







运行环境:Spark1.4集群
语言:Scala
一、简单实例演示
1、文本内容:

2、操作
Step1. 读取hdfs 上文件:
val wcrdd1=sc.textFile("hdfs://master:9000/wordcount/words.txt").cache
Step2. flatMap 操作:将文本以空格形式切割
val wcrdd2=wcrdd1.flatMap(_.split(" "))
Step3. Map操作:将分割出的元素转换成kv形式
val wcrdd3=wcrdd2.map(word =>(word,1))
Step4. reduceByKey操作:将kv形式的数组进行分组并累加统计
val wcrdd4=wcrdd3.reduceByKey((a,b)=>a+b)
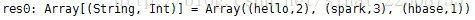
Step5. 将单词出现频率进行降序排序
val wcrdd5=wcrdd4.map(x=>(x._2,x._1)).sortByKey(false).map(y=>(y._2,y._1)).collect
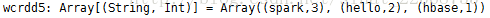
Last Step:完整代码并上传hdfs
val wcrdd=sc.textFile("hdfs://master:9000/wordcount/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _).map(x=>(x._2,x._1)).sortByKey(false).map(x=>(x._2,x._1)).saveAsTextFile("hdfs://master:9000/wordcount/wordssort.txt")


二、相关说明
1、hdfs常用命令
https://segmentfault.com/a/1190000002672666
2、RDD操作
a. Map 操作
1对1映射,针对RDD的每个元素经过指定函数转成新的元素,进而得到新的RDD
b. MapValue 操作
key-values的value经过函数计算与之前的key值组成新的key-value
c. flatMap 操作
1对多映射,可以将集合A中的元素与B中的元素进行一一对应生成新的array
d. flatMapvalue 操作
类是Map Value
e. groupByKey 操作
按照key值进行分组
f. sortByKey 操作
按Key值进行排序,默认正排序,false逆向排序
g. reduceByKey 操作
先执行groupByKey操作,在对组内的Value值进行计算
h. join 操作
默认内连接,针对Key值相同建立连个RDD的内链接
i. filter 操作
对RDD进行过滤操作
。
。
。















 436
436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









