







本文数据预处理主要步骤:
(1)删除和估算缺失值 (removing and imputing missing values)
(2)获取分类数据 (Getting categorical data into shape for machine learning)
(3)为模型构建选择相关特征 (Selecting relevant features for the module construction)
【创建CSV数据集】
- #build a csv dataset
- import numpy as np
- import pandas as pd
- from io import StringIO
- import sys
- #数据不要打空格,IO流会读入空格
- csv_data = \
- '''''A,B,C,D
- 1.0,2.0,3.0,4.0
- 5.0,6.0,,8.0
- 10.0,11.0,12.0,
- '''
- df = pd.read_csv(StringIO(csv_data))
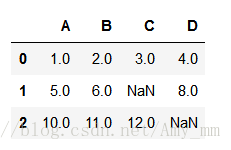
如图,有两个空值~
【统计空值情况】
- #using isnull() function to check NaN value
- df.isnull().sum()
【访问数组元素】
在放入sklearn的预估器之前,可以通过value属性访问numpy数组的底层数据

【消除缺失值 dropna() 函数】
一个最简单的处理缺失值的方法就是直接删掉相关的特征值(一列数据)或者相关的样本(一行数据)。
利用dropna()函数实现。
dropna( axis = 0 /1 )参数axis表示轴选择,axis=0 代表行,axis=1 代表列。
- df.dropna(axis = 1)

- df.dropna(axis = 0)

dropna( how = all) how参数选择删除行列数据(any / all)
df.dropna(how = 'all')
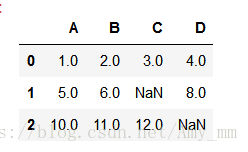
dropna(thresh = int) 删除值少于int个数的值
- df.dropna(thresh = 4)

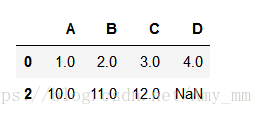
dropna( subset = [' ']) 删除指定列中有空值的一行数据(整个样本)
- df.dropna(subset = ['C'])
删除C列中有空值的那一行数据
虽然直接删除很是简单啦~但是天下没有免费的午餐,直接删除会带来很多弊端。比如样本值删除太多导致不能进行可靠预测;或者特征值删除太多(列数据),可能失去很多有价值的信息。
所以下面介绍一个更为通用的缺失值处理技巧——插值技术。我们可以根据样本集中的其他数据,运用不同的插值技术,来估计 样本的缺失值。
【插值】interpolation techniques
【imputing missing values】
比较常用的一种估值是平均值估计(mean imputation)。可以直接使用sklearn库中的imputer类实现。
- <span style="font-size:16px;">class sklearn.preprocessing .Imputer</span>
- <span style="font-size:16px;">(missing_values = 'NaN', strategy = 'mean', axis = 0, verbose = 0, copy = True)</span>
参考:http://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.Imputer.html
参数说明:
missing_values : int或者'NaN',默认NaN(string类型)
strategy:默认mean。平均值填补。
可选项: mean(平均值)
median(中位数)
most_frequent(众数)
axis: 指定轴向。axis= 0,列向(默认);axis= 1,行向。
verbose : int 默认值为0
copy:默认True,创建数据集的副本。
False:在任何合适的地方都可能进行插值。
以下四种情况,即使copy设为False,也会进行创建副本:
1. X不是浮点型数组
2.X是稀疏矩阵,且missing_values= 0
3.axis=0,X被编码为CSR矩阵(Compressed Sparse Row 行压缩)
4.axis=1,X被编码为CSC矩阵(Copressed Sparse Column 列压缩)

- #mean imputation
- #axis = 0,表示列向,采用每一列的平均值填补空值
- from sklearn.preprocessing import Imputer
- imr = Imputer(missing_values = 'NaN', strategy = 'mean', axis = 0 )
- imr = imr.fit(df.values)
- imputed_data = imr.transform(df.values)
- imputed_data
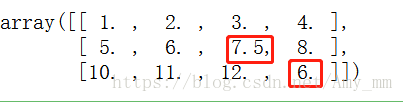
【处理分类数据】
handling categorical data
分类数据一般分为nominal(名词性,不可排序)和ordinal(可排序数据)
【创建分类数据集】
- #create categorical dataset
- import pandas as pd
- df = pd.DataFrame([
- ['green', 'M', 10.1, 'class1'],
- ['red', 'L', 13.5, 'class2'],
- ['blue', 'XL', 15.3, 'class1']
- ])
- df.columns = ['color', 'size', 'price', 'classlabel']
- df
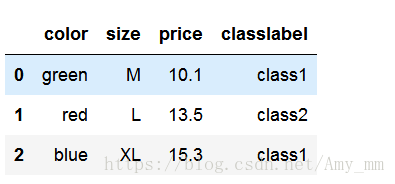
nominal data : color
ordinal data : size
numerical data : price
【映射可排序特征】
为确保学习算法能够正确识别可排序特征值,需要将分类数据转换为数值型数据。
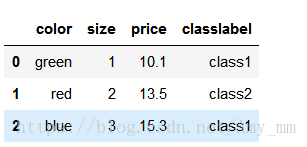
- #converting categorical string values into integers
- size_mapping = {
- 'XL': 3,
- 'L' : 2,
- 'M' : 1}
- df['size'] = df['size'].map(size_mapping)
- df
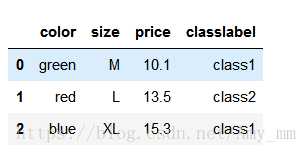
也可以反向映射回分类值
- #reverse mapping
- inv_size_mapping = {
- v : k for k ,v in size_mapping.items()
- }
- df['size'] = df['size'].map(inv_size_mapping)
- df
【编码分类标签】
Encoding class label
- import numpy as n
- class_mapping = {label : idx for idx, label in enumerate(np.unique(df['classlabel']))}
- class_mapping
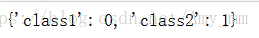
利用上述class_mapping将classlabel转换为integer
- df['classlabel'] = df['classlabel'].map(class_mapping)
- df
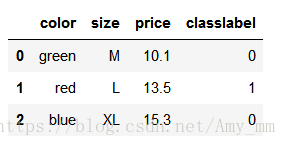
同样可以转换回去
- inv_class_mapping = {v : k for k, v in class_mapping.items()}
- df['classlabel'] = df['classlabel'].map(inv_class_mapping)
- df
也可以直接调用sklearn库中的LabelEncoder 类进行类标签转换
- #直接采用sklearn库中的LabelEncoder进行编码
- from sklearn.preprocessing import LabelEncoder
- class_le = LabelEncoder()
- y = class_le.fit_transform(df['classlabel'].values)
- y
利用inverse_transform转换回去
- class_le.inverse_transform(y)
【one-hot encoding for nominal features】
get_doommies()
使用one-hot编码时,容易引起共线性问题,在使用其他算法时容易出现bug,例如矩阵的求逆。
为避免这种问题,降低变量间的相关性,可以简单的删除one-hot编码数组中特征值的第一列,这样也不会丢失重要信息。
例如删除color_blue这一列,如果color_red=0,color_green=0,则可以判断color_blue=1.
- pd.get_dummies(df[['size','color','price']],drop_first = True)
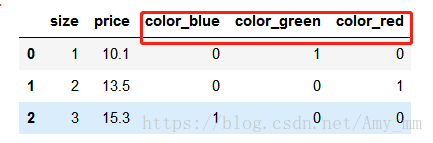
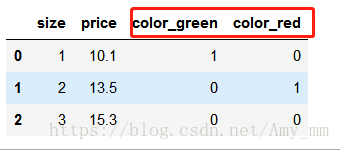
删除color_blue这一列,令drop_firt=True即可
- #为避免共线性问题,降低变量间的相关性,删除one-hot数组中特征值的第一列
- pd.get_dummies(df[['size','color','price']],drop_first = True)
【数据特征选择】
利用wine dataset 学习特征选择,以及L1,L2Z正则化数据。
【读数据】
- # read wine dataset
- df_wine = pd.read_csv("G:\Machine Learning\python machine learning\python machine learning code\code\ch04\wine.data")
- df_wine.columns = ['Class label', 'Alcohol', 'Malic acid', 'Ash',
- 'Alcalinity of ash', 'Magnesium', 'Total phenols',
- 'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins',
- 'Color intensity', 'Hue', 'OD280/OD315 of diluted wines',
- 'Proline']
- print('Class labels', np.unique(df_wine['Class label']))
- df_wine.head()
【划分数据 ——训练集和测试集】
- #seperate train and test data
- from sklearn.model_selection import train_test_split
- X,y = df_wine.iloc[:,1:].values,df_wine.iloc[:,0].values
- X_train, X_test, y_train, y_test = \
- train_test_split(X,
- y,
- test_size = 0.3,
- random_state = 0,
- stratify = y)
特征缩放在数据预处理中是及其重要的一步,除了决策树和随机森林中不需要特征缩放,其余大部分学习和优化算法都需要特征缩放,保证所有特征在同一范围内。
两个进行特征缩放的方法:normalization(规范化) and standardization(标准化)
对比两种放缩的实例数据:

Normalization:将数据重新规范到范围[0,1]之间,是min-max缩放中的一种。
计算公式:
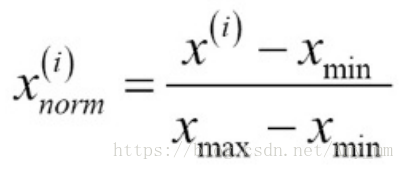
sklearn.preprocessing.MinMaxScaler 实现
- #sklearn normalization
- from sklearn.preprocessing import MinMaxScaler
- mms = MinMaxScaler()
- X_train_norm = mms.fit_transform(X_train)
- X_test_norm = mms.transform(X_test)
Standardization:将数据标准化为均值为0 方差为1
计算公式:

- sklearn standardization
- from sklearn.preprocessing import StandardScaler
- stdsc = StandardScaler()
- X_train_std = stdsc.fit_transform(X_train)
- X_test_std = stdsc.transform(X_test)
只需要在训练集上使用fit函数,然后使用这些参数去标准化测试集或者其他新的数据集。这样就可以使得所有标准化后的数据在同一scale上,是课相互比较的数据集。
【避免过拟合的方法】
(1)收集尽可能多的训练数据
(2)通过正则化引入对于模型负责度的惩罚系数
(3)选择参数较少的简单模型
(4)降级数据维度
方法(1)一般不太可行
本文讲述通过特征选择实现的正则化和降低纬度的方法使得模型简单化。
【L1 L2正则化】
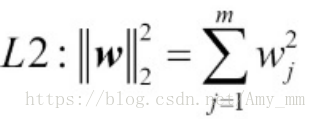
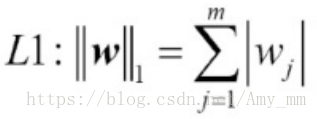
L1正则化通常会生成稀疏特征向量,大部分特征值为0。
如果数据集是高维度且有很多不相关的特征值,尤其是当不相关的维度多于样本时,L1是很好的选择。
sklearn 实现L1 L2
- # sklearn实现L1
- from sklearn.linear_model import LogisticRegression
- lr = LogisticRegression(penalty = 'l1', C = 1.0)
- lr.fit(X_train_std,y_train)
- print('Training accuracy:', lr.score(X_train_std, y_train))
从特征全集开始,每次从特征集中删除一个特征x,使得删除特征x后评价函数值达到最优。
算法:定义一个判别函数J,目的是是J最小化
(1)初始化 k=d,d是数据集的维数

(2)选择使得判别函数最大的特征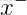
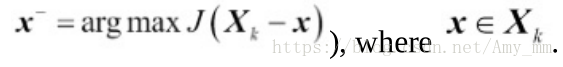
(3)从特征集中删除特征
(4)如果k达到了期望值,结束;否则返回(2)
- <span style="font-weight:normal;">#SBS select features
- from sklearn.base import clone
- from itertools import combinations
- import numpy as np
- from sklearn.metrics import accuracy_score
- from sklearn.model_selection import train_test_split
- class SBS():
- def __init__(self,
- estimator, #评估器 比如LR,KNN
- k_features, #想要的特征个数
- scoring = accuracy_score,#对模型的预测评分
- test_size=0.25,
- random_state=1):
- self.scoring = scoring
- self.estimator = clone(estimator)
- self.k_features = k_features
- self.test_size = test_size
- self.random_state = random_state
- def fit(self, X, y):
- #seperete train data and test data
- X_train, X_test, y_train, y_test = train_test_split(X, y,
- test_size = self.test_size,
- random_state = self.random_state)
- # dimension
- dim = X_train.shape[1]
- self.indices_ = tuple(range(dim))
- self.subsets_ = [self.indices_] #特征子集
- score = self._calc_score(X_train, y_train, X_test, y_test, self.indices_)
- self.scores_ = [score]
- while dim > self.k_features:
- scores = [] #分数
- subsets = [] #子集
- for p in combinations(self.indices_, r = dim - 1):
- score = self._calc_score(X_train,
- y_train,
- X_test,
- y_test,
- p)
- print(p, score)
- scores.append(score)
- subsets.append(p)
- best = np.argmax(scores)
- self.indices_ = subsets[best]
- self.subsets_.append(self.indices_)
- dim -= 1
- self.scores_.append(scores[best])
- self.k_score_ = self.scores_[-1]
- return self
- def transform(self, X):
- return X[:, self.indices_]
- def _calc_score(self, X_train, y_train, X_test, y_test, indices):
- self.estimator.fit(X_train[:, indices], y_train)
- y_pred = self.estimator.predict(X_test[:, indices])
- score = self.scoring(y_test, y_pred)
- return score
- </span>
- <span style="font-weight:normal;">import matplotlib.pyplot as plt
- from sklearn.neighbors import KNeighborsClassifier
- knn = KNeighborsClassifier(n_neighbors=5)
- # selecting features
- sbs = SBS(knn, k_features=1)
- sbs.fit(X_train_std, y_train)
- # plotting performance of feature subsets
- k_feat = [len(k) for k in sbs.subsets_]
- plt.plot(k_feat, sbs.scores_, marker='o')
- plt.ylim([0.7, 1.02])
- plt.ylabel('Accuracy')
- plt.xlabel('Number of features')
- plt.grid()
- plt.tight_layout()
- # plt.savefig('images/04_08.png', dpi=300)
- plt.show()</span>

【随机森林评估特征值的重要性】
- <span style="font-weight:normal;">#随机森林选择特征值
- from sklearn.ensemble import RandomForestClassifier
- feat_labels = df_wine.columns[1:]
- forest = RandomForestClassifier(n_estimators=500, random_state=1)
- forest.fit(X_train, y_train)
- #
- importances = forest.feature_importances_
- indices = np.argsort(importances)[::-1]
- for f in range(X_train.shape[1]):
- print("%2d) %-*s %f" % (f + 1, 30,
- feat_labels[indices[f]],
- importances[indices[f]]))
- plt.title('Feature Importance')
- plt.bar(range(X_train.shape[1]),
- importances[indices],
- align='center')
- plt.xticks(range(X_train.shape[1]),
- feat_labels[indices], rotation=90)
- plt.xlim([-1, X_train.shape[1]])
- plt.tight_layout()
- plt.show()
- </span>

【SelectFromModel 实现特征提取】
- <span style="font-weight:normal;">#SelectFromModel
- </span>from sklearn.feature_selection import SelectFromModel<span style="font-weight:normal;">
- sfm = SelectFromModel(forest, threshold = 0.1, prefit = True) #threshold阈值
- X_selected = sfm.transform(X_train)
- print('Number of samples that meet this criterion:',X_selected.shape[0]</span>
- <span style="font-weight:normal;">for f in range(X_selected.shape[1]):
- print("%2d) %-*s %f" % (f + 1, 30, #%-*s ,其中*表示输出string间隔
- feat_labels[indices[f]],
- importances[indices[f]]))</span>















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









