







本篇博文将以不同论文(本人所看过的论文中)为出发点,分析每篇论文解决的问题、发现的新问题、问题处理的进展以及处理问题的方式是否真的达到预期性能表现;期待能够深入挖掘一些新的问题。
人群计数的方法分为传统的视频和图像人群计数算法以及基于深度学习的人群计数算法,深度学习算法由于能够方便高效地提取高层特征而获得优越的性能是传统方法无法比拟的,因此今后高性能的人群计数算法很大程度上会采用深度学习的方法。当然,传统基于运动信息人群分割的算法也有自己的一个优点,就是能够统计视频中不同方向人流的人数;(参考:https://mp.weixin.qq.com/s?__biz=MzI1NTE4NTUwOQ==&mid=2650325105&idx=1&sn=939f46fd57a80f86b9eb050dd2cf1652&scene=23&srcid=0719aUJR2CUdt7cmOII0KKol#rd)
1、2均是基于深度学习的方法,学习到高效的图像表示,在一个回归框架中利用这个达到人群计数和密度估计;
2是follow的1的工作;
1.(CVPR2015)《Cross-scene Crowd Counting via Deep Convolutional Neural Networks》
解决问题:现存的很多人群计数的方法在跨场景(即训练集中没有的场景)运用中的性能都不好;
(1)开发高效的特征来描述人群,人群场景需要新的特定描述信息;
(2)因为场景之间存在不同的透视扭曲、人群分布以及光照条件,因此在没有另外的训练数据的情况下,场景之间的计数模型很难互相使用;
(3)困难点:前景分割;
(4)现存的人群计数数据集不足以支持跨场景人群计数;
提出方法:提出DCNN,交替优化密度图估计和人数估计问题;提出一种数据驱动(ref:Data-driven crowd analysis in videos)的方法微调CNN模型(However, instead of directly transferring labels to the target scene like existing methods, we propose to use the training samples that fits the estimated crowd density distribution to fine-tune (adapt) the pre-trained CNN model to the target scene);提出一个新的数据集,包含108种应用场景,同时有将近200000个人头标注;
目标:从图像到人群总数之间学习一个映射关系,再将这个映射关系运用到没见过的场景中;
创新点:(1)我们提出的方法CNN模型可以学习到特定的人群场景特征,相比手工标注特征更具有高效性和鲁棒性;
(2)预训练CNN模型针对每个目标场景都进行微调来克服域间隔;
(3)框架不依赖于前景分割;crowd texture可以被CNN模型捕捉到产生一个合理的结果;基于像素和基于纹理都是得到总人数,它们不能区分出个体
(4)引入一个目前为止用来评估人群总数的最大的数据集;
(5)指出paper《Learning to count objects in images》中提出的方法不适用于人群计数,更适用于计算圆形的物体,比如细胞等; 将几种分布与透视规范化相结合, 建立了人群密度图,
输出人群密度图+人数总数;
不足:此方法是基于密度图得到人群总数,不能判别个体;在训练和测试过程中都需要透视图,但是在人群计数的许多实际应用在,透视图并不好获取;不同于其他密度回归方法,本文方法不需要前景分割(The framework does not rely on foreground segmentation results because only appearance information is considered in our method. No matter whether the crowd is moving or not, the crowd texture would be captured by the CNN model and can obtain a reasonable counting result);这事基于单一CNN的模型难以提取scale-relevant特征,在crowd images中很难处理尺度变化;

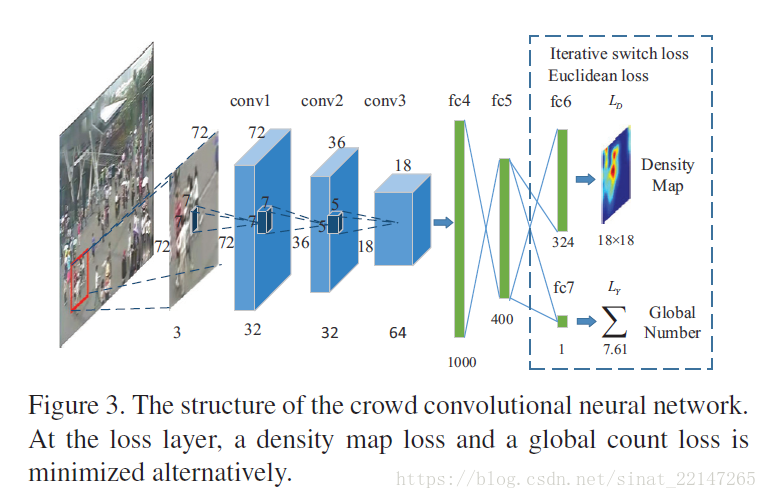
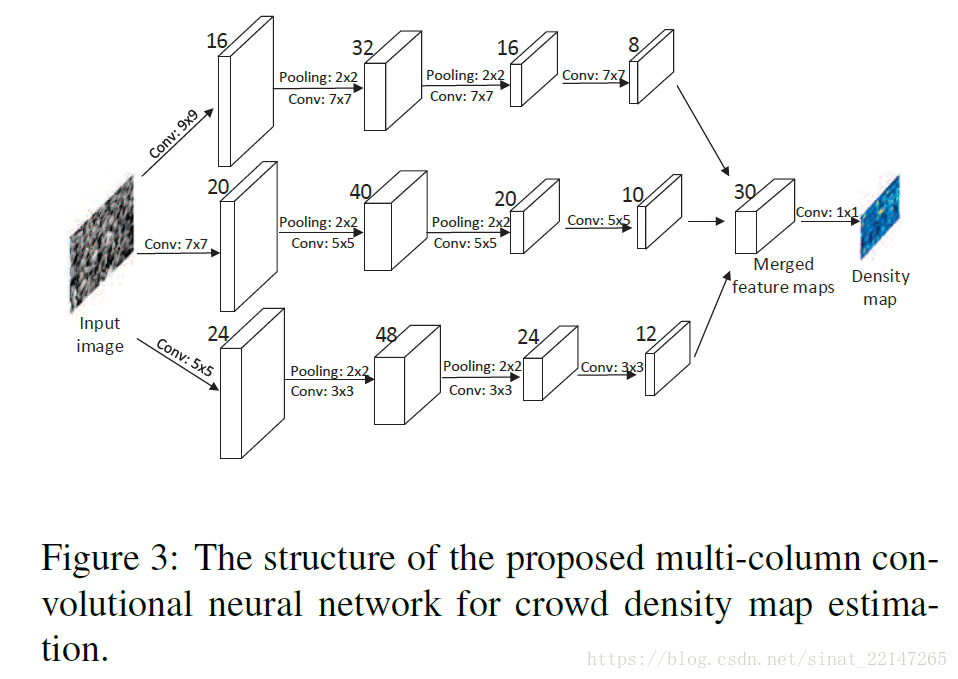
2.(CVPR2106)《Single-Image Crowd Counting via Multi-Column Convolutional Neural Network》
解决问题:针对一张任意尺寸、分辨率的任意人群密度及任意远景图;
提出方法:多列卷积神经网络(MCNN)将图像匹配到人群密度图;通过使用不同尺寸的感受野,每列CNN学到的特征适应因为图片分辨率及透视的不同,产生的人头尺寸变化;此外, 基于几何自适应核, 不需要知道输入图像的透视图, 准确地计算出真实密度图(Density map via geometry adaptive kernels);提出一个新的数据集Shanghaitech,包含1198张带有330000个人头标注的图片。
贡献:(1)抛弃前景分割这个操作;
(2)为了更精确地估算不同图像地人群密度,我们利用不同尺度整合估算;
(3)人群计数最常用的是基于特征回归的方法,参考博文:
https://blog.csdn.net/u011285477/article/details/51954989
结果:MCNN模型表现很好,并具有可迁移性。
本文方法受MDNN驱动;
不足:这些方法能相对压制尺度变化问题,但是仍存在两个缺点:多列/多网络需要预训练但网络for global optimization,比端到端训练更复杂;多列/多网络会引入更多的参数,消耗计算资源,难以实际应用。
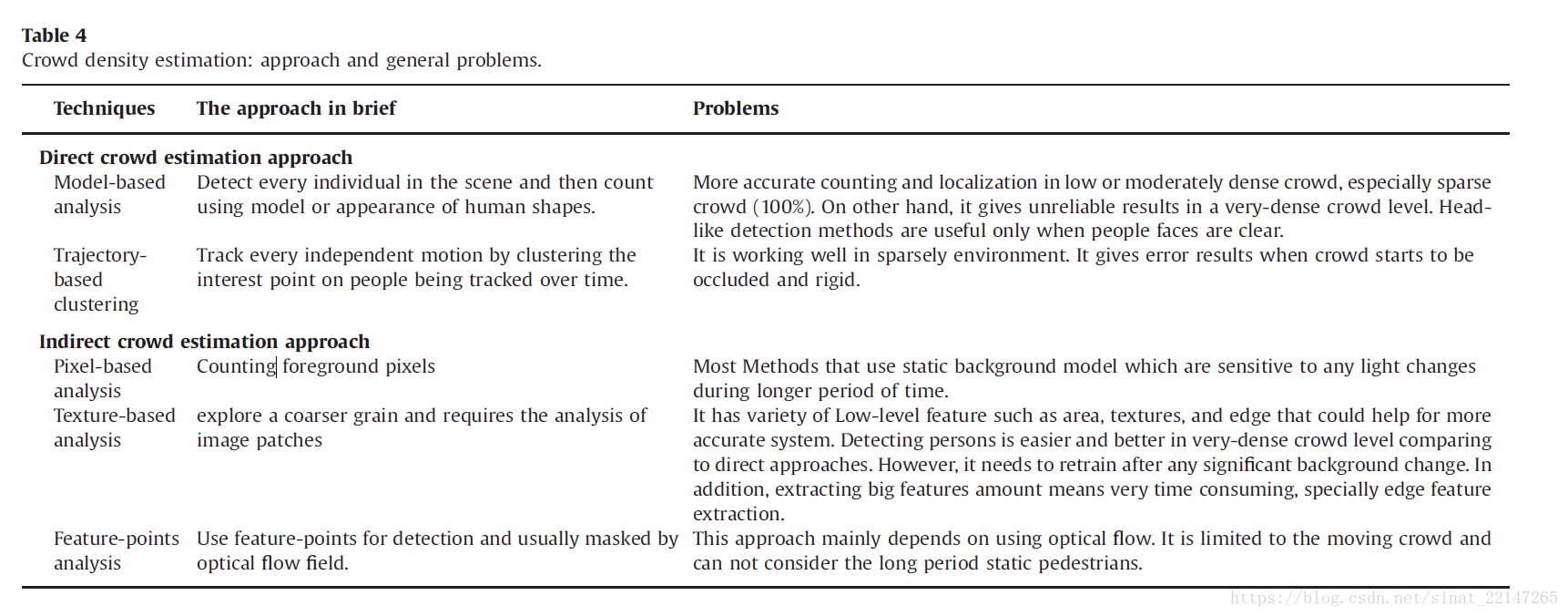
//穿插一篇survey paper:《Recent survey on crowd density estimation and counting for visual surveillance》
这篇survey主要覆盖两个方向:直接法及间接法;
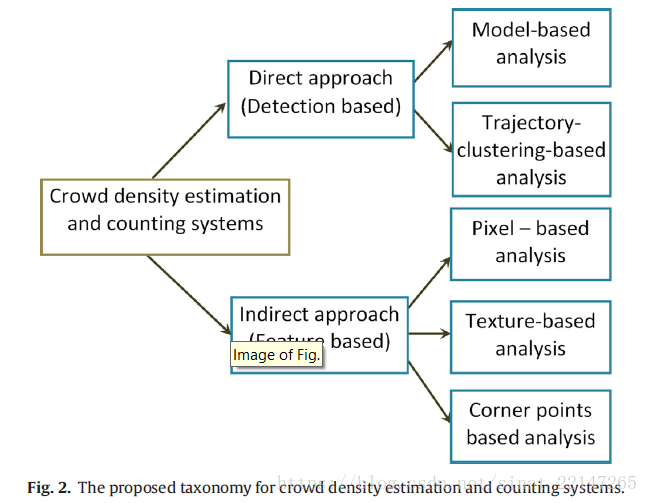
直接法:
基于模型的检测:整体检测;人头识别检测;
基于轨迹聚类的分析:文中提到的方法都是无监督学习并且完全依赖于聚类个体行动

间接法:更为高效,因为特征检测比检测人更简单;问题:透视问题;
在高密度人群中识别个体是件很困难的事情,现在大多数方法更关注于间接方法,在一些特征和人数之间习得映射关系。
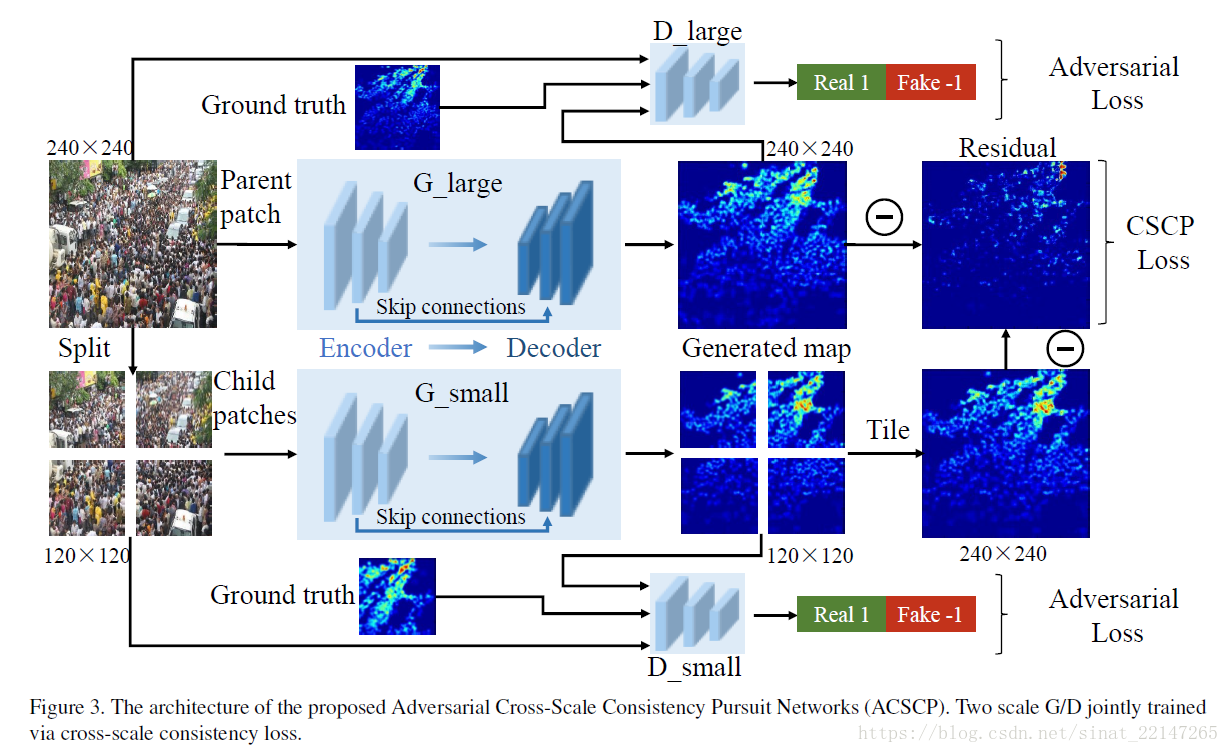
3.(CVPR2018)《Crowd Counting viaAdversarial Cross Scale Consistency Pursuit》
解决问题:现存的密度估计方法有以下两个问题:(1)由不同大小的CNN融合得到的图像多尺度特征,再经传统的L1/L2回归用来计数的人群密度图会导致密度图模糊;(2)跨尺度统计人数带来误差;
提出方法:提出一个新的密度估计框架:对抗跨尺度一致性追求(ACSCP);
(1)U-net结构的生成网络产生密度图;
(2)对抗损失减少密度图的模糊影响,对抗损失可以促进模型之间的合作;
(3)设计了一个新的尺度一致性正则化项:约束了计数上的跨尺度误差;
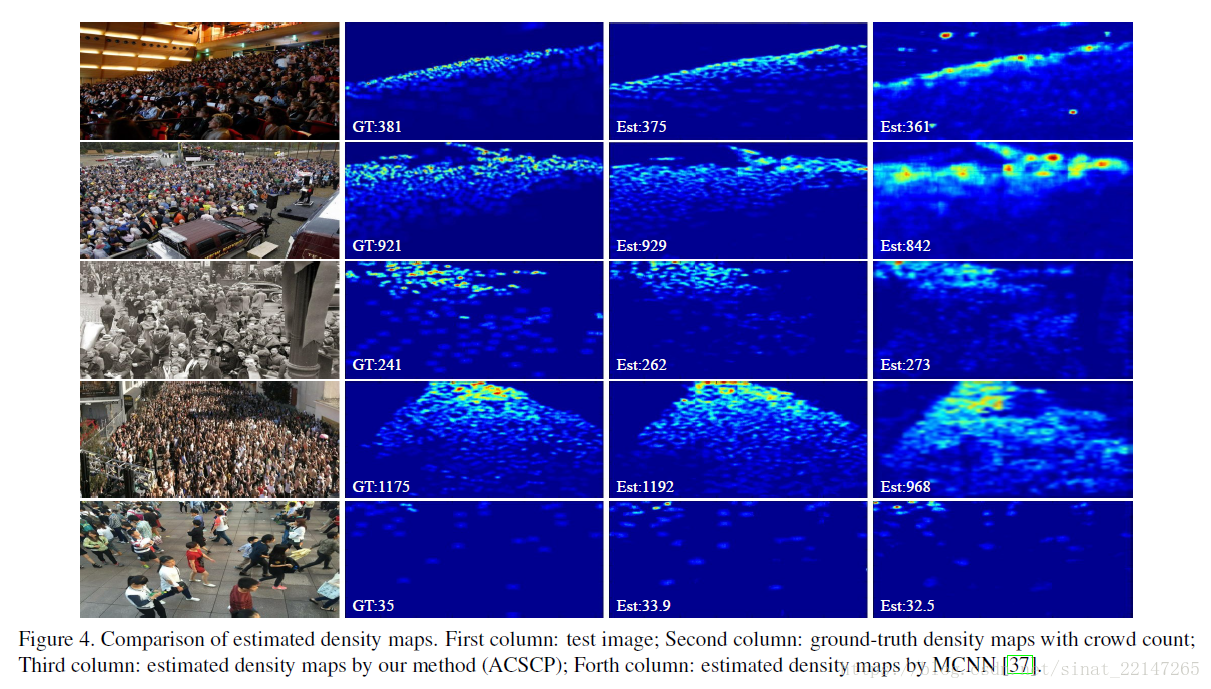
结果:在实验部分可以看到,比MCNN表现是好的;

4.(CVPR2018)《Leveraging Unlabeled Data for Crowd Counting by Learning to Rank》
解决问题:人群计数现存的数据集规模有限;
提出方法:利用大量未标记数据,将排序数据嵌入到人群密度估计的方式;自监督的方式;
主要思想:在一个较大块内的较小块内的人数比较大块中的少或者两者差不多;
结果:从未标记的数据集中高效学习;
提出MCNN等方法有个特点:these person counting and crowd density estimation techniques are highly data-driven,这些方法要求每个人在图像中都标注出来;

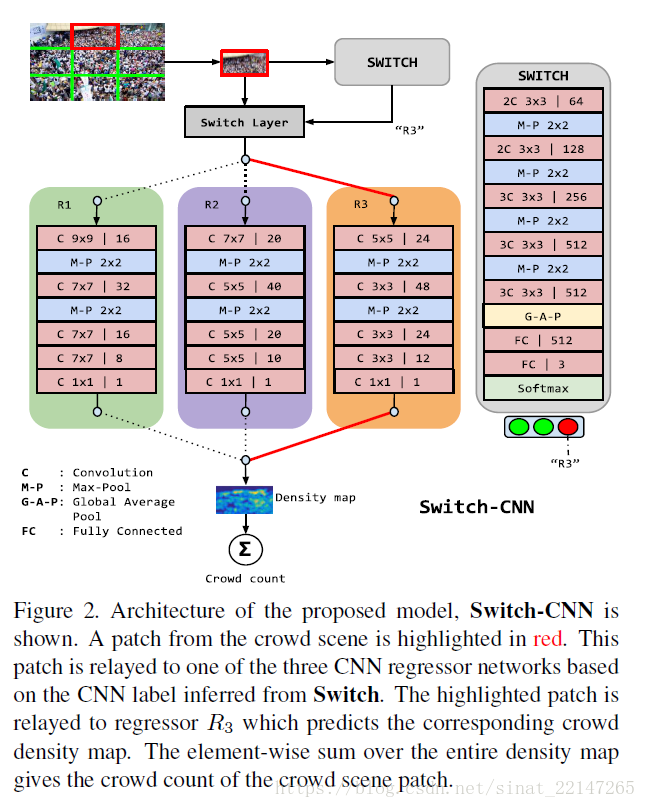
5.(CVPR2017)《Switching Convolutional Neural Network for Crowd Counting》
解决问题:人群计数的大量问题,之前有工作比如MCNN方式解决这些问题;
提出方法:提出交换卷积神经网络,利用一个图片内的密度变化增加预测人群总数的准确性;设计拥有不同感受野和训练一个交换分类器的独立CNN回归元,将人群场景块匹配到最合适的CNN回归元;
创新点:(1)模拟大规模变化的能力;(2)在一个人群场景中利用密度的局部变化的技术;
结果:
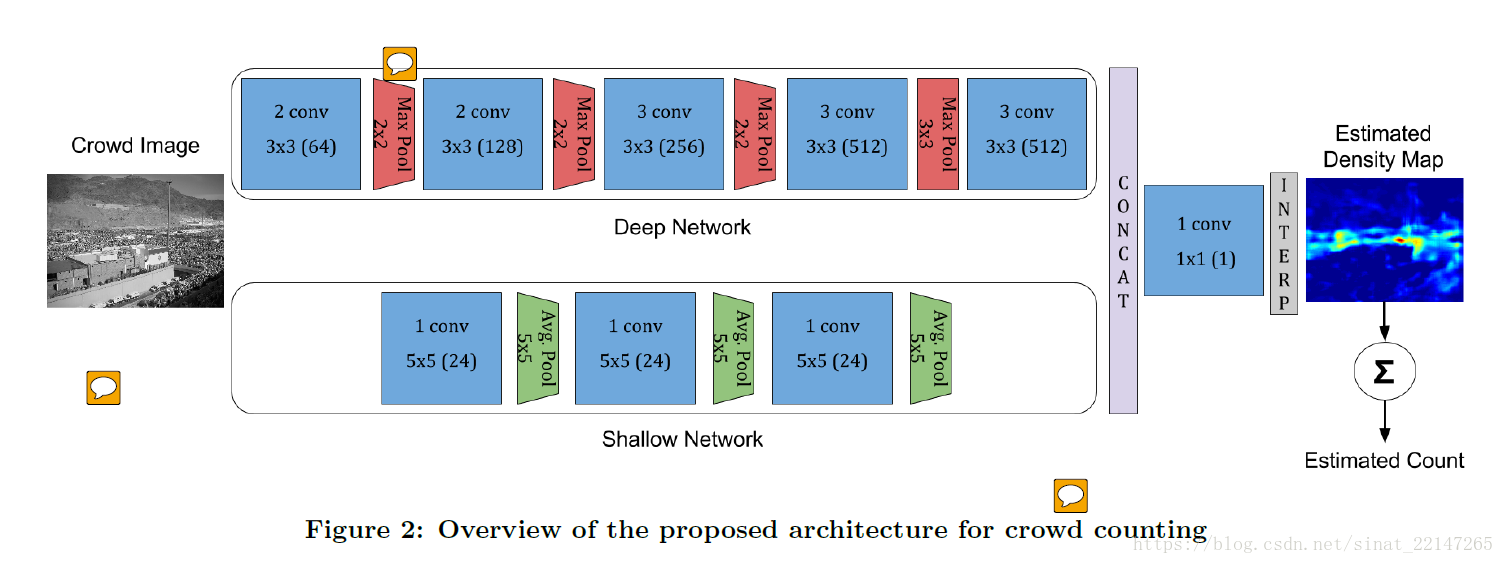
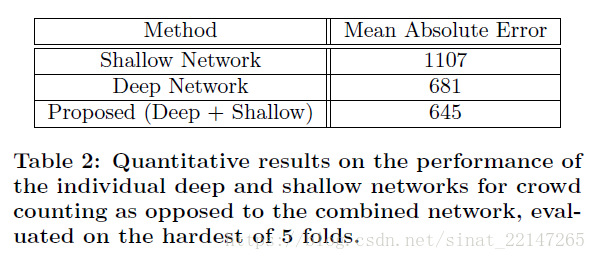
6.(2016)《CrowdNet: A Deep Convolutional Network for Dense Crowd Counting》
解决问题:提出了一个新的深度学习框架用于在一张静态的高密度图片中进行人群密度的估计;基于深度学习的方法需要大量的训练数据,但是许多人群数据集的样本非常有限(<100张图像);
提出方法:使用深和浅联合的全卷积网络;采用了多规模数据增广;
结果:这种方法可以捕捉到高级语义信息(脸/身体检测),以及低级特征(blob detectors);数据增广帮助CNN学习尺度不变性表示(因为人群计数有个透视问题,会引起人群的非均匀缩放);在UCF_CC_50上 实验,结果不错;
指出1的工作需要大量透视图,但是透视图的获取非常费力;

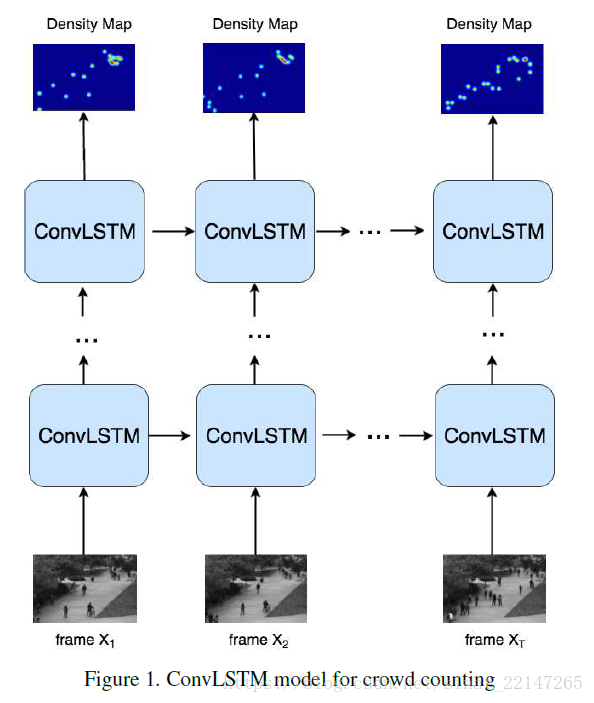
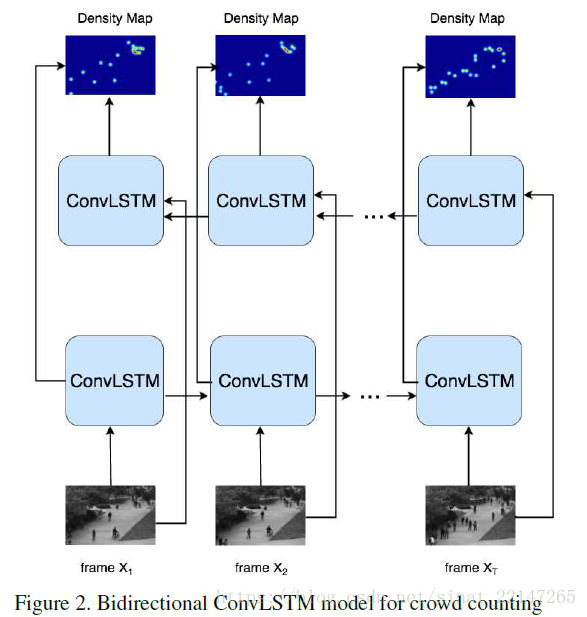
7.(ICCV2017)Spatiotemporal Modeling for Crowd Counting in Videos
提出方法:提出了一个深度学习模型卷积LSTM(ConvLSTM);扩展ConvLSTM至双向ConvLSTM模型;具有迁移性;
视频中的人群计数分为两类:(1)ROI计数(Region of Interest):在一定时间估计一块区域地人群总数;(2)LOI计数(Line of Interest):在一定时期内穿过检测线的人数总数;
这篇文章关注于ROI计数;
监督计数方法分为两大类:(1)基于检测的方法;(2)基于回归的方法:此处提一句基于CNN的方法,它不同于传统的基于回归的方法,不需要手工标注的特征,可以以一种端到端的方式学习到有力的特征;并且在处理视频数据时,基于CNN的方法会忽略相邻帧间的时间关系;
计数方法follow的是论文《learning to count objects in images》;克服透视扭曲,需要使用透视图M(p)来归一化人群密度图;
结果:将时空信息都考虑上,同时人群移动信息可以提高在复杂场景中更高的计数准确性;
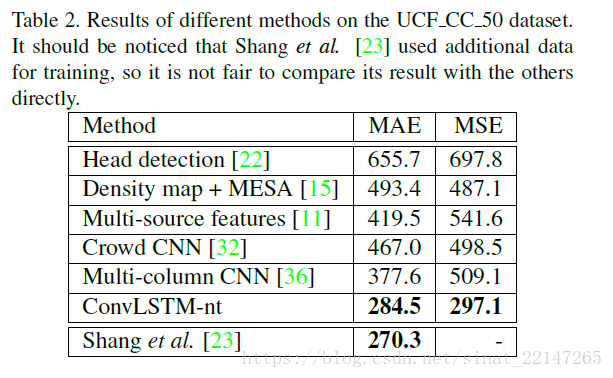
8.(CVPR2017)《MULTI-SCALE CONVOLUTIONAL NEURAL NETWORKS FOR CROWD COUNTING》
提出方法:针对单张图片的人群计数,提出了一个多尺度卷积神经网络(MSCNN);基于multi-scale blobs,这个网络可以在一种单列的架构中针对高度密集计数产生尺度相关的特征;
结果:精确度和鲁棒性都很好,并且有更少的参数;
密度图的产生使用的是论文《Learning to count objects in images》中的方法;
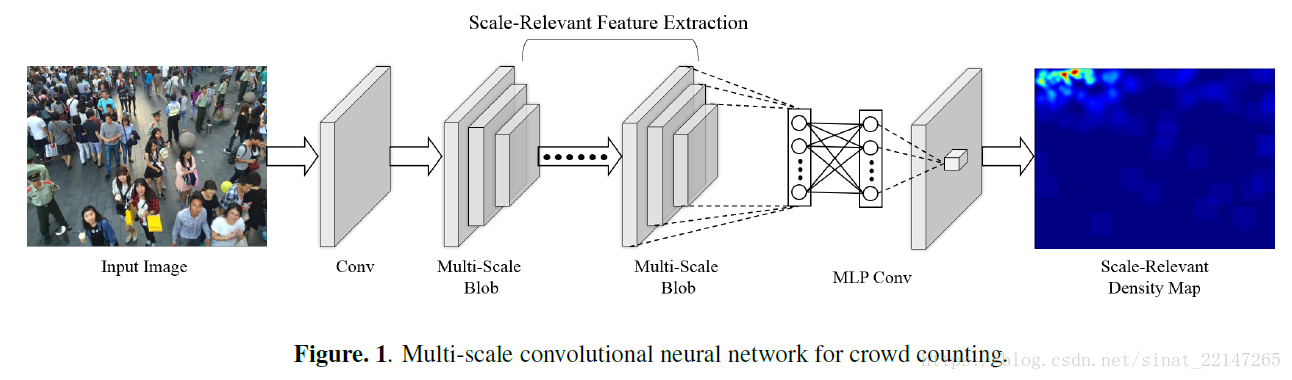
这幅图和MCNN有什么区别吗??
9.(2017)《A survey of recent advances in CNN-based single image crowd counting and density estimation》
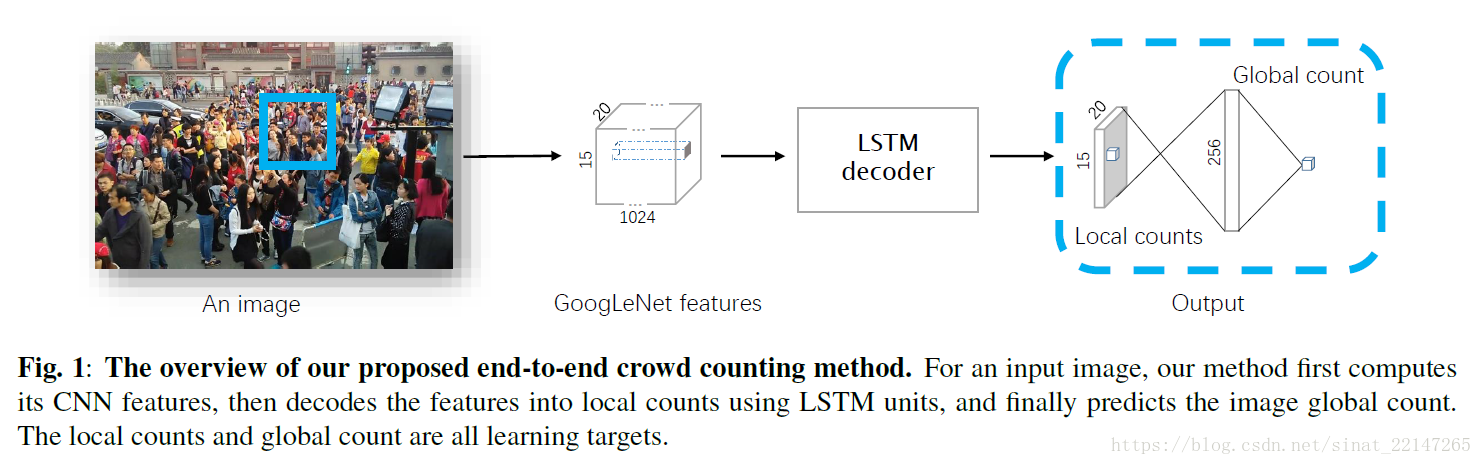
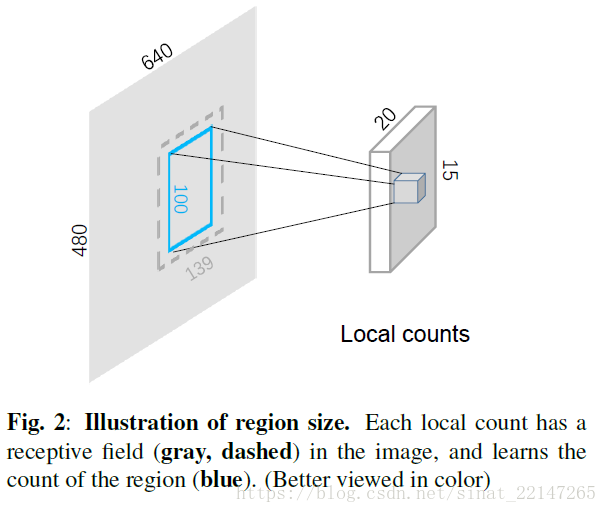
10.(IEEE2016)《END-TO-END CROWD COUNTING VIA JOINT LEARNING LOCAL AND GLOBAL COUNT》
提出方法:在利用重叠区域的共享计算时,我们的方法在预测本地和全局计数时利用上下文信息。
结果:在几个具有挑战性的数据集上进行实验,结果不错;
11.(ICCV2015)《Bayesian Model Adaptation for Crowd Counts》
提出方法:基于高斯过程的贝叶斯模型适应方法被提出;这个新的适应过程基于多任务学习,
结果:实验结果表明,针对容量扩展问题,模型适应比迁移学习更合适;
transfer learning for crowd counting;
和1都是用来进行不同场景的适应吗?

12.(ICCV2103)《From Semi-Supervised to Transfer Counting of Crowds》
解决问题:现存的许多基于回归的方法在模型训练的过程中都需要大量的费力的数据标注;
提出方法:(1)抛弃费力地标注每一帧的做法,选出最含信息量的帧;(2)利用大量未标记的数据;(3)为了减轻数据标注的压力,利用其他场景的标记数据;采用的迁移学习方式是aunified active和半监督回归框架,通过流形分析利用人群模式潜在的几何特征;
结果:the lack of labelled data in a new scene can be helped by knowledge transferred from other scenes in minimising the effort required for bootstrapping crowd counting at the new scene;
不足:we imposed an assumption that the source and target data sharing a similar manifold representation
提出概念Transfer counting;
比1的效果是不是好?答:不;因为1的方法不仅可以得到计数还有密度图;而此方法只能得到计数;
待续...















 6883
6883











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









