号表。然后再根据重定位表,把所有不确定要跳转地址的代码,根据符号表里面存储的地址,进行一次修正。最后,把所有的目标文件的对应段进行一次合并,变成了最终的可执行代码。这也是为什么,可执行文件里面的函数调用的地址都是正确的。
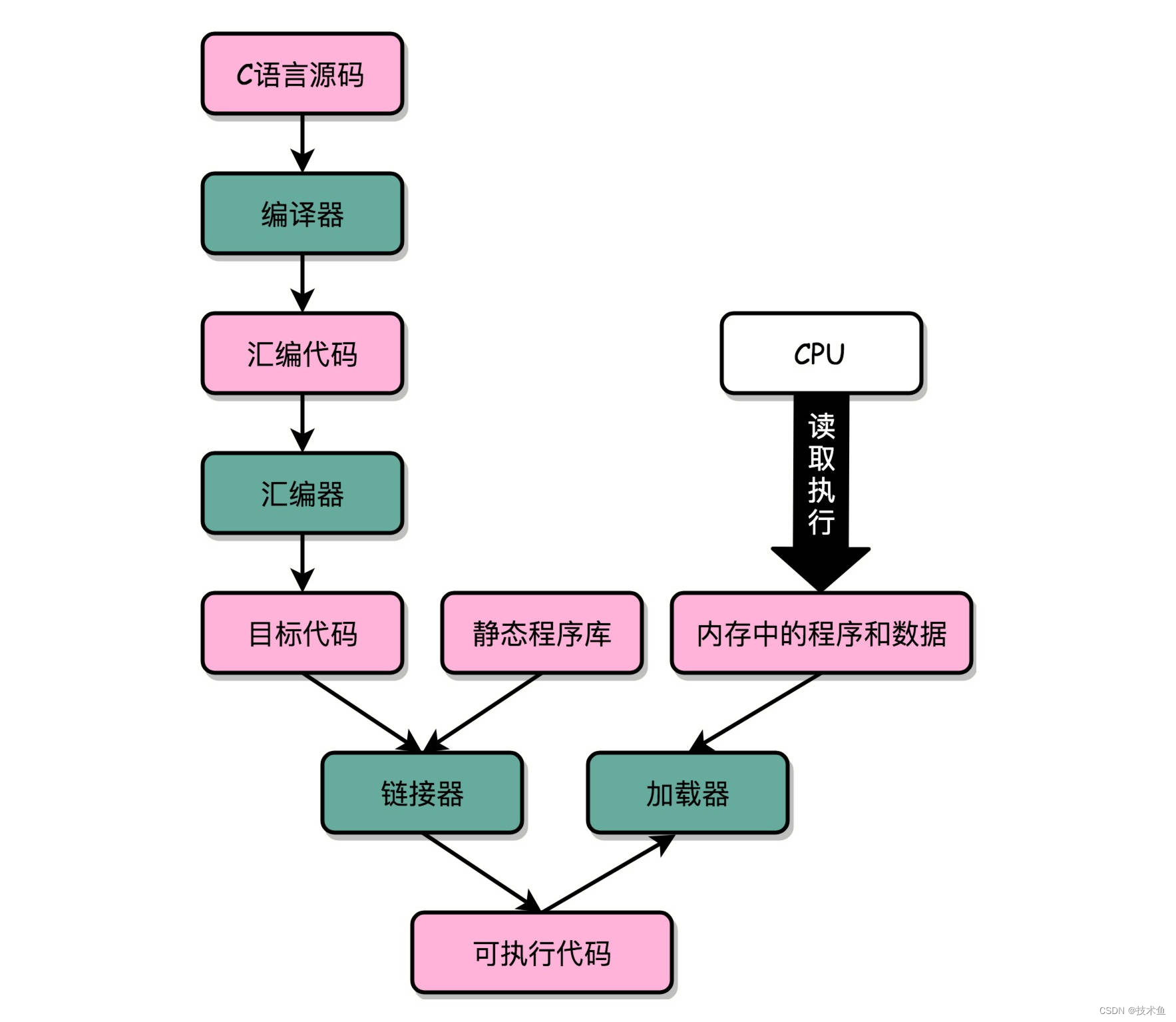
虚拟地址
虚拟内存地址:应用代码可执行地址必须是连续,这也就意味着一个应用的内存地址必须连续,实际一个OS上会运行多个应用,没办法保证地址连续,所以可以通过虚拟地址来保证连续,虚拟地址再映射到实际零散的物理地址上(可以解决碎片问题),这个零散地址的最小组织形式就是Page。虚拟地址本来是连续的,使用一阵后数据部分也会变成碎片,代码部分是不可变的,一直连续。另外虚拟地址也方便了OS层面的库共享。
为了扩大虚拟地址到物理地址的映射范围同时又要尽可能少地节约空间,虚拟地址到物理地址的映射一般分成了四级Hash,这样4Kb就能管理256T内存。但是带来的问题就是要通过四次查找使得查找慢,这时引入TLAB来换成映射关系。
共享库
共享库:在 Linux 下,这些共享库文件就是.so 文件,也就是 Shared Object(一般我们也称之为动态链接库). 不同的进程,调用同样的 lib.so,各自 全局偏移表(GOT,Global Offset Table) 里面指向最终加载的动态链接库里面的虚拟内存地址是不同的, 各个程序各自维护好自己的 GOT,能够找到对应的动态库就好了, 有点像函数指针。
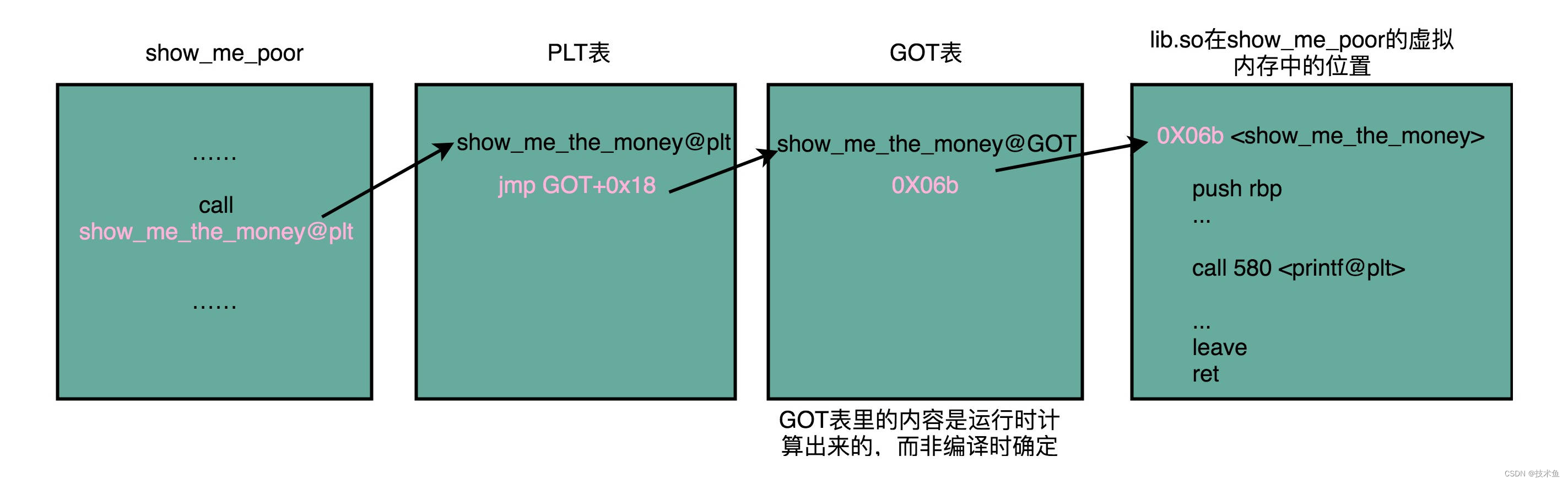
符号表
符号表:/boot/System.map 和 /proc/kallsyms
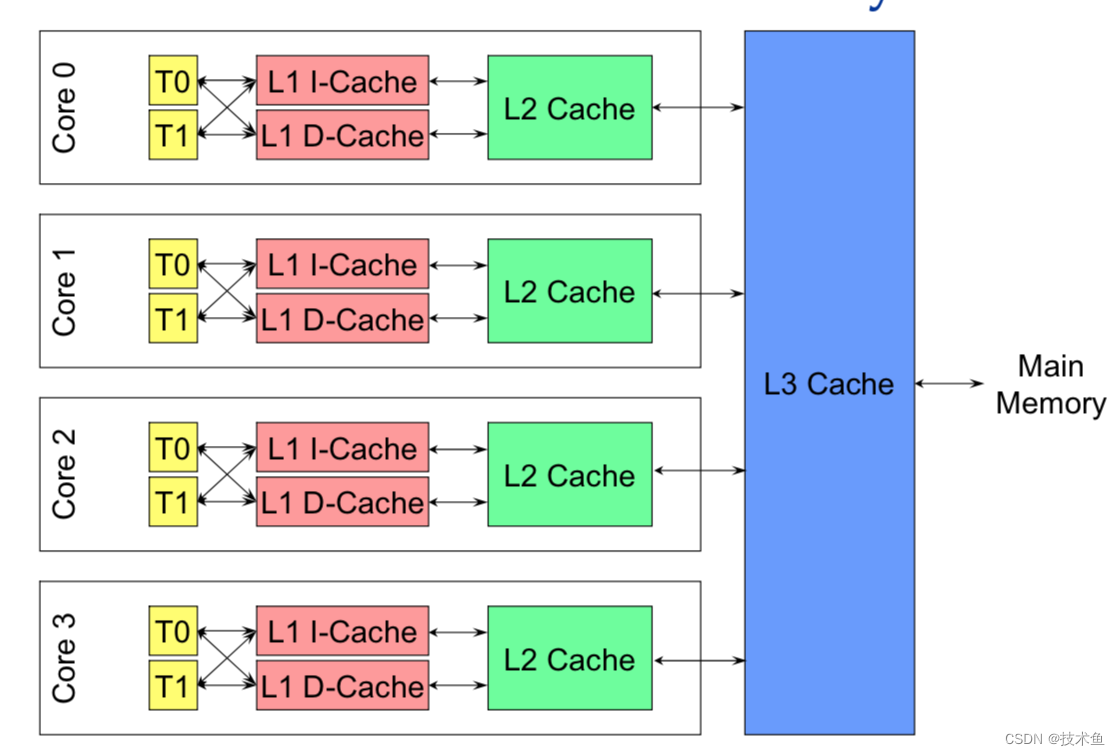
超线程
超线程(Hyper-Threading): 在CPU内部增加寄存器等硬件设施,但是ALU、译码器等关键单元还是共享。在一个物理 CPU 核心内部,会有双份的 PC 寄存器、指令寄存器乃至条件码寄存器。超线程的目的,是在一个线程 A 的指令,在流水线里停顿的时候,让另外一个线程去执行指令。因为这个时候,CPU 的译码器和 ALU 就空出来了,那么另外一个线程 B,就可以拿来干自己需要的事情。这个线程 B 可没有对于线程 A 里面指令的关联和依赖。















 84
84











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











