








 本文介绍了如何在系统行为数据中检测膝尖儿(Kneedle),一种表示曲线曲率降低的转折点。文章详细阐述了连续和离散数据下的曲率定义,以及基于角度、萌二曲率和EWMA方法的膝尖儿检测算法。离线和在线版本的膝尖儿检测算法在处理连续和实时数据时各有特点。
本文介绍了如何在系统行为数据中检测膝尖儿(Kneedle),一种表示曲线曲率降低的转折点。文章详细阐述了连续和离散数据下的曲率定义,以及基于角度、萌二曲率和EWMA方法的膝尖儿检测算法。离线和在线版本的膝尖儿检测算法在处理连续和实时数据时各有特点。
干草垛(Haystack)里找“膝尖儿(Kneedle)”:侦测膝点的系统行为
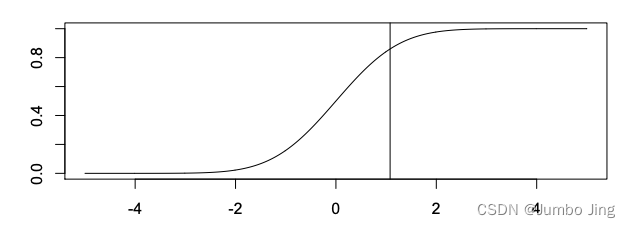
图1. 带有均值=0和标准偏差=1的标准高斯分布的CDF和相关曲率。垂直线表示最大曲率点。这似乎非常精确地匹配
膝尖儿的直观定义。 x = 0 x = 0 x=0 为拐点(reflection point)
缘起
-
引用:
Finding a “Kneedle” in a Haystack: Detecting Knee Points in System Behavior Ville Satopa † , Jeannie Albrecht† , David Irwin‡ , and Barath Raghavan§ †Williams College, Williamstown, MA ‡University of Massachusetts Amherst, Amherst, MA § International Computer Science Institute, Berkeley, CA
定义膝点-- Kneedl 膝尖儿
对于任何连续函数f,存在一个标准闭合形式 K f ( x ) K_f(x) Kf(x),它将 f f f在任何点的曲率定义为其一阶和二阶导数的函数:
K f ( x ) = f ′ ′ ( x ) ( 1 + f ′ ( x ) 2 ) 1.5 K_f(x) = \frac{f''(x)}{(1+f'(x)^2)^{1.5}} Kf(x)=(1+f′(x)2)1.5f′′(x)
导数也就是
K
f
(
x
)
K_f(x)
Kf(x)变化率, 一阶导数可以表示斜率
y
=
k
x
+
b
y = kx + b
y=kx+b , 如图1所示的
x
=
0
x = 0
x=0 的点, 作者认为这是所谓拐点(reflection points), 表现曲线增长率的最大值的点. 而曲率–二阶导数表示曲线和直线的最大差别点(how much a function differs from
a straight line), 如图1的垂线和曲线的交点, 也就是作者所定义的膝点(knee points): 膝尖儿 Kneedle.
- 注意⚠️: 虽然曲率对于连续函数是明确定义的,但对于离散数据集则不是明确定义的。在离散情况下,我们可以通过将连续函数拟合到数据并使用函数的最大曲率点来确定曲率。然而,将连续函数拟合到一组任意数据点是困难的,尤其是在数据有噪声的情况下。
此外,确定得到的函数的最大曲率可能是不够的,因为函数的任何点的曲率都取决于整个函数,包括不在相关数据集中的点。因此,最大曲率可能在数据的有效范围之外,或者是集合的终点之一。由于曲率的近似至少需要三个点——定义圆的最小点数——数据集中的端点根据定义没有曲率值。因此,使用闭式公式作为离散数据上膝尖儿检测的直接基础是不可能的。
离散数据集的膝尖儿侦测
基于角度
赵等人[13]的几何“基于角度”方法是聚类应用中检测膝尖儿的L方法的扩展[8]。基于角度的方法首先找到每个连续三重点的连续差的局部极小值(y1+y3−2y2)。例如,考虑一条穿过连续点(x1,y1)、(x2,y2)和(x3,y3)的直线。假设x值间隔均匀,则对于任何直线段,y1+y3−2y2=0。然而,如果这三个点形成膝尖儿,(x2,y2)必须在穿过(x1,y1)和(x3,y3)的直线之上。在这种情况下,y1+y3−2y2<0。“更锋利”的膝尖儿有更多的负差值。
接下来
由于连续的差异是局部测量,并且忽略了曲线的总体趋势,因此该算法将差异与角度值相结合。在获得连续差值的局部最小值后,该算法对最小值进行排序,并从具有最大差值的点开始,计算由y轴和穿过与相应差值相关联的每对连续点的线形成的两个角度。这两个角度之和就是角度值。在这些角度值的局部最大值处检测膝尖儿。
萌二曲率(Menger Curvature)
虽然曲率对于任意离散数据集没有明确定义, 但是萌二曲率将三个离散点的曲率定义为围绕这些点外接的圆的曲率[14]。因此, 我们将n点数据集中每个点 p i = ( x i , y i ) p_i=(x_i,y_i) pi=(xi,yi) 的萌二曲率定义为, 对于围绕 p 1 , p i p_1,p_i p1,pi 和 p n p_n pn 外接的半径为 r r r 的圆, 等于 1 / r 1/r 1/r。外切圆的曲率计算起来很简单,它只是以点为顶点的三角形边长度的函数。然而,正如我们在第四节中所示,虽然Menger非常接近从理想连续函数中提取的离线数据的曲率,但它对计算系统典型的有噪声的在线数据集并不适用。
EWMA
EWMA方法使用类似于Bollinger Bands[15]和用于变化检测的几何移动平均算法[16]所使用的技术。我们使用的算法基于Albrecht等人在其关于部分屏障的工作[3]中描述的方法,该方法源于之前关于MONET的工作[17]。EWMA是一种使用两个指数加权移动平均线的在线算法。第一个EWMA称为arr,用于平滑输入数据,这被视为主机到达时间。第二个EWMA,arrvar,跟踪arr的平均偏差,是对到达时间方差的估计。最后,这两个值用于计算arr+4·arrvar的最大等待阈值,该阈值表示等待下一个点到达的最大时间。如果该点在该阈值之后到达,或者在没有看到下一个到达的情况下达到阈值,则EWMA声明膝尖儿。该算法的一个重要特性是,EWMA不会直接报告膝尖儿点的位置——它只确定膝尖儿是否已经通过。因此,EWMA仅适用于在线设置。
III. 膝尖儿 的算法
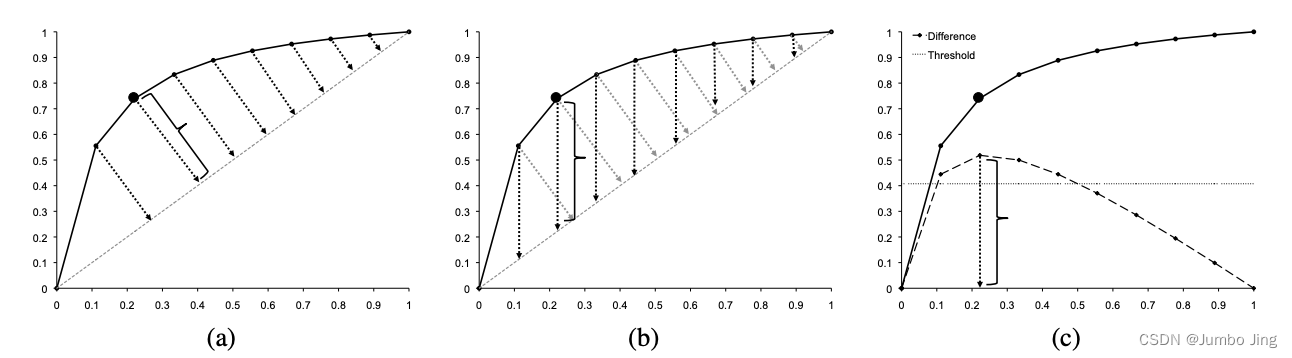
图2:用于在线
膝尖儿检测的膝尖儿算法。(a) 描绘了平滑和归一化的数据,虚线条指示从y=x到所指示的最大距离的垂直距离。(b) 显示了相同的数据,但这次虚线条旋转了45度。这些条的大小与膝尖儿中使用的差值相对应。(c) 示出了这些差值和相应阈值(其中S=1)的曲线图。膝尖儿在x=0.22处被发现,并且在接收到点x=0.55之后被检测到。
我们总结膝尖儿如下. 简单地说,当曲线变得更“平坦”时,膝尖儿就会出现,这表明曲率降低。该算法的工作原理如下:
- 首先,我们使用平滑样条线来尽可能地保持原始数据集的形状,尽管也可以使用其他平滑技术,如指数加权移动平均。我们设 D s D_s Ds 为定义平滑曲线的 x x x 和 y y y 值的有限集合,即已拟合到平滑样条曲线的曲线。
D s = { ( x i , y i ) ∈ R 2 ∣ x s i , y s i ≥ 0 } D_s = \{(x_i, y_i)\in R^2 | x_{si}, y_{si} \geq 0\} Ds={(xi,yi)∈R2∣xsi,ysi≥0}
- 我们希望我们的算法以相同的方式运行,而不管底层数据中的值的大小。因此,我们接下来将平滑曲线的点归一化为单位正方形,如图2(a)所示。这不会改变数据集的形状或趋势:
D s n = { ( x s n i , y s n i ) } , w h e r e D_{sn} = \{(x_{sn_i}, y_{sn_i})\}, where Dsn={(xsni,ysni)},where
x s n i = ( x s i − m i n { x s } ) / ( m a x { x s } − m i n { x s } ) x_{sn_i} = (x_{s_i} - min\{x_s\}) / (max\{x_s\} - min\{x_s\}) xsni=(xsi−min{xs})/(max{xs}−min{xs})
y s n i = ( y s i − m i n { y s } ) / ( m a x { y s } − m i n { y s } ) y_{sn_i} = (y_{s_i} - min\{y_s\}) / (max\{y_s\} - min\{y_s\}) ysni=(ysi−min{ys})/(max{ys}−min{ys})
- 接下来,我们让 D d D_d Dd 表示 x x x 值和 y y y 值之间的差集,即 D d = { ( x d i , y d i ) } D_d = \{(xd_i, yd_i)\} Dd={(xdi,ydi)},其中 x d i = x s n i xd_i = x_{sn_i} xdi=xsni, y d i = y s n i − x s n i yd_i = y_{sn_i} - x_{sn_i} ydi=ysni−xsni。这样做的原因是,我们希望在平滑曲线的每个点处都有一个“垂直”线,该线与曲线的斜率相同。这些垂直线的交点是曲线的局部最大值,因为它们是曲线与连接第一个和最后一个数据点的直线段差异最大的点。这些点的集合是曲线的最大曲率点的近似值。我们将这些点称为 D d D_d Dd 的“垂直”点,如图2(b)所示。
D s n = { ( x s n i , y s n i ) } , w h e r e D_{sn}=\{(x_{sn_i}, y_{sn_i})\}, where Dsn={(xsni,ysni)},where
x d i = x s n i , xd_i = x_{sn_i} , xdi=xsni,
y d i = y s n i − x s n i yd_i = y_{sn_i} - x_{sn_i} ydi=ysni−xsni
- 为了找到归一化曲线中的拐点,例如,曲线变平的地方,我们计算差分曲线的局部最大值。这些点表示y的增加率开始降低的情况。这些局部最大点中的每一个都是原始数据曲线中的候选拐点:
D l m = { ( x l m i , y l m i ) } , w h e r e D_{lm} = \{(x_{lm_i}, y_{lm_i})\}, where Dlm={(xlmi,ylmi)},where
x l m i = x d i , x_{lm_i} = xd_i , xlmi=xdi,
y l m i = y d i ∣ y d i − 1 < y d i , y d i + 1 < y d i y_{lm_i} = yd_i | yd_{i-1} < yd_i, yd_{i+1} < yd_i ylmi=ydi∣ydi−1<ydi,ydi+1<ydi
- 对于差异曲线中的每个局部最大值
x
l
m
x
i
x_{lmx_i}
xlmxi,我们定义了一个唯一的阈值
T
l
m
x
i
T_{lmx_i}
Tlmxi,该阈值基于连续
x
x
x 值和灵敏度参数
S
S
S 之间的平均差异。灵敏度参数允许我们调整在侦测
膝尖儿时, 希望膝尖儿有多积极。S的值越小,侦测膝尖儿的速度越快,而值越大则越保守。简单地说, S S S是在声明膝尖儿之前,我们期望在未修改的数据曲线中看到多少“平”点的度量。我们在第四节中探讨了 S S S 的选择。在图2(c)中,阈值线用 S = 1 S=1 S=1 绘制。
T l m x i = y l m x i − S ⋅ ∑ i = 1 n − 1 ( x s n i + 1 − x s n i ) n − 1 T_{lmx_i} = y_{lmx_i} - S\cdot \frac{ \sum_{i=1}^{n-1} (x_{sn_{i+1}} - x_{sn_i})}{n-1} Tlmxi=ylmxi−S⋅n−1∑i=1n−1(xsni+1−xsni)
- 若在达到差值曲线中的下一个局部最大值之前,任何差值
(
x
d
i
,
y
d
i
)
(xd_i, yd_i)
(xdi,ydi) , 其中
i
>
j
i>j
i>j 下降到阈值
T
l
m
x
i
T_{lmx_i}
Tlmxi 以下,则
膝尖儿在对应的局部最大值 x = x l m x i x=x_{lmx_i} x=xlmxi 的 x x x 值处声明拐点。如果差值达到局部最小值,并且在达到 y = T l m x i y=T_{lmx_i} y=Tlmxi 之前开始增加,则我们将阈值重置为0,并等待达到另一个局部最大值。
请注意, 膝尖儿 可以离线运行,也可以在线运行。在在线情况下, 膝尖儿 可以在收到积分时根据需要“更正”旧的膝尖儿值。对于任何给定的n对x和y值, 膝尖儿 的在线运行时间由
∑
i
=
1
n
i
=
O
(
n
2
)
\sum_{i=1}^ni=O(n^2)
∑i=1ni=O(n2) 限定。
未完待续( 复现膝尖儿)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









