







线性回归:
根据样本学习从x到y的映射关系,如y=W^T·x+b,利用这个映射关系对未知数据进行预估,因为y是连续实值,故为回归问题;
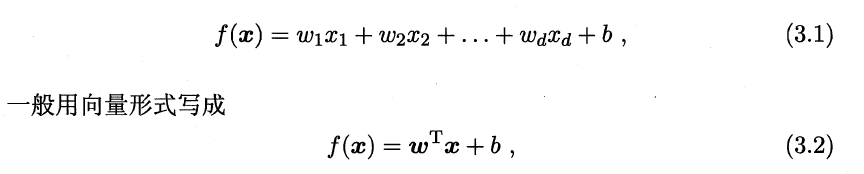
·损失函数: 最小二乘;平方损失函数
·正则化:
L1正则化:
Lasso回归;产生稀疏权值矩阵(指很多元素为0,只有少数是非零值的矩阵,也就是得到的线性回归模型大部分系数为0);可用于特征选择,使模型在大量特征中只关注那些非零值的特征;
为什么可以产生稀疏解呢?
可以参见下面这幅图:有损失函数的等值线以及L1正则项的连线;交点在坐标轴上,会使很多权值为0,因此解具有稀疏性;

L2正则化:
Ridge回归;防止模型过拟合;


对率回归(逻辑回归):
本质是线性回归,通过sigmoid函数映射到0-1区间,从而分类;多元分类需要将sigmoid换成softmax函数; (softmax交叉熵损失推导 https://www.jianshu.com/p/c02a1fbffad6)
·sigmoid函数:
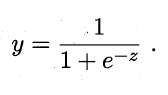
(1)可将(-∞,+∞)映射到(0,1)之间,作为概率;(2)从曲线可以发现,在负值区域,y小于二分之一;正值区域,y大于二分之一;可将1/2作为决策边界;转换为标签就是自变量小于0的时候,即可判定为标签为0;(3)该函数的求导函数很容易y^'=y·(1-y)
·损失函数:
对数损失函数(交叉熵);因为概率连乘通过log可以转化为连加方式,更便于计算;
优点:
可解释性高,工业中可控度高;
·与线性回归相比较:
1.线性回归通过sigmod函数映射到0-1区间,设置预测值大于0判为正例、小于0判为负例,以此来做分类。
2.线性回归要求自变量和因变量为线性关系;LR不要求呈线性关系;
·与SVM关系:
---相同点:
1.处理分类问题;
2.均可增加不同的正则化项;
3.均是监督学习判别模型;
4.目标都是找一个分类超平面;
---区别:
1.LR是参数模型;SVM是非参数模型;
2.目标函数角度:LR使用对数损失(交叉熵);SVM使用hinge loss;目的是增加对分类影响大的数据点的权重,反之减少;
3.LR更简单;但是SVM在转化为对偶问题后,分类只需要计算和少数几个支持向量的距离,也可以简化模型和计算;
4.SVM只考虑支持向量,即和分类最相关的少数点学习分类器;LR中每一个数据点对分类平面都有影响,通过非线性映射减小离分类平面较远的点的权重,提升了与分类相关的数据点的权重;
5.LR不仅输出标记,还输出概率;SVM是非概率的,只输出标记;
6.LR处理经验风险最小化; SVM是结构风险最小化(因为自带L2正则项)
·与朴素贝叶斯关系:
朴素贝叶斯是生成模型;
---相同点:
1.监督学习分类问题;
---不同点:
1.LR是判别模型求的是后验概率p(y|x);朴素贝叶斯生成模型求的是p(x,y);
2.朴素贝叶斯假设了条件概率是条件独立的,如果数据不符合这个情况,朴素贝叶斯的分类表现没有逻辑回归好;
Refer:
LR和线性回归模型 https://blog.csdn.net/jiaoyangwm/article/details/81139362
线性回归L1、L2正则化 https://blog.csdn.net/jinping_shi/article/details/52433975















 1771
1771











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









