







理解表:数据库之 表与表之间的关系
神器推荐:navicat
安装教程原网址http://www.cnblogs.com/iscodercn/p/5488633.html
section A
- 数据库系统解决的问题:持久化存储,优化读写,保证数据的有效性
- 先设计表结构
E(表)-R 模型(实体vs关系) 三范式
- 第一范式(1NF):列不可拆分 --姓名属性不可拆为姓和名
- 第二范式(2NF):唯一标识 --id
- 第三范式(3NF):引用主键 --id是基于主键的
为了更加准确的存储数据,保证数据的正确有效,可以在创建表的时候,为表添加一些强制性的验证,包括数据字段的类型、约束
1、字段类型 --数据有效性
- 在mysql中包含的数据类型很多,这里主要列出来常用的几种
- 数字:int,decimal
- 字符串:char(固定文本,不够补空格:电话),varchar(可变有限文本:姓名), text(大文本)
- 日期:datetime(到秒),date(到天)
- 布尔:bit(3) --用0,1表示性别,开销小
- 逻辑删除:0,1 重要数据
2、约束 --限制条件
- 主键primary key --找的速度快,表只能有一个,作为唯一id使用???自动增长
- 非空not null --姓名不能为空
- 惟一unique --不能重复,身份证
- 默认default --默认值
- 外键foreign key --
A。图形界面(phpMyAdmin , navicat)
ip地址+。。。root root
Navicat Premium 是一套多连接数据库开发工具,让你在单一应用程序中同时连接多达六种数据库:MySQL、 MariaDB、SQL Server、SQLite、Oracle 和 PostgreSQL,可一次快速方便地访问所有数据库。
数据库设计预留栏位,便于后期修改
mysql目录:
bin目录 存储可执行的文件 data目录 储存数据文件 docs目录 文档 include目录 存储包含的头文件 lib目录 存储库文件 share目录 错误消息和字符集cmd命令 启动/关闭服务 启动 net start mysql 退出: exit 或 quit 或 \q 关闭 net stop mysql win其他系统服务同样适用于以上命令, ————cmd控制启动与停止MySQL服务,也可在windows管理服务里面启动
cls清空 MySQL登陆:mysql -v;(版本信息);mysql-uroot -p -P3306 -h(服务器名称提供)127.0.0.1(本地回环地址),后面两个如果没变可不加。回车后输入密码。 MySQL退出:mysql>exit;quit;\q 上下箭头进行翻阅B。脚本操作
进入mysql:mysql -uroot -proot mysql 密码: rootmysql -uroot -p 密码:root // u表示用户名 远程链接: mysql -hip地址 -uroot -p //地址换成ip数字就可以了
-h后面写要连接的主机ip地址
- -u后面写连接的用户名
- -p回车后写密码
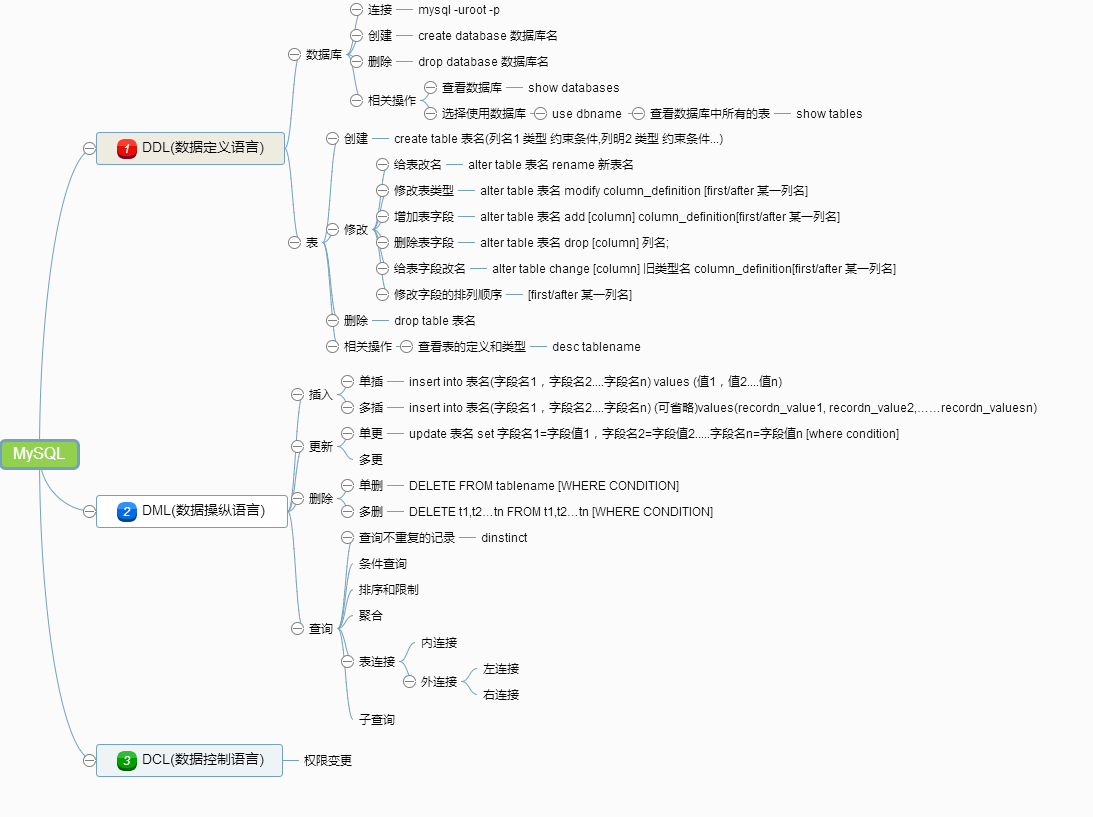
数据库操作:
create database 数据库名 charset=utf8;
drop database 数据库名;
use 数据库名; show databases; select database();select version() 显示当前服务器版本
select now() 显示当前日期时间
select user() 显示当前用户- 创建数据库
- 删除数据库
- 切换数据库
- 查看所有数据库
- 查看当前使用的数据库
-
表操作 --最好的是开始就设计好表
show tables;alter table 表名 add|change|drop 列名 类型; 如: alter table students add birthday datetime;drop table 表名;desc 表名;rename table 原表名 to 新表名;show create table 表名;- 查看当前数据库中所有表
- 创建表
-
auto_increment表示自动增长
create table 表名(列及类型); 如: create table students( id int auto_increment primary key, sname varchar(10) not null ); -
修改表 列的名字不能改,只能修改类型,写错就jj了
- 删除表 物理删除,谨慎操作
- 查看表结构,内容
- 更改表名称
- 查看表的创建语句
- 数据库的操作主要包括:
- 数据库的操作,包括创建、删除
- 表的操作,包括创建、修改、删除
- 数据的操作,包括增加、修改、删除、查询,简称crud【增加(Create)、读取查询(Retrieve)、更新(Update)和删除(Delete)】
- 一般对于重要数据,会设置一个isDelete的列,类型为bit,表示逻辑删除(保护数据)
3.数据操作
- 查询
select * from 表名
- 增加
全列插入:insert into 表名 values(...) //values(0,'李春',1,'1990-1-1',0)与表结构一一对应 缺省插入:insert into 表名(列1,...) values(值1,...) //(name,gender) values('黄蓉',0) 同时插入多条数据:insert into 表名 values(...),(...)...; 或insert into 表名(列1,...) values(值1,...),(值1,...)...; //(name) ('杨哥') ,('郭襄')
- 主键列是自动增长,但是在全列插入时需要占位,通常使用0,插入成功后以实际数据为准
- 修改
update 表名 set 列1=值1,... where 条件
- 删除
delete from 表名 where 条件
- 逻辑删除,本质就是修改操作update
alter table students add isdelete bit default 0; 如果需要删除则 update students isdelete=1 where ...;数据备份
- 进入超级管理员
sudo -s
- 进入mysql库目录
cd /var/lib/mysql
- 运行mysqldump命令
mysqldump –uroot –p 数据库名 > ~/Desktop/备份文件.sql; 按提示输入mysql的密码 /密码别输错啊,巨坑数据恢复 --进入备份文件夹
连接mysqk,创建数据库
退出连接,执行如下命令
mysql -uroot –p 数据库名 < ~/Desktop/备份文件.sql 根据提示输入mysql密码section B:查询(90%)
- 查询的基本语法
select * from 表名;
- from关键字后面写表名,表示数据来源于是这张表
- select后面写表中的列名,如果是*表示在结果中显示表中所有列
- 在select后面的列名部分,可以使用as为列起别名,这个别名出现在结果集中
- 如果要查询多个列,之间使用逗号分隔
消除重复行
- 在select后面列前使用distinct可以消除重复的行
这行属性和其他行比select distinct gender from students;
条件
- 使用where子句对表中的数据筛选,结果为true的行会出现在结果集中
- 语法如下:
select * from 表名 where 条件;
- 查询编号大于3的学生
select * from students where id>3;
- 查询没被删除的学生
select * from students where isdelete=0;逻辑运算符
- and
- or
- not
- 查询编号大于3的女同学
select * from students where id>3 and gender=0;模糊查询
- like
- %表示任意多个任意字符
- _表示一个任意字符
- 查询姓黄的学生
select * from students where sname like '黄%';范围查询
- in表示在一个非连续的范围内
- 查询编号是1或3或8的学生
select * from students where id in(1,3,8);
- between ... and ...表示在一个连续的范围内
- 查询学生是3至8的学生
select * from students where id between 3 and 8;空判断
- 注意:null与' '是不同的 /一个不占内存,一个占位置的空字符串
- 判空is null
- 查询没有填写地址的学生
select * from students where hometown is null;
- 判非空is not null
- 查询填写了地址的学生
select * from students where hometown is not null;section C:
聚合 --为了统计
- 为了快速得到统计数据,提供了5个聚合函数
- count(*)表示计算总行数,括号中写星与列名,结果是相同的
- 查询学生总数
select count(*) from students;
- max(列)表示求此列的最大值
- 查询女生的编号最大值
select max(id) from students where gender=0;
- min(列)表示求此列的最小值
- 查询未删除的学生最小编号
select min(id) from students where isdelete=0;
- sum(列)表示求此列的和
- 查询男生的编号之后
select sum(id) from students where gender=1;
- avg(列)表示求此列的平均值
- 查询未删除女生的编号平均值
select avg(id) from students where isdelete=0 and gender=0;分组
- 按照字段分组,表示此字段相同的数据会被放到一个组中
- 分组后,只能查询出相同的数据列,对于有差异的数据列无法出现在结果集中
- 可以对分组后的数据进行统计,做聚合运算
- 语法:
select 列1,列2,聚合... from 表名 group by 列1,列2,列3...
- 查询男女生总数
select gender as 性别,count(*) from students group by gender;
- 查询各城市人数
select hometown as 家乡,count(*) from students group by hometown;分组后的数据筛选
- 语法:
select 列1,列2,聚合... from 表名 group by 列1,列2,列3... having 列1,...聚合...
- having后面的条件运算符与where的相同
- 查询男生总人数
方案一 select count(*) from students where gender=1;排序
- 为了方便查看数据,可以对数据进行排序
- 语法:
select * from 表名 order by 列1 asc|desc,列2 asc|desc,...
- 将行数据按照列1进行排序,如果某些行列1的值相同时,则按照列2排序,以此类推
- 默认按照列值从小到大排列
- asc从小到大排列,即升序
- desc从大到小排序,即降序
- 查询未删除男生学生信息,按学号降序
select * from students where gender=1 and isdelete=0 order by id desc;
- 查询未删除科目信息,按名称升序
select * from subject where isdelete=0 order by stitle;分页
- 当数据量过大时,在一页中查看数据是一件非常麻烦的事情
- 语法
select * from 表名 limit start,count
- 从start开始,获取count条数据
- start索引从0开始
总结
- 完整的select语句
select distinct * from 表名 where .... group by ... having ... order by ... limit star,count
- 执行顺序为:
- from 表名
- where ....
- group by ...
- select distinct *
- having ...
- order by ...
- limit star,count
- 实际使用中,只是语句中某些部分的组合,而不是全部
连接查询
- 连接查询分类如下:
- 表A inner join 表B:表A与表B匹配的行会出现在结果中
- 表A left join 表B:表A与表B匹配的行会出现在结果中,外加表A中独有的数据,未对应的数据使用null填充
- 表A right join 表B:表A与表B匹配的行会出现在结果中,外加表B中独有的数据,未对应的数据使用null填充
- 在查询或条件中推荐使用“表名.列名”的语法
- 如果多个表中列名不重复可以省略“表名.”部分
- 如果表的名称太长,可以在表名后面使用' as 简写名'或' 简写名',为表起个临时的简写名称
section D: python操作Mysql数据库 非常好的课程
Python DB API (统一接口规范)的 connection(数据库连接对象) 和 cursor(数据库交互对象)以及 excptions(数据库异常类)

连接:
import pymysql conn = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="", db="imook", charset="utf8" ) cur = conn.cursor() print(conn) print(cur) cur.close() #记得都要关闭 conn.close()在connection上建立Cursor来执行查询和获取结果如果只是fetchall的话,我一般直接在cursor.execute(sql)之后直接进行遍历而不执行fetchall,效果是一样的 for row in cursor: print row回滚实物出错可以复原,银行转账 如果要让数据表支持事务,则需设置表的ENGINE = INNODBinsert,update,delete,注意加conn.commit()才能更新数据库
mysql存储:
存储引擎:MySQL可以将数据以不同的技术存储在文件(内存)中,这种技术就称为存储引擎。每一种存储引擎使用不同的存储机制,索引技巧,锁定水平,最终提供广泛且不同的功能。一共有以下几种存储引擎:MyISAM,InnoDB,Memory,CSV,Archive。慕课网视频教程总结
show create table provinces;查看编码,引擎
use t1; 使用库 show database();查看使用的库 desc tb1;查看表结构 查看内容,select;AUTO_INCREMENT 自动编号,且必须与主键组合使用 默认情况下,起始值为1,每次的增量为1PRIMARY KEY主键,作用是使值具有唯一性,即值不能重复,主键不设置自动增长要手动添加编号PRIMARY KEY一张数据表只能有一个 UNIQUE KEY 可以有多个,且可以为空,也可以保证唯一性,UNIQUE KEY 中的内容不能重复,例如表中username已经有一个“tom”了,就不能再次添加一个‘tom’约束保证完整性和唯一性主键约束:PRIMARY KEY 类似身份证id 唯一约束:UNIQUE KEY 保证注册用户名唯一 默认值: DEFAULT 默认为男 非空约束:NOT NULL 外键约束:FOREIGN KEY 实现一对多
外键:父表先写,字表参照mysql> CREATE TABLE provinces( -> id SMALLINT UNSIGNED PRIMARY KEY AUTO_INCREMENT, -> pname VARCHAR(20) NOT NULL -> ); mysql> CREATE TABLE users( -> id SMALLINT UNSIGNED PRIMARY KEY AUTO_INCREMENT, -> username VARCHAR(20) NOT NULL, -> pid SMALLINT UNSIGNED, -> FOREIGN KEY(pid) REFERENCES provinces(id) //pid 外键列,id 参照列,类型必须相同 -> );SMALLINT UNSIGNED PRIMARY KEY AUTO_INCREMENT, -> pname VARCHAR(20) NOT NULL -> ); mysql> CREATE TABLE users( -> id SMALLINT UNSIGNED PRIMARY KEY AUTO_INCREMENT, -> username VARCHAR(20) NOT NULL, -> pid SMALLINT UNSIGNED, -> FOREIGN KEY(pid) REFERENCES provinces(id) //pid 外键列,id 参照列,类型必须相同 -> );外键约束的本质就是增加数据的可重复利用性。也就是说假如我们有一个省份的表:P表,这个表里存储着中国34个省份名称并且有唯一编号约束(比方说1.河南省 2.四川省 3.广东省 4.吉林省……);现在有个统计各省GDP的表A,有个统计人籍贯的表B,还有一个统计各省人口的表C。如果把各省的名字再输入一遍的话那就需要输入4遍省份的名字,这种工作像评论区有些手插在裤裆里不动手操作还骂老师教的不好的人肯定会觉得很麻烦;为了这些人,MySQL发明了一个非常牛逼的方法:从那个P表里把个省份的序号直接引用过来分别填在A、B、C表中,这样P表中的信息就被A、B、C三个表给共享了,就达到了一次输入,永久使用的目的。表级约束与列级约束由操作数目的多少来决定。 列级约束既可以在列定义时声明,也可以在列定义后声明,表级约束只能在列定义后声明。添加多列:alter table users1 add (tt varchar(10) not null, ll tinyint not null);
添加外键约束:ALTER TABLE users2 ADD FOREIGN KEY(pid) REFERENCES provinces (id);
添加默认约束:ALTER TABLE users2 ALTER age SET DEFAULT 15;
删除默认约束:ALTER TABLE users2 ALTER age DROP DEFAULT;
数据表的修改操作:无非就是添加列,删除列,添加约束,删除约束。用的是ALTER,而INSERT是对数据表添加插入记录用的。删除主键约束:ALTER TABLE tbl_name DROP PRIMARY KEY 删除唯一约束:ALTER TABLE tbl_name DROP {INDEX|KEY} index_name 删除外键约束:ALTER TABLE tbl_name DROP FOREIGN KEY fk_symbol数据表更名 ALTER TABLE user2 RENAME user3;或 RENAME TABLE user2 TO user3修改列定义;<br> ALTER TABLE tableName MODIFY columnName SMALLINT UNSIGNED NOT NULL FIRST;<br> ALTER TABLE tableName CHANGE oldColumnName newColumnName INT NOT NULL AFTER username;<br>创建了少去改,破坏结构记录操作:curd约束: not null非空约束和default默认约束都没有表级约束,只有列级约束。 primary key主键约束和unique key唯一约束和foreign key外键约束,表级约束和列级约束都有。
















 4325
4325

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









