







1.制作python环境
1)可以使用anacoda方式创建虚拟环境,或者自己利用自己安装好得python环境进行打包。打包之前使用pip安装好自己需要使用得python 模块。
2)打包
进入到python 得安装目录如下图是到bin 级别目录下,然后使用zip进行打包
zip -r py3.zip ./*
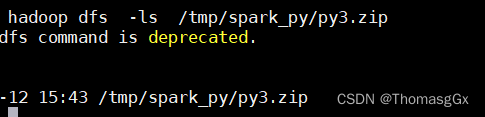
3)打包好后将打好得zip 包上传至hdfs(目录自己指定,最好放在自己的用用户目录防止被删除)
hadoop dfs -put py3.zip /tmp/spark_py/
2.提交说明
2.1提交参数说明:
archives hdfs:/tmp/spark_py/py3.zip#py3 这个是指定hdfs打包的python环境路径,这里注意 #py3 这个必须要有这个是表示解压后的路径,一般应该是解压在用户目录下,名称自己定义。
spark.pyspark.python=./py3/bin/python3.7 这个参数是指定driver与executor端python使用的路径(cluster模式下driver与executor端路径相同),这里的路径前缀是上面#后面定义的名称(注意这里是相对路径)。
spark.pyspark.driver.python=/opt/anaconda3/envs/py3/bin/python3.7 这个是指定driver端python路径
< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1091
1091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









