






论文:Optimal Repair Layering for Erasure-Coded Data Centers: From Theory to Practice
论文提供了源码:http://adslab.cse.cuhk.edu.hk/software/doubler
摘要:
分层数据中心的修复性能往往受到跨服务器网络传输的阻碍。 最近的理论结果表明,通过修复和改进分层,可以最大限度地减少跨服务器的网络传输,其思想是将修复操作划分为在内机架层和跨机架层。 本文提出了一种修复分层框架DRC。
(并且提供了源代码:http://adslab.cse.cuhk.edu.hk/software/doubler)
介绍:
随着时代的发展现在数据越来越大,现代数据中心越来越多的采用纠删码来保护冗余度显著低的数据存储,同时仍然保持与传统复制相同的容错性。但纠删码的却有高修复成本的缺点。因为纠删码在修复过程中,必须从其他节点检索多个可用块以进行重建。 这导致大量的修理流量,定义为为恢复而传输的数据量。 后来又出现了再生码,再生码是一类特殊的纠删码码,经证明最小化了修复流量。但是再生码在处理数据中心的分层性质方面的效果仍然有限。 数据传输虽然在一个服务器内有全双带宽,但在多个服务器机架交叉的情况下,带宽受到了很大的限制。
1. 问题的产生:
典型的超额认购比率从5:1到20:1不等(即在最坏情况下,每个节点的可用交叉服务器机架带宽仅为内部机架带宽的到1/20);现有的数据中心也往往采用平面布局的方式搭建服务器群,这样虽然可以降低存储所用空间,但也大大增加了每次恢复的传输成本,即使使用了再生码。
为了解决以上问题,本文提出的DRC模型旨在最小化分层数据中心的交叉跟踪修复流量。 提出一种称为修复分层的概念,它将修复操作分解为内机架层和跨机架层。
2. 框架大体运作流程:
DRC选择分层块放置,在每个机架多放置一个切片的多个块,以尽量减少交叉机架修复流量,而牺牲机架级容错性能。第一步先在一个服务器机架内只用该服务器内的可用快就行部分恢复,第二步再传输到错误结点处,将所有部分恢复块整合。
3. 本文在应用实验的角度的贡献:
(1) 提供了数值分析 ,与最先进的再生代相比,表明明显的降低了恢复流量。 还提供了可靠性分析,以研究恢复流量与降低容错性能之间的权衡。
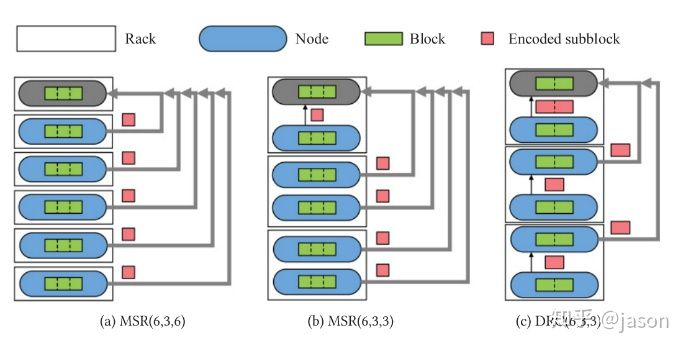
(2) 提出了两种DRC的结构。
(3) 提供了在HDFS环境下的DRC和现有再生码的API。
(4) 使用DRC对不同的纠删码进行了测试实验。
DRC概述:
1.动机:现有的数据中心有两类故障:独立和相关联的节点故障。在数据中心,关联故主要,所以本文不采用平块放置,而是选择分层块放置,并将多个块放置在同一机架中;牺牲单个机架的容错性能,以尽量减少交叉机架修复流量。
2. DRC结构:
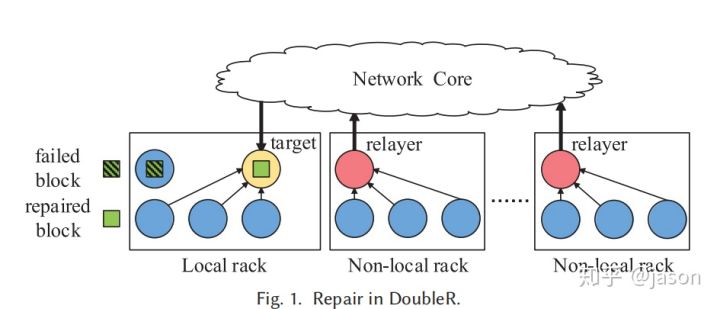
过程:每个机架都包含多个存储节点,同一机架内的多个节点通过机架顶部交换机连接,而多个机架通过称为网络核心的交换机抽象连接。layer应该是本地存储用于修复的可用块以保存内部机架网络传输的节点之一,每个机架内尽可能多的修复失败的数据,然后通过relayer层和中心网络到达预定target节点进行重组。
3. DRC与纠删码,再生码的比较:
首先推导定义了RS,MRS,DRC的最小交叉恢复流量的定义:
RS:

MRS:
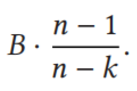
DRC:
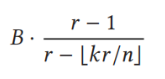
这里,n是node总数,k是指每个block被均匀分为k份,r是指需要编码的block的总数,B是每个block被k均分后每份的大小。
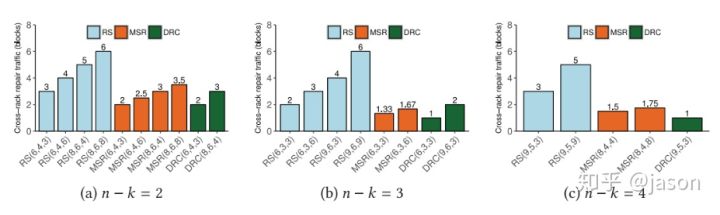
通过举例和具体的数值分析:
DRC的存储冗余(n/k) 和 交叉恢复流量 性能均强于现有纠删码和再生码。
4. 对于稳定性:
利用了标准的默尔夫模型进行评估。
实际部署环境与DRC模型:
两个family的DRC:
1. 将RS代码与干扰对齐集成在一起,这使得减少 内部机架修理流量和平衡跨多个机架的交叉机架修复流量成为可能。
2. 它允许非本地机架中的节点只从其本地存储中读取子块并将其发送到重新层,而不执行编码操作。 它遵循通过传输修复的想法,并有助于减少磁盘I/O。
3. 在HDFS环境具体部署:
HDFS将数据组织为固定大小的数据块,每个数据块都是读/写操作的基本单元,并且每个都具有较大的大小(例如64MIB),以减轻随机访问开销。 每个数据块包括用于管理文件操作的单个名称节点和用于存储数据的多个数据节点。
DRC具体实验细节:略。
实验过程:
评估以下两个问题:
(1)在真实的网络环境中,DRC能否实现理论性能(前面中的数值结果)?
(2)最大限度地减少跨架修理流量是否对提高整体修理性能起着关键作用?
- 实验设备:11台电脑(这实验室真tnd有钱),10台安装HDFS。10台服务器中,1台运行NameNode 和 RaidNode,其它n台运行一个(n, k,r)规模的DataNode。n最多为9。
这里的实验中,为了模拟分层数据中心,分配了一台称为网关的专用机器来模拟图1中的网络核心。具体来说,我们将n个数据节点划分为到r个逻辑机架。 如果逻辑机架中的一台机器希望在不同的逻辑机架中将数据发送到另一台机器,则其交叉机架流量将首先重定向到网关,然后网关将流量中继到目标机器;这样可以定向为每个linux服务器分配路由表(个人理解:这样可以监听每个服务器具体传输流量的具体数值,以便后续实验结果对比)
2. 在我们测量节点点恢复和错误读取性能之前,首先进行微基准评估;
微基准评估:我们首先通过微基准评估表明,跨机转移数据确实是整个修复性能中最主要的因素。然后后续进行验证。
我们使用默认参数的,DRC(9,6,3)和DRC(9,5,3)作为family1和family2的代表。 我们提供了单个故障块的修复时间的细目;请注意,DRC(9,6,3)和DRC(9,5,3)的默认块大小分别为63MiB和64MiB。 我们将修复操作分解为不同的步骤,包括通过网络发送数据的发送时间 和在不同的API中执行本地计算的时间。 我们导出了每个步骤的预期运行时间如下:
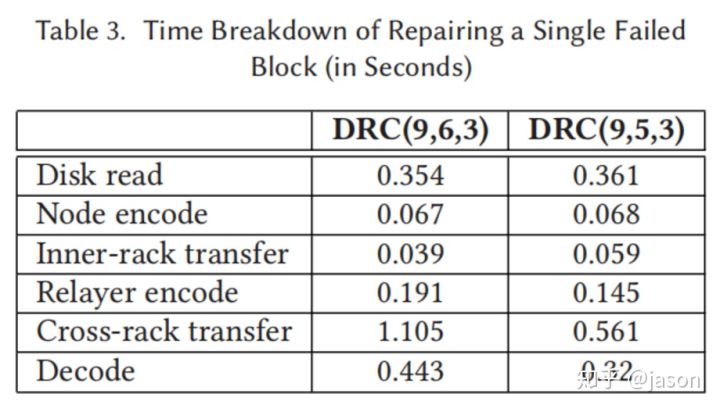
表格研究表明,在修复操作中,交叉机架数据传输时间是最主要的因素。
3. 在数据恢复性能的实验评估:
我们首先评估DRC在修复单个错误节点的多个错误块时的节点恢复性能。 具体来说,我们在数据节点上写入了20个块。 为了模拟节点故障,我们随机选择一个数据节点,擦除它的所有20个块,并运行DRC来修复所有擦除的块。 我们使用默认参数,并将网关带宽从200Mb/s依次更改为2Gb/s。 对于每种纠删码,我们测量其恢复吞吐量,定义为:被修复的块的总大小 除以整个节点恢复操作的总时间。(具体实验结果图表看论文)最终表明,只有当交叉机架传输是数据中心的性能瓶颈时,我们才能声称DRC与其它纠删码相比具有显著优势。
4. 在错误读取性能的实验评估:
当文件系统客户端访问单个不可用块时,我们来评估降级的读取性能。 具体来说,我们随机选择一个数据块来擦除,并让文件系统客户端通过降级的读取访问擦除的块。 与数据恢复实验一样,我们再次使用默认参数,并将网关带宽从200Mb/s依次更改为2Gb/s。我们将错误读取时间定义为: 定义为从发出读取请求到 在文件系统客户端错误块完全被重建 的时间。(具体实验结果图表看论文)最终表明,DRC通过最小化交叉跟踪修复流量来显示错误读取的性能增益。
5. 论文同样还对 块大小的影响做了评估,这里就不具体说明了。
结论:
本文提出了分层修复的框架,设计并实现了两个实用的DRC结构。实验表明,DRC在节点恢复和降低读取时间的性能上 超过现有的再生码。















 1073
1073











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









