








共识算法:Paxos 算法
1. 目录
2. 共识问题 1
- 什么是共识问题?
粗略地说,该问题是在一个或多个进程提议了一个值应当是什么后,使进程对这个值达成一致协定。 - 解决什么问题?
- 在一个计算机提议一个动作后,控制引擎的所有计算机要决定“继续”还是“放弃”。
- 在互斥中,进程对哪个进程可以进入临界区达成协定。
- 在选举中,进程对当选进程达成协定。
- 在全排序组播中,进程对消息传递顺序达成协定。
2.1 一个例子:问题描述 2
假设有两支(或多支)军队,他们必须做到同时进攻或同时防守,否则就会失败。所有军队组成一个系统,他们必须共同动作。问题是,如何让他们步调一致?
现在不妨把军队看做”进程“,把进攻或防守看做一个变量”行动“。
在单机系统中,这个问题很容易解决。用一个互斥量就搞定了,类似于多线程。
在分布式系统中,这个问题就麻烦啦。假设每个进程都在不同的服务器上,他们就无法通过共享内存达到同步。如果进程是军队的话,军队之间只能通过通信兵来进行通信(消息传递)。基于消息传递的分布式军队系统会有这些问题:
- 如何确定另一支军队是否被干掉?(服务器崩溃)
- 如何知道通信兵是否被杀死(消息丢失)或久久未到达其他军队(延迟不可预知)?
- 如果马路等通信信道被切断怎么办?(网络分割)
2.2 另一个例子
在一个分布式数据库系统中,如果各节点(server,或进程)的初始状态一致,每个节点都执行相同的操作序列,那么他们最后能得到一个一致的状态。为保证每个节点执行相同的命令序列,需要在每一条指令上执行一个“一致性算法”以保证每个节点看到的指令一致,是分布式计算中的重要问题。
3. Paxos 的一致性原则 3
- Safety (坏的事情一定不会发生)
- 只有被提议的值才会被选择;
- 只能有一个值被批准,不能出现第二个值把第一个覆盖的情况;
- 每个节点只能学习到已经被批准的值,不能学习没有被批准的值 。
- Liveness (好的事情最终一定会发生)
- 最终会批准某个被提议的值;
- 一个值被批准了,其他进程最终会学习到这个值。
Paxos 只保证Safety,而不能保证Liveness。
4. Paxos算法描述
4.1 假设 4
每个server都可以担任三种角色:提案者(Proposer)、接受者(Acceptor)、学习者(Learner)。提案者负责提出提案(proposal),接受者负责通过提案,而学习者负责更新提案。
每个提案都会被分配一个自然数
n
作为ID,以及一个需要提出的值
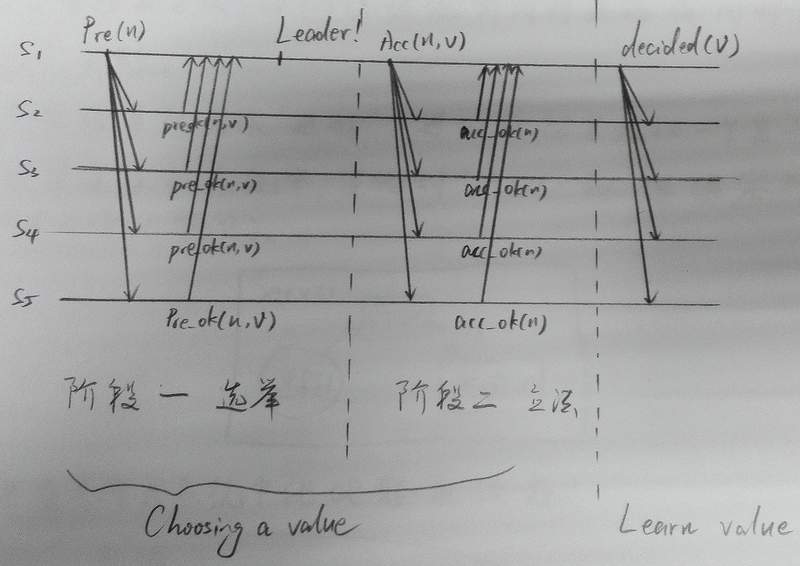
4.2 选择一个值(Choosing a Value) 5
阶段一
a. 提案者选择一个提案(proposal)编号
n
,向接受者多数派组播一个prepare请求。
b. 如果一个接受者收到一个prepare请求,并且编号
阶段二
a. 如果提案者收到一个接受者多数派的回应prepare_ok(n,na, va),那么他就选出最大的
b. 如果一个接受者收到一个 accept(n,v) 请求,并且
4.3 学习一个值(Learning a Chosen Value)
当一个提案被多数派通过,这提案者就向所有人(servers)发送decided(v),贯彻与落实这个
4.4 Paxos伪代码6
# Proposer
proposer(v):
while not decided:
n = heigher(N[:]) # 尝试分配一个当前最大的n值给这个proposal
send prepare(n) # 向所有acceptor发送prepare request
# 若大部分返回ok:
if prepare_ok(n, na, va) from majority:
# 从{na...}中选出最大的那个和对应的va,令v=va;否则,就选自己的v
v = va with heighest na; otherwise choose its own v
send accept(n, v) to all # 向所有acceptor发送accept request
if accept_ok(n) from majority:
send decided(v) to all # 决定v并通知所有成员
# Acceptor
acceptor state on each node (persistent):
np # 最大的promise值
na, va # 最大的accepted值
prepare(n) handler:
if n > np:
n = np
send prepare_ok(n) # 承诺不再接受任何比 n 小的proposal
else:
send prepare_reject
accept(n, v) handler:
if n >= np:
na = n
va = v
send accept_ok(n)
else:
send accept_reject直观理解
容错性分析(Fault tolerant) 7
究竟Paxos是如何保证一致性的呢?例子如下。
3.1服务器崩溃(crash)
若有 2f+1 台服务器,则最多可以容忍 f 台服务器崩溃。下面举一个简单的例子,假设一个分布式系统由5个servers组成,其中2个在任意时刻崩溃。存在两种情况:1.Acceptor或Learner崩溃了;2.Leader崩溃了。
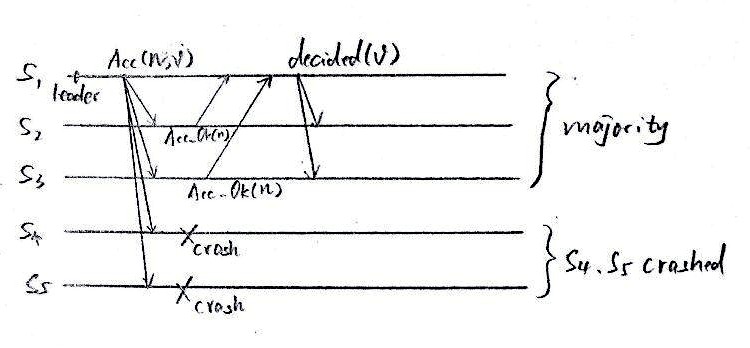
3.1.1. Acceptor 崩溃
如下图所示,S1为Leader,当其发出Accept请求时,S4和S5崩溃了。但是S1,S2,S3仍然构成多数派,所以
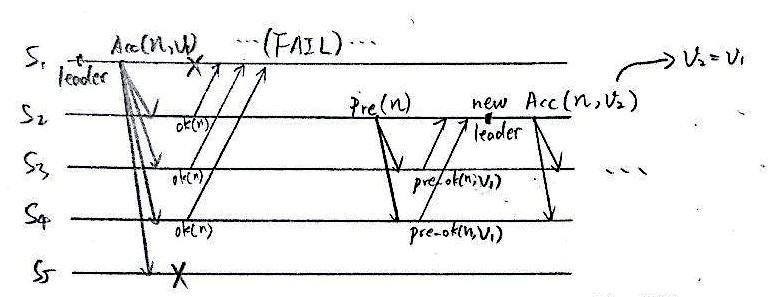
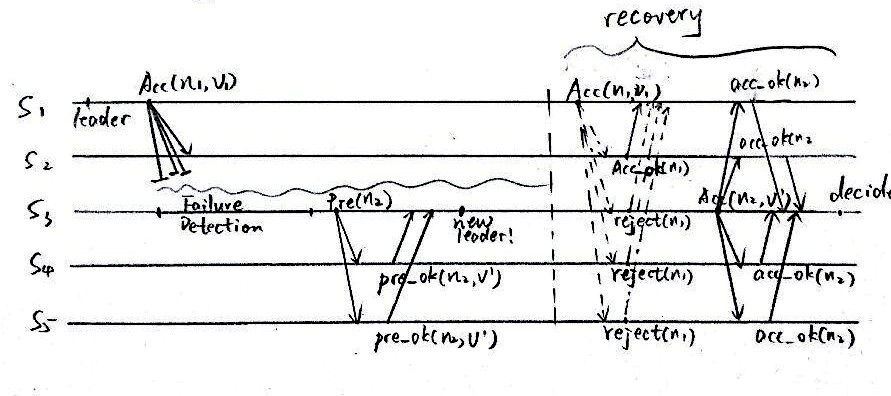
3.1.2. Leader 崩溃
Learder崩溃要稍微麻烦一点。首先要有错误检测,发现leader S1挂了。然后,因为没有leader了,所以要重新选举。如图,S1,S5挂了,但是S2,S2,S3仍然构成多数派。S2发出prepare请求,S3,S4返回最近接受的
v1
,
v1
再次被S2请求接受。于是
v1
还是成功被决定下来了。
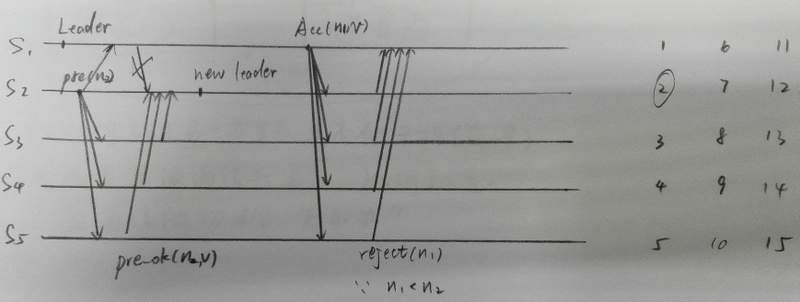
3.2 网络分割(network partitioning)
另一种常见错误是网络分割。如下图所示,S1,S2与S3,S4,S5之间的通信被断开,分成了两个子网络。在这种悲催的情况下,系统仍然可以达成共识。
一旦发生分割,通过错误检测是可以发现的,例如超时。然后多数派一方就会进行重新选举,如图,S3成为新leader。系统又可以正常运作了。
不过,问题还没完。如果网络通信在某一时刻又恢复正常,分布式系统中就会同时存在两个leader!Paxos还可以保证共识吗?是可以的。因为
n2>n1
,S3~S4 已经承诺不再接受比
n2
小的提案了。所以老leader S1的提案
(n1,v1)
会被拒绝,而S3的提案
(n2,v′)
会获得通过。
3.3 消息丢失(message lost)
由于网络层是不可靠的,消息丢失和延时是无法避免的。应对这类错误的主要方法还是重传。
参考文献
- 分布式系统:概念与设计, 共识和相关问题 系统模型和问题定义 ↩
- 分布式系统:概念与设计, 共识和相关问题 同步系统中的共识问题 ↩
- Lamport,L: Paxos Made Simple. ACM Trans. on Comp. Syst. ↩
- Lamport,L: Paxos Made Simple. ACM Trans. on Comp. Syst. ↩
- Lamport,L: Paxos Made Simple. ACM Trans. on Comp. Syst. ↩
- MIT 6.824 Lab 3: Paxos-based Key/Value Service ↩
- Tutorial Summary: Paxos Explained from Scratch ↩















 6459
6459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









