







Keil5-介绍
- ■ Keil 简介
- ■ 官网下载Keil软件安装包和板级支持包
- ■ Keil5文件介绍
- ■ Keil5编辑器功能
- ■ SCT分散文件
- ■ 魔术棒
- ■ 理论介绍
- ■ 芯片相关数据查找
- ■ 芯片Flash 起始地址
- ■ FLASH_SECTOR_SIZE 大小
- ■ FLASH_EraseSector(u32 startAddr,u32 codeLength)
- ■ STM32F205RBT6Flash大小
- ■ IROM1 地址 就是Flash 地址
- ■ IRAM1 IRAM2地址;
- ■ IRAM起始地址为啥为0x20000000
- ■ RAM分段使用
- ■ Stack_Size Heap_Size
- ■ 芯片手册分:数据手册(硬件比较关注的),参考手册(软件比较关注的)。
- ■ sct中(.bootcode) (.RamCode) 意思解析
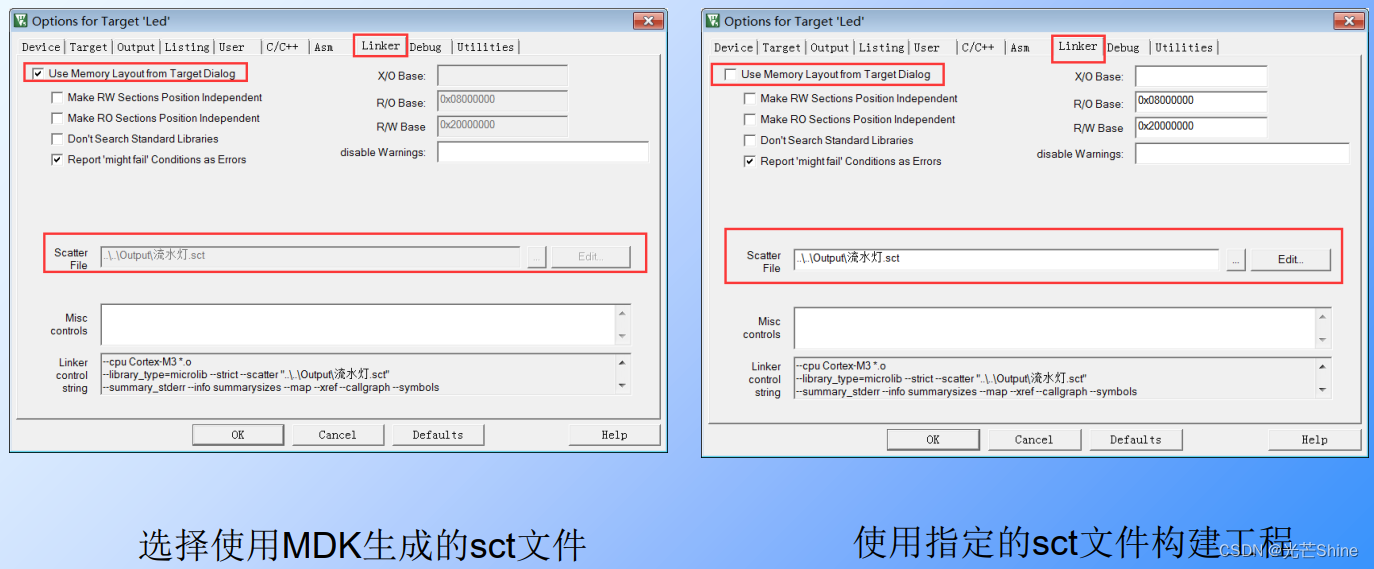
- ■ Use memory layout from target dialog 选项配合使用的,
- ■ _main()函数组成
■ Keil 简介
keil5 MDK下载地址
Pack下载地址
ST中文社区网:
学习方法:
参考官网的armlink手册。
■ 官网下载Keil软件安装包和板级支持包
- keil官网链接:https://www.keil.com/
- 进入官网后,点击 “Downloads”

- 我们这次是给GD32单片机下载编译环境,因此点击“MDK-Arm”。如果是给51单片机下载编译环境,点击右边的“C51即可”。
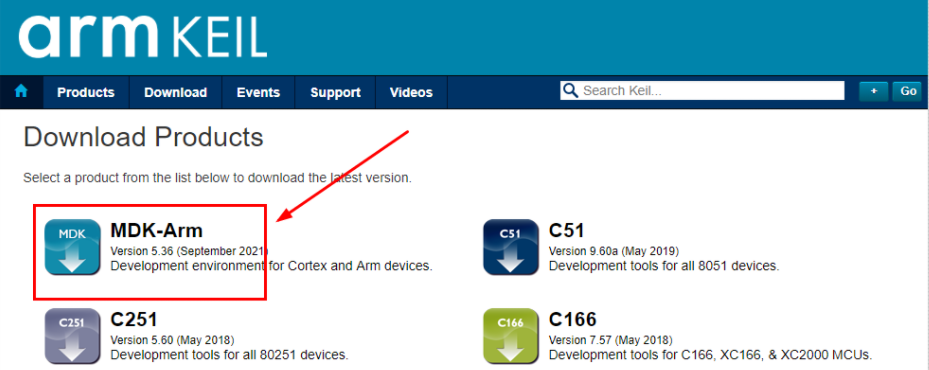
- 按照下图填写自己的相关信息,然后点击“Submit”即可。
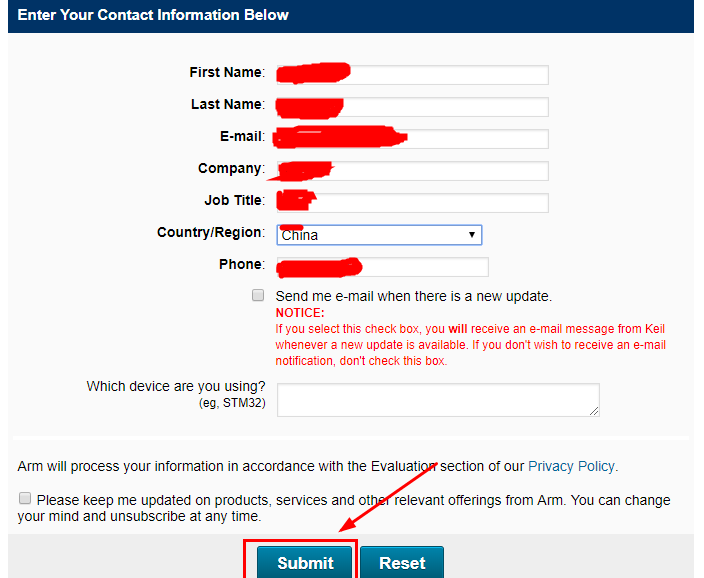
- 提交完成后,点击下图红框中的Keil软件,设置好下载路径即可完成Keil安装包的下载。
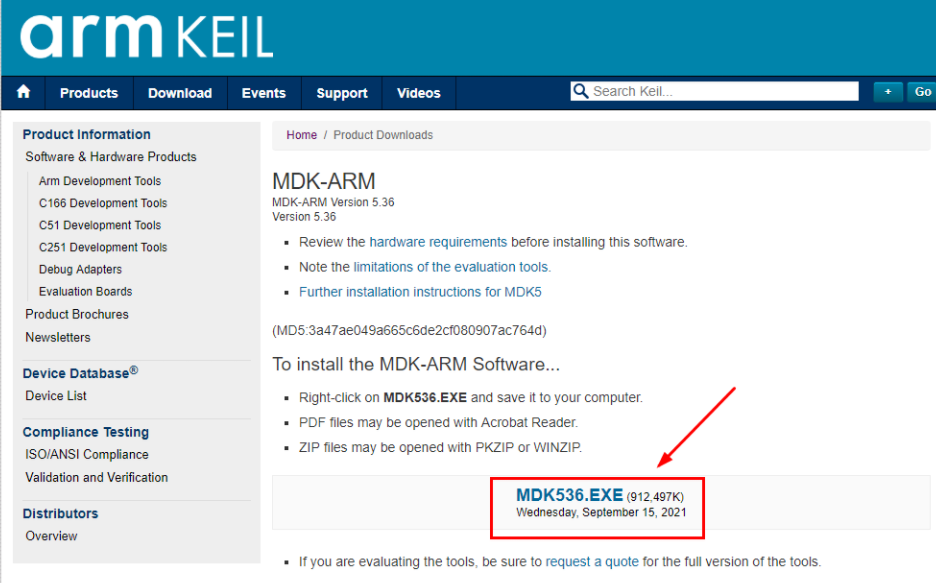
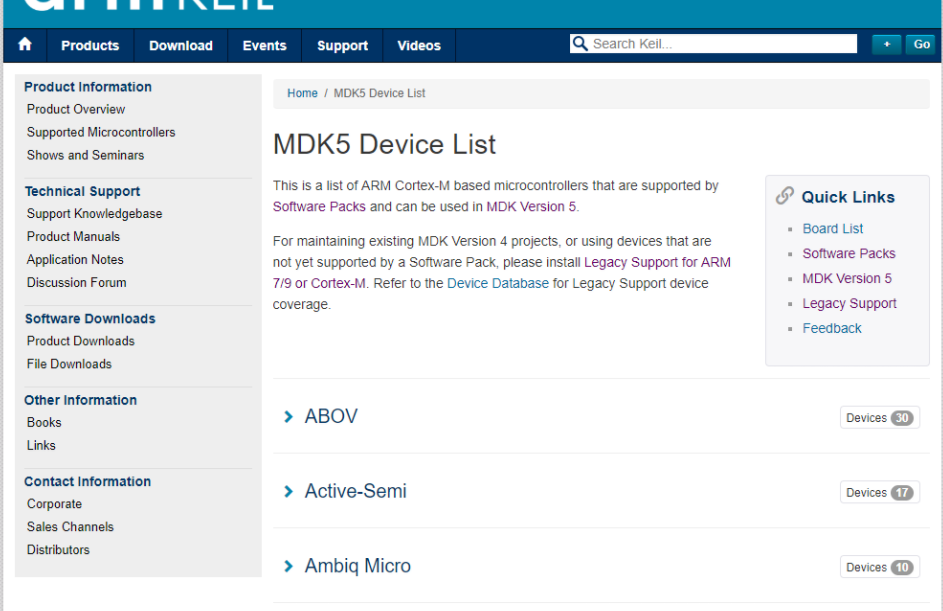
- keil软件包下载完成后,还需要下载对应单片机的板级支持包。点击下图中的“Device List”
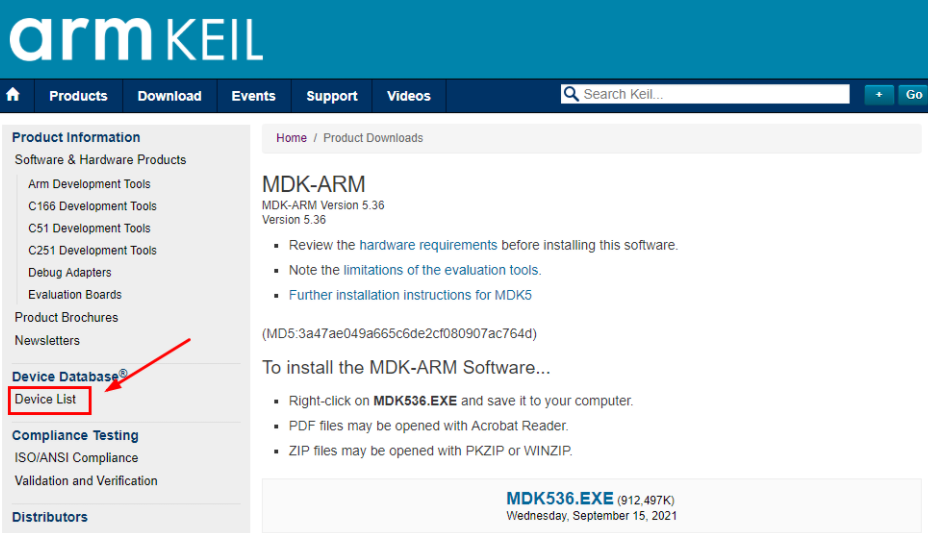
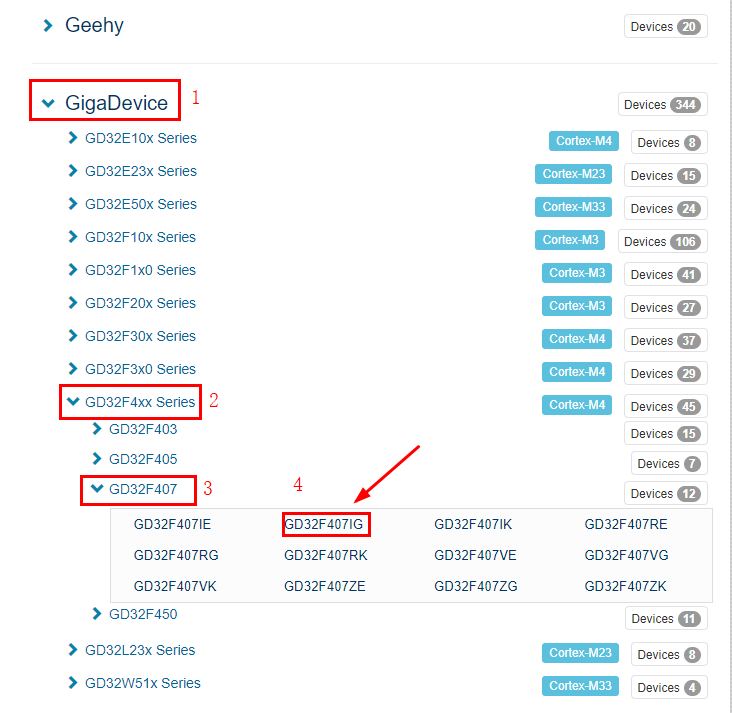
- 我们此次使用的单片机型号为GD32F407IG,因此在下图找到“GigaDevice”。按照1~4的顺序找到我们需要的单片机型号,点击4处的“GD32F407IG”。
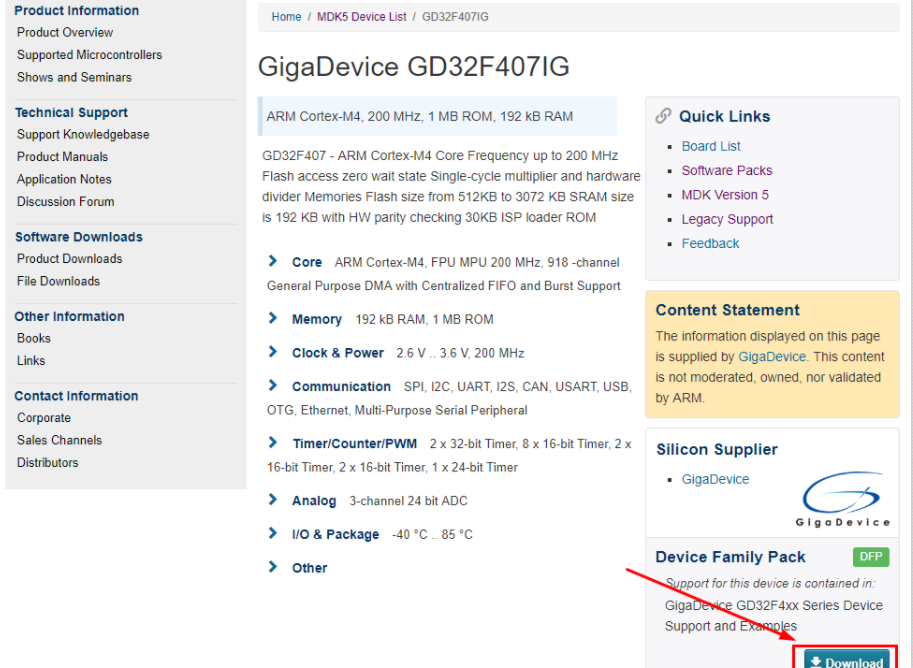
- 点击下图右下角的“Downloads”。在弹出的对话框中点击“OK”后选择下载路径即可完成下载。
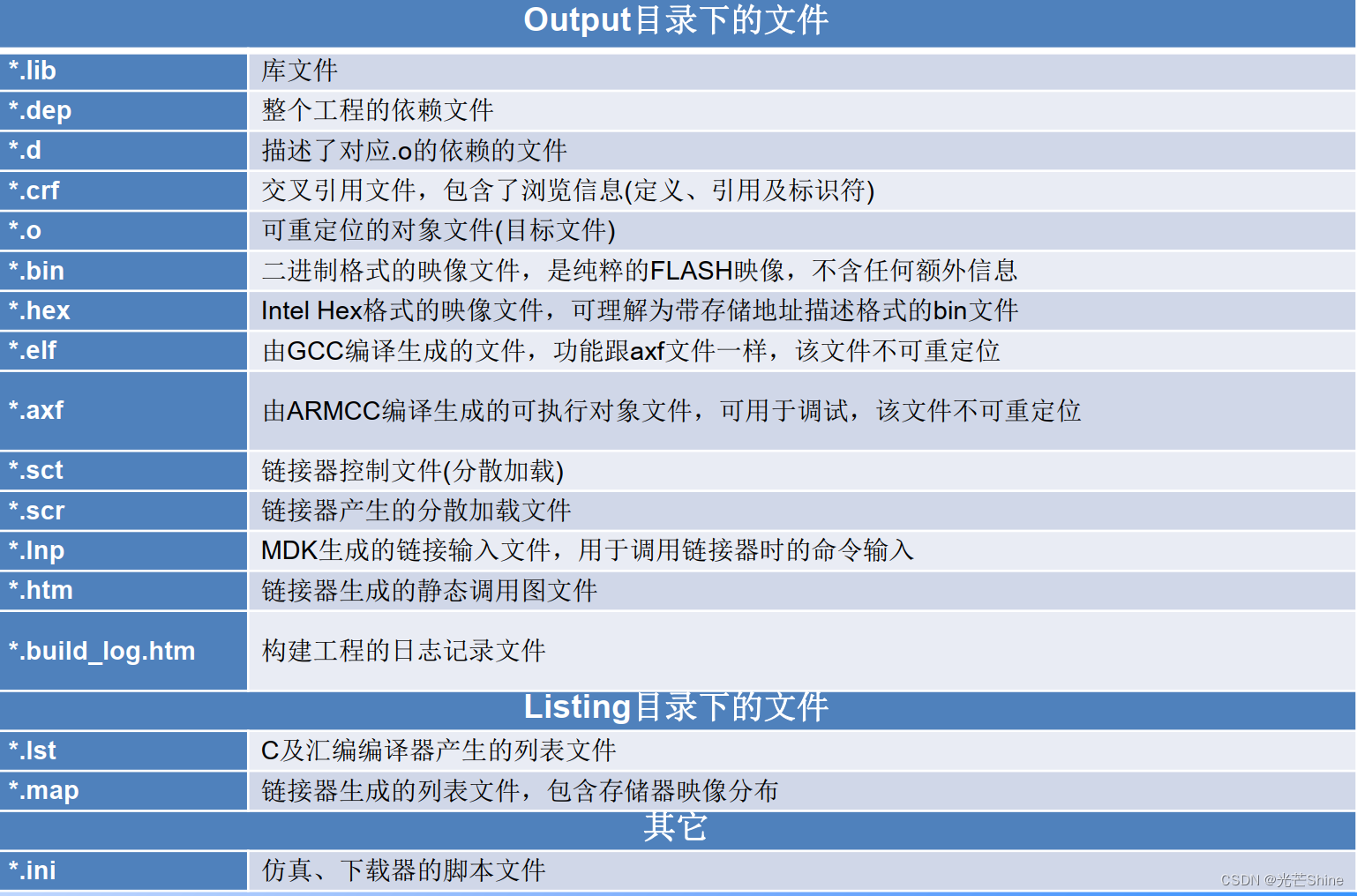
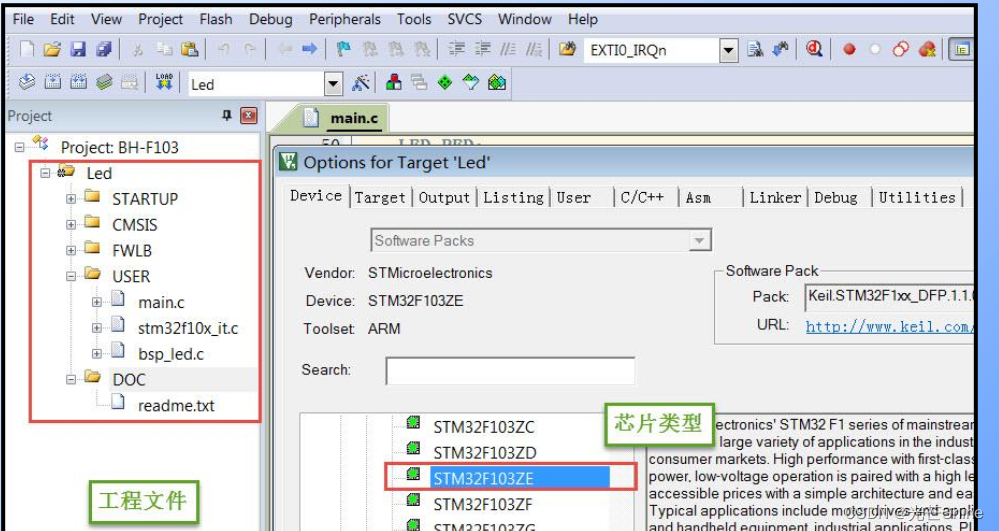
■ Keil5文件介绍
■ output
■ uvprojx
uvprojx 文件是 工程文件,它记录了整个工程的结构,如芯片类型、工程包含了哪些源文件等内容:
■ uvoptx
uvoptx 文件记录了工程的配置选项,如下载器的类型、变量跟踪配置、断点位置以及当前已打开的文件等等:

■ uvguix
uvguix 文件记录了MDK软件的GUI布局,如代码编辑区窗口的大小、编译输出提示窗口的位置等等。

uvprojx、 uvoptx及 uvguix都是使用XML格式记录的文件,若使用记事本打开可以看到XML代码。
uvprojx文件是最重要的 而uvoptx及uvguix文件并不是必须的,可以删除.重新使用MDK打开uvprojx工程文件后,会以默认参数重新创建uvoptx及uvguix文件。 (所以当使用Git/SVN等代码管理的时候,往往只保留uvprojx文件)
■ 源文件 (c、 cpp、 h、 s、 inc)
MDK支持c、 cpp、 h、 s、 inc类型的源代码文件,
编译器根据工程中的源文件最终生成机器码。
| 关键词 | 描述 |
|---|---|
| c cpp | 分别是c/c++语言的源代码, |
| h | 是它们的头文件, |
| s | 是汇编文件, |
| inc | 是汇编文件的头文件,可使用“$include”语法包含。 |
■ lib库文件
在某些场合下可能不希望提供给第三方一个可用的代码库,但不希望对方看到源码,这个时候我们就可以把工程生成lib文件(Library file)提供给对方,可把它像C文件一样添加到其它工程中,并在该工程调用lib提供的函数接口,除了不能看到*.lib文件的源码,在应用方面它跟C源文件没有区别。
■ dep、 d依赖文件
*.dep是整个工程的依赖,它以工程名命名,
*.d是单个源文件的依赖,它们以对应的源文件名命名 这些记录使用文本格式存储
■ .crf交叉引用文件
*.crf是交叉引用文件(Cross-Reference file),它主要包含了浏览信息(browse information),即源代码中的宏定义、变量及函数的定义和声明的位置。
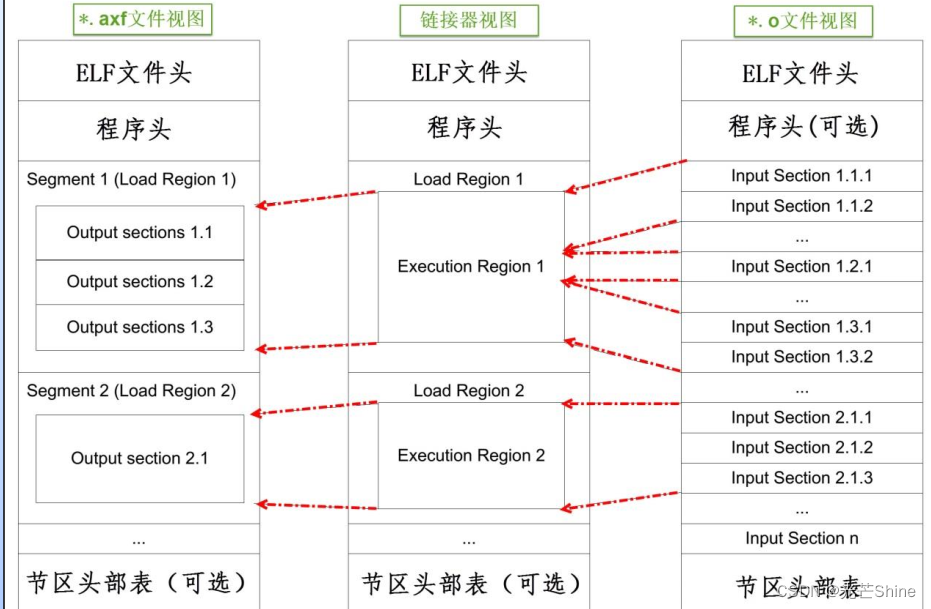
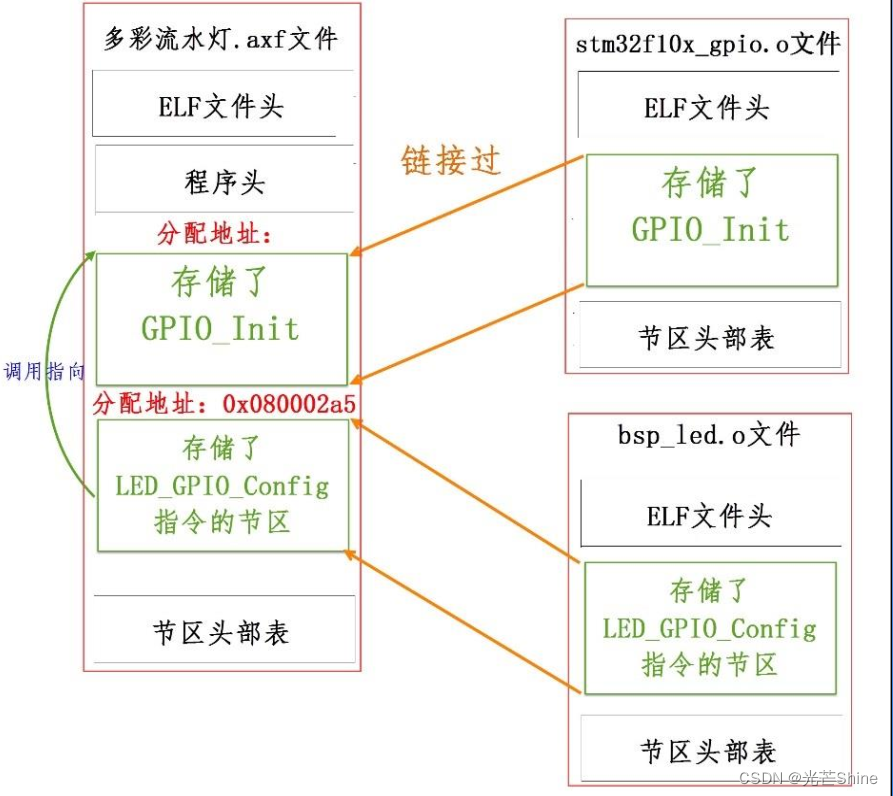
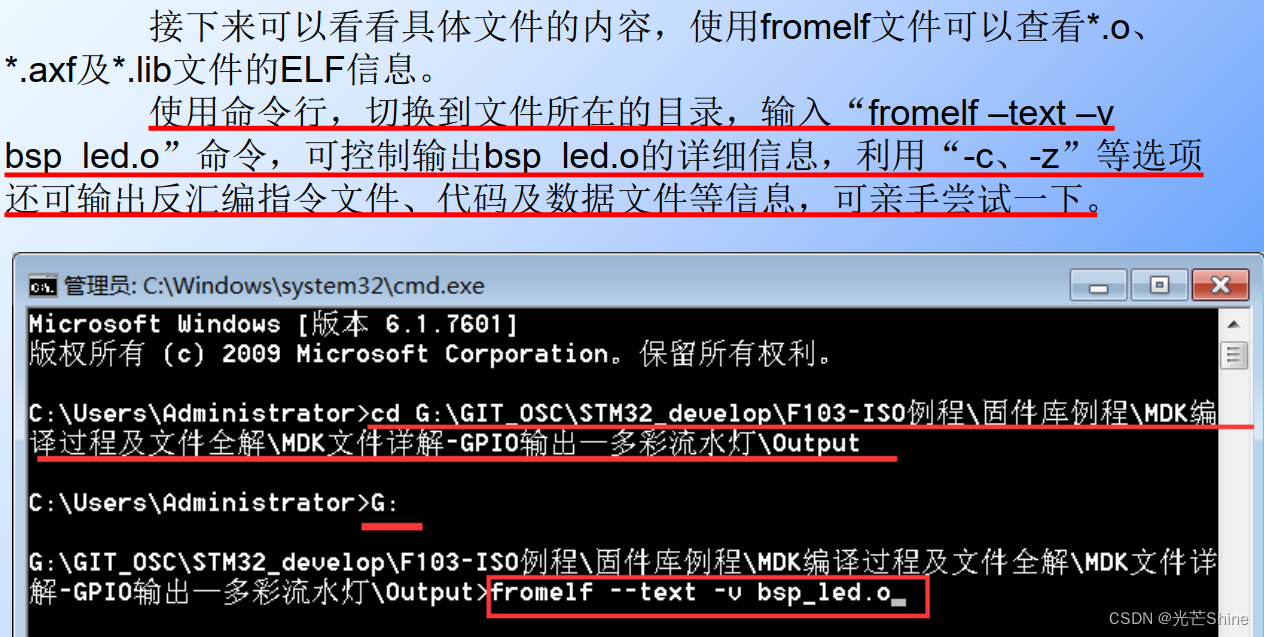
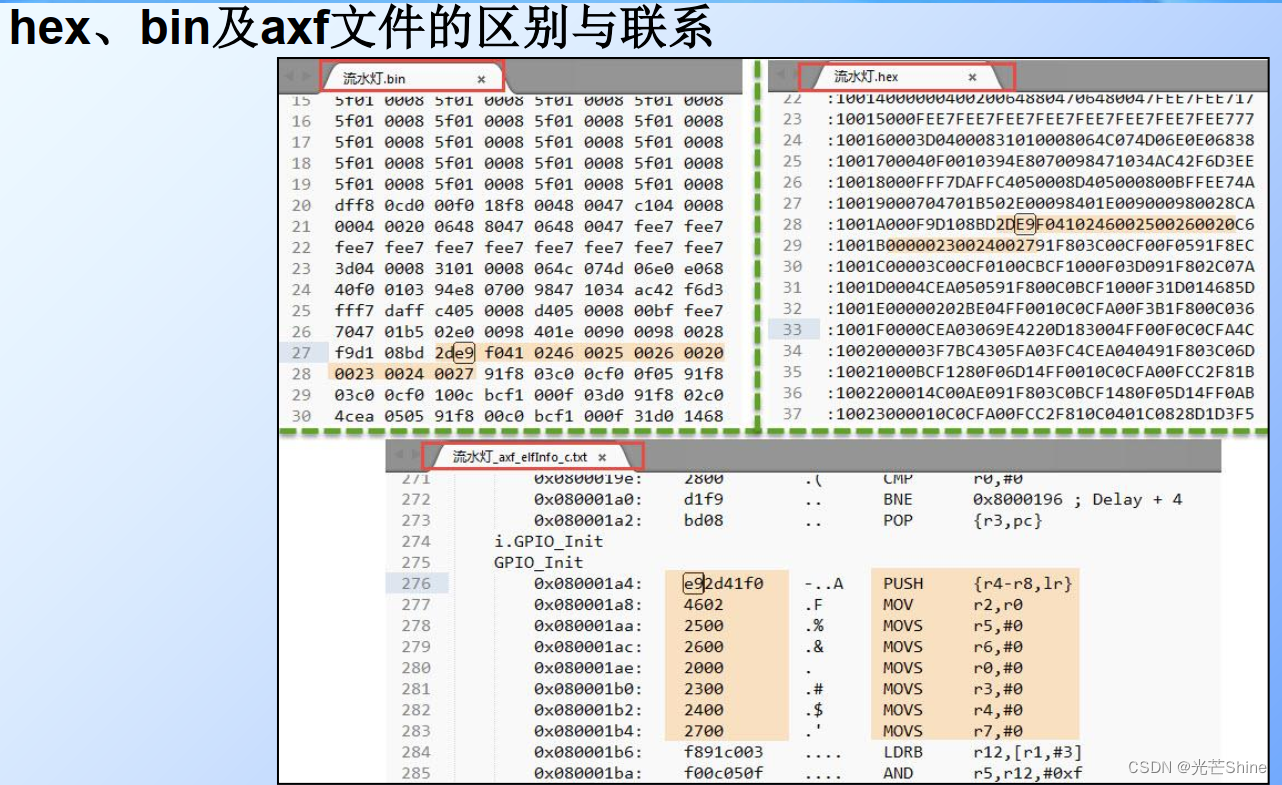
■ o,axf及elf文件
*.o、 *.elf、 *.axf、 .bin及.hex文件都存储了编译器根据源代码生成的机器码,根据应用场合的不同,它们又有所区别。
*.o、 *.elf、 *.axf以及前面提到的lib文件都是属于目标文件,它们都是使用ELF格式来存储的,
ELF是Executable and Linking Format的缩写,告诉操作系统如何链接、加载及执行该应用程序。
- 可重定位的文件(Relocatable File),包含基础代码和数据,但它的代码及数据都没有指定绝对地址,因此它适合于与其他目标文件链接来创建可执行文件或者共享目标文件。
例如MDK的armcc和armasm生成的*.o文件就是这一类,另外还有Linux的*.o 文件, Windows的 *.obj文件。 - 可执行文件(Executable File) ,
它包含适合于执行的程序,它内部组织的代码数据都有固定的地址(或相对于基地址的偏移),系统可根据这些地址信息把程序加载到内存执行。这种文件一般由链接器根据可重定位文件链接而成,
例如MDK的armlink生成的*.elf及*.axf文件, - 共享目标文件(Shared Object File),
MDK生成的*.lib文件就属于共享目标文件,它可以继续参与链接,加入到可执行文件之中。另外, Linux的.so,如/lib/ glibc-2.5.so, Windows的DLL都属于这一类


■ hex文件及bin文件
若编译过程无误,即可把工程生成前面对应的*.axf文件,而在MDK中使用下载器(DAP/JLINK/ULINK等)下载程序或仿真的时候, MDK调用的就是*.axf文件,它解释该文件,然后控制下载器把*.axf中的代码内容下载到STM32芯片对应的存储空间,然后复位后芯片就开始执行代码了。
然而,脱离了MDK或IAR等工具,下载器就无法直接使用*.axf文件下载代码了,它们一般仅支持hex和bin格式的代码数据文件。默认情况下MDK都不会生成hex及bin文件,需要配置工程选项或使用fromelf命令。
hex是Intel公司制定的一种使用ASCII文本记录机器码或常量数据的文件格式,这种文件常常用来记录将要存储到ROM中的数据,绝大多数下载器支持该格式
hex格式:

生成hex文件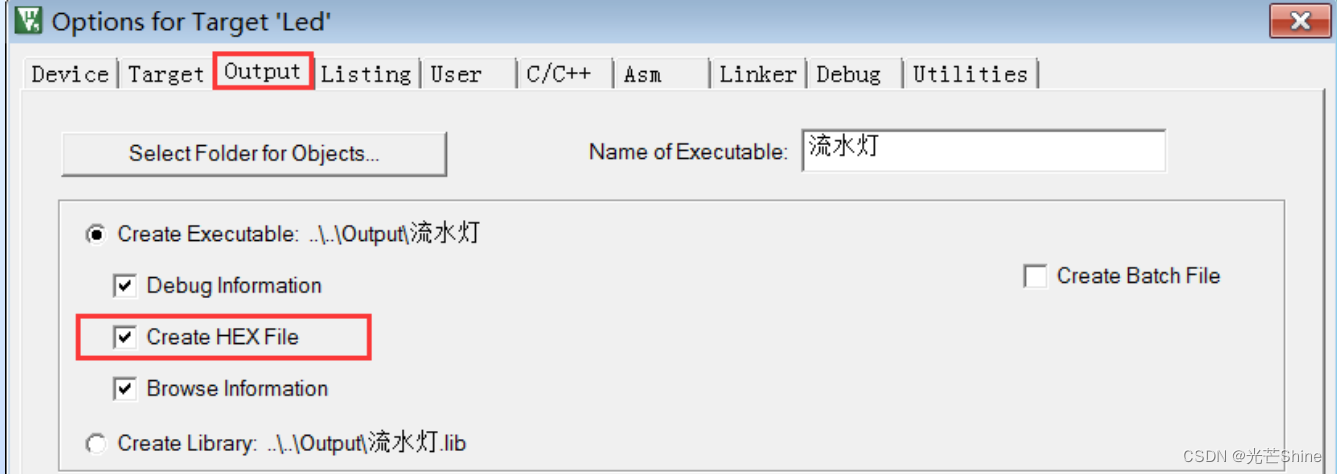
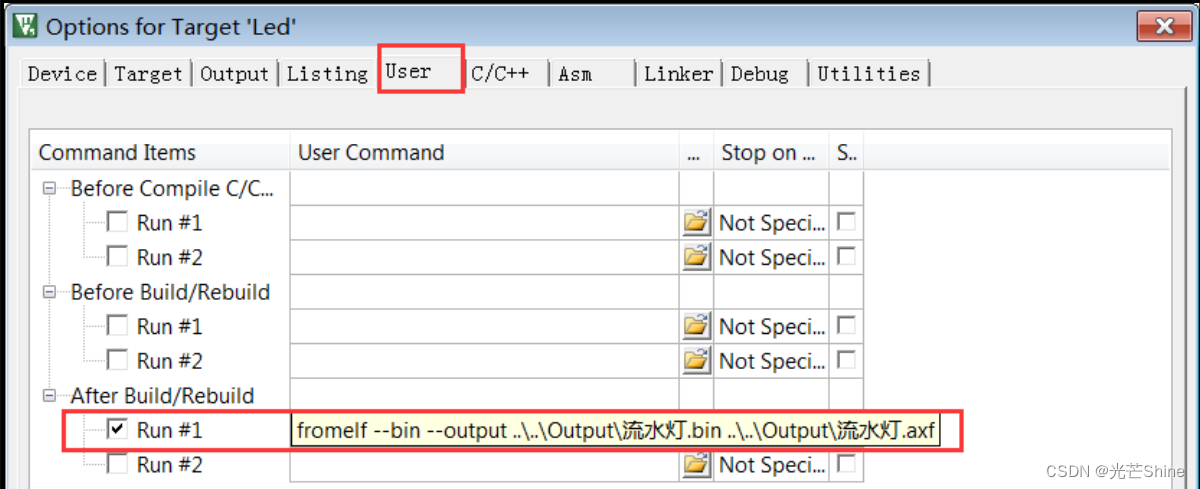
生成bin文件
fromelf需要根据工程的*.axf文件输入来转换得到bin文件,
“fromelf --bin --output …\Output\多彩流水灯.bin …\Output\多彩流水灯.axf”
■ Keil5编辑器功能
■ pack包
https://www.keil.com/dd2/Pack/
■ 使用微库
Targert-> Use MicroLIB 使用微库
使用微库能够减少代码容量,但有时也会造成编译错误(我反正没遇到)。
■ RTX-Kernel
■ PC-Lint 工具
Tools->Set-up PC-Lint… 配置PC-Lint 工具
C/C++静态代码检查工具,其中Logiscope RuleChecker和PC-Lint 是应用比较广泛的两个工具。
PC-Lint 的检查分很多种类,有强类型检查、变量值跟踪、语义信息、赋值顺序检查、弱定义检查、格式检查、缩进检查、const 变量检查和volatile变量检查等等。对每一种检查类型,PC-Lint 都有很多详细的选项,用以控制PC-Lint的检查效果。
PC-Lint:这个工具好像很牛逼的样子,据说它声称可以通过不运行代码找出80%的BUG
PC-Lint 是GIMPEL SOFTWARE公司开发的C/C++软件代码静态分析工具,它的全称是PC-Lint/FlexeLint for C/C++,
PC-Lint 能够在Windows、MS-DOS和OS/2平台上使用,以二进制可执行文件的形式发布
PC-Lint 检查作为代码走查的第一道工序。
PC-Lint不仅能够对程序进行全局分析,识别没有被适当检验的数组下标,报告未被初始化的变量,警告使用空指针以及冗余的代码,还能够有效地帮你提出许多程序在空间利用、运行效率上的改进点。
PC-Lint 能够检查出很多语法错误和语法上正确的逻辑错误,
PC-Lint 为大部分错误消息都分配了一个错误号
PC-Lint/FelexLint 提供了和许多编译器类似的告警级别设置选项-wLevel,
PC-Lint/FelexLint还提供了用于处理函数库的头文件的告警级别设置选项-wlib(Level)
PC-Lint 集成到很多开发环境或常用的代码编辑软件中,比如集成到Source Insight/SLICKEDIT/MS VC6.0/KEIL C…等
PC-Lint 8.0对VC++6和VC++7.0的支持是最完善的 (Microsoft Visual C++)
PC-Lint 与source insight 集成
PC-Lint 与UltraEdit 集成
以Microsoft Visual C++ 6的开发环境为例
■ 定制化工具菜单
Tools->Customize Tools Menu… 定制化工具菜单
■ SVCS 版本控制工具
SVCS 版本控制工具。 我只会使用git工具,可以是gitlab,或者github。
■ map文件
从map文件中,我们可以找到很多有用的信息,比如数据放在ROM中那个位置,函数属于哪个section。
■ Debug中的USB/TCP/IP下载
■ assert(断言)
在使用C语言编写工程代码时,我们总会对某种假设条件进行检查,断言就是用于在代码中捕捉这些假设,可以将断言看作是异常处理的一种高级形式。
常常会出现一些隐藏得很深的BUG,或者是一些概率性发生的BUG,通常这些BUG在我们调试的过程中不会出现很明显的问题,但是如果我们将其发布,在用户的各种运行环境下,这些程序可能就会露出马脚了。那么,如何让我们的程序更明显的暴露出问题呢?这种情况下,我们一般都会使用 assert 断言函数,这是C语言标准库提供的一个函数,也就是说,它的使用与操作系统平台,调试器种类无关。我们只要学会了它的使用,便可一次使用,处处开花。
断言表示为一些布尔表达式,程序员相信在程序中的某个特定点该表达式值为真。可以在任何时候启用和禁用断言验证,因此可以在测试时启用断言,而在部署时禁用断言。同样,程序投入运行后,最终用户在遇到问题时可以重新起用断言。它可以快速发现并定位软件问题,同时对系统错误进行自动报警。
断言可以对在系统中隐藏很深,用其它手段极难发现的问题可以用断言来进行定位,从而缩短软件问题定位时间,提高系统的可测性。实际应用时,可根据具体情况灵活地设计断言。
#include <assert.h>
void assert( int expression );
1.assertEquals(expected,actual) 和 assertNotEquals(expected,actual);
比较实际值与预期值是否一致。如果一致,程序继续运行,否则抛出异常,会打印报错信息。常用断言方法,便于调试。
2.assertTrue(message,condition) 和 assertFalse(message,condition)
如果条件的真假与预期相同,程序继续运行,否则抛出异常,不会打印报错信息。
3.assertNull(message,object) 和 assertNotNull(message,object)
判断一个对象是否为空,如果结果与预期相同,程序继续运行,否则抛出异常。
4.assertSame(expected,actual) 和 assertNotSame(expected,actual)
判断预期的值和实际的值是否为同一个参数(即判断是否为相同的引用),如果结果与预期相同,程序继续运行,否则抛出异常。
assertSame(expected,actual) 和 assertEquals(expected,actual)的区别;
assertSame(A,B) ————————————> A==B
assertEquals(A,B)————————————>A.equals(B)
5.fail(message)
“fail”断言能使测试立即失败,这种断言通常用于标记某个不应该被到达的分支。例如测试中某个代码块要try catch,则在catch代码中加入fail(message)方法,否则代码直接进入catch块,无法判断测试结果。
#include <stdio.h>
#include <assert.h>
int main( void )
{
int i;
i=1;
assert(i++);
printf("%d\n",i);
return 0;
}

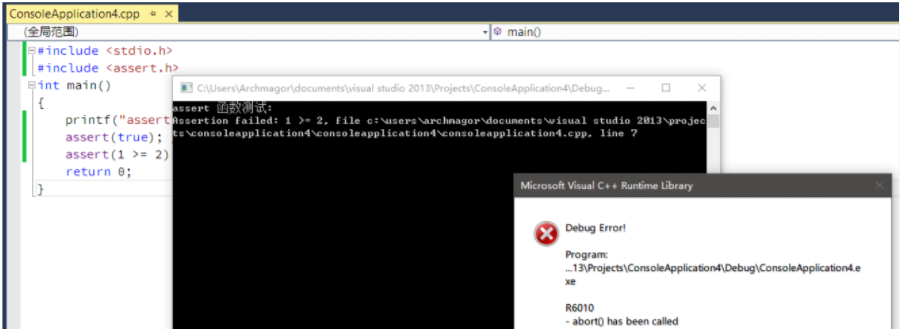
看看运行结果,因为我们给定的i初始值为1,所以使用assert(i++);语句的时候不会出现错误,进而执行了i++,所以其后的打印语句输出值为2。如果我们把i的初始值改为0,那么就回出现如下错误。
Assertion failed: i++, file E:\fdsa\assert2.cpp, line 8
Press any key to continue
是不是发现根据提示很快就能定位出错点呢?

按F5启动调试:
//…
assert( c1 /条件1/ && c2 /条件2/ );
//…
如果我们的程序在这里断言失败了,我们如何知道是 c1 断言失败还是 c2 断言失败呢,答案是:没有办法
//…
assert(c1 /条件1/);
assert(c2 /条件2/);
//…
这样,一旦出现问题,我们就可以通过行号知道是哪个条件断言失败了。
■ SCT分散文件
■ 适用范围
在Keil/ADS/IAR等编译工具中,可以通过分散加载机制实现。
分散加载通过配置文件实现,这样的文件称为分散加载文件。
分散加载(scatter)文件是一个文本文件,它可以用来描述连接器生成映像文件时需要的信息。
通过编写一个分散加载文件
来指定ARM连接器在生成映像文件时如何分配Code、RO-Data、RW-Data、ZI-Data等数据的存放地址。
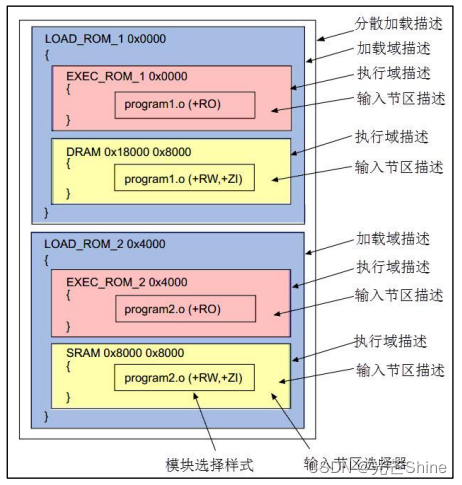
■ 加载区描述
加载域名 (基地址 | ("+" 地址偏移)) [属性列表] [最大容量]
{
执行区域描述
}
LR_IROM1 0x08000000 0x00080000 { ; load region size_region
......
}
加载域名:名称,在 map 文件中的描述会使用该名称来标识空间。如本例中只有一个加载域,该域名为 LR_IROM1。
基地址+地址偏移:这部分说明了本加载域的基地址,可以使用+号连接一个地址偏移,算进基地址中,整个加载域以它们的结果为基地址。如本例中的加载域基地址为 0x08000000,刚好是 STM32 内部 FLASH 的基地址。
属性列表:属性列表说明了加载域的是否为绝对地址、N 字节对齐等属性,该配置是可选的。本例中没有描述加载域的属性。
最大容量:最大容量说明了这个加载域可使用的最大空间,该配置也是可选的,如果加上这个配置后,当链接器发现工程要分配到该区域的空间比容量还大,它会在工程构建过程给出提示。本例中的加载域最大容量为 0x00080000,即 512KB,正是本型号 STM32 内部 FLASH 的空间大小。
■ 执行域
执行域名 (基地址 | "+" 地址偏移) [属性列表] [最大容量 ]
{
///输入节区描述
}
输入节区描述 .o .ANY (+RO)等的用法
配合加载域及执行域的配置,在相应的域配置“输入节区描述”即可控制该节区存储到域中
//除模块选择样式部分外,其余部分都可选选填
模块选择样式"("输入节区样式",""+"输入节区属性")"
模块选择样式"("输入节区样式",""+"节区特性")"
模块选择样式"("输入符号样式",""+"节区特性")"
模块选择样式"("输入符号样式",""+"输入节区属性")"
-----------------------------------------------------------------------------
*.o (RESET, +First) //启动代码的首次执行地址,RO执行域名称为ER_IROM1,
//将 RESET 段最先加载到本域的起始地址处
//首次执行的地址为RESET标号所表示的地址,RESET 存储的是向量表
//对应启动文件中的AREA RESET, CODE, READONLY
*(InRoot$$Sections) //稍后文件中会单独讲到
.ANY (+RO) //加载所有匹配目标文件的只读属性数据,包含:Code、 RW-Code、 RO-Data。
------------------------------------------------------------------------------
模块选择样式:模块选择样式可用于选择 o 及 lib 目标文件作为输入节区,它可以直接使用目标文件名或“*”通配符,也可以使用“.ANY”。
“.o”可以选择所有 o 文件.
使用“.lib”可以选择所有 lib 文件.
使用“”或“.ANY”可以选择所有的 o 文件及 lib 文件。
其中“.ANY”选择语句的优先级是最低的,所有其它选择语句选择完剩下的数据才会被“.ANY”语句选中。
示例文件中“(RESET,+First)”语句的 RESET 就是输入节区样式,它选择了名为 RESET 的节区,并使用后面介绍的节区特性控制字“+First”表示它要存储到本区域的第一个地址。
示例文件中的“(InRoot$$Sections)”是一个链接器支持的特殊选择符号,它可以选择所有标准库里要求存储到 root 区域的节区,如__main.o、__scatter.o 等内容。
输入符号样式: 同样地,使用输入符号样式可以选择要控制的符号,符号样式需要使用“:gdef:”来修饰。例如可以使用“*(:gdef:Value_Test)”来控制选择符号“Value_Test”。
输入节区属性:通过在模块选择样式后面加入输入节区属性,可以选择样式中不同的内容,每个节区属性描述符前要写一个“+”号,使用空格或“,”号分隔开.5
节区特性:节区特性可以使用“+FIRST”或“+LAST”选项配置它要存储到的位置,FIRST 存储到区域的头部,LAST 存储到尾部。通常重要的节区会放在头部,而CheckSum(校验和)之类的数据会放在尾部。
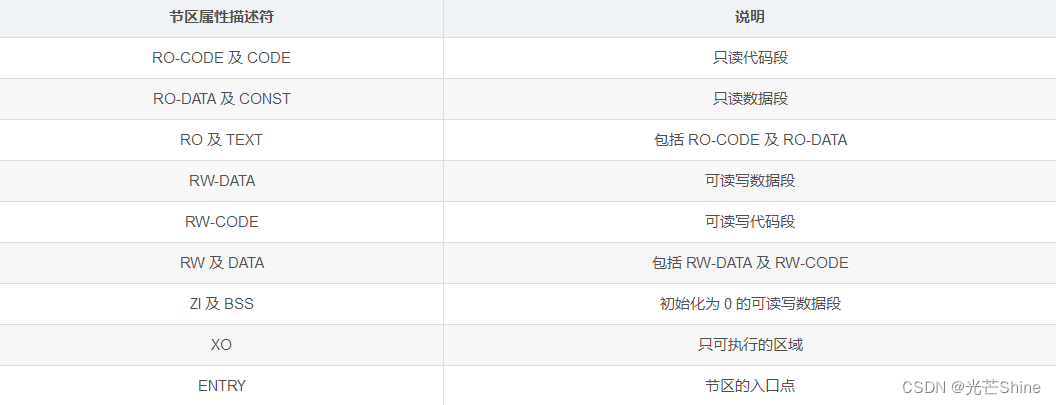
例如,示例文件中使用“.ANY(+RO)”选择剩余所有节区 RO 属性的内容都分配到执行域ER_IROM1中,使用“.ANY(+RW +ZI)”选择剩余所有节区 RW及 ZI属性的内容都分配到执行域 RW_IRAM1 中。
■ 分散加载文件应用
如何使用分散加载
连接器的命令行选项提供了一些对数据和代码位置的控制,但要对位置进行全面控制,则需要使用此命令行中的输入内容更详细的指令。需要或最好使用分散加载描述的情况包括如下:
- 设置源文件中定义的所有变量自动按地址分配到外部SRAM 这样就不需要再使用关键字“attribute”按具体地址来指定了
- 复杂内存映射:如果必须将代码和数据放在多个不同的内存区域中,则需要使用详细指令指定将哪些数据放在哪个内存空间中。
- 不同类型的内存:许多系统都包含多种不同的物理内存设备,如闪存、 ROM、 SDRAM 和快速 SRAM。分散加载描述可以将代码和数据与最适合的内存类型相匹配。例如,可以将中断代码放在快速 SRAM 中以缩短中断等待时间,而将不经常使用的配置信息放在较慢的闪存中。
- 内存映射的I/O 分散加载描述可以将数据节准确放在内存映射中的某个地址,以便能够访问内存映射的外围设备。
- 将函数放在内存中的固定位置,即使已修改并重新编译周围的应用程序。
- 使用符号标识堆和堆栈:链接应用程序时,可以为堆和堆栈位置定义一些符号。
- 控制代码的加载区与执行区的位置: 例如可以把程序代码存储到单位容量价格便宜的 NAND-FLASH 中,但在NAND-FLASH 中的代码是不能像内部 FLASH 的代码那样直接提供给内核运行的,这时可通过修改分散加载文件,把代码加载区设定为 NAND-FLASH 的程序位置,而程序的执行区设定为 SRAM 中的位置,这样链接器就会生成一个配套的分散加载代码,该代码会把NAND-FLASH 中的代码加载到 SRAM 中,内核再从 SRAM 中运行主体代码,大部分运行Linux 系统的代码都是这样加载的。
■ 控制文件分配到指定的存储空间
可以控制各个源文件定制到哪个部分存储器;
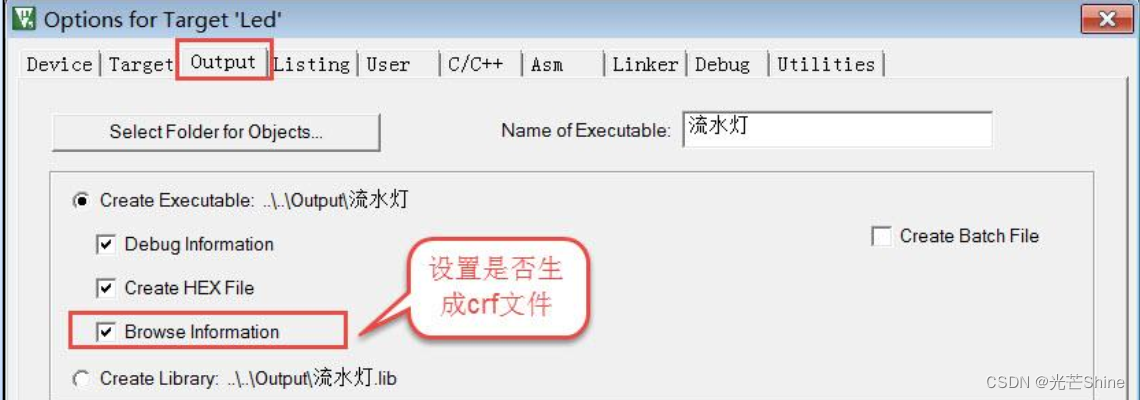
在 MDK 的工程文件栏中,选中要配置的文件,右键,并在弹出的菜单中选择“Options for File xxxx”即可弹出一个文件配置对话框,在该对话框中进行存储器定制。
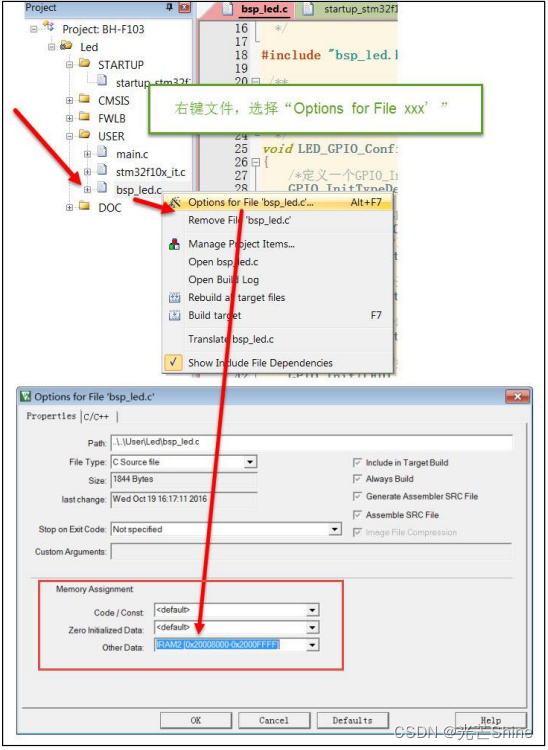
“Memory Assignment”区域(存储器分配),在该区域中可以针对文件的各种属性内容进行分配,如 Code/Const 内容(RO)、Zero Initialized Data 内容(ZIdata)以及 Other Data 内容(RW-data),IROM1、IRAM1、IRAM2 等存储器。
例如图中我们把这个 bsp_led.c 文件的 Other Data 属性的内容分配到了 IRAM2 存储器(在 Target 标签页中我们勾选了 IRAM1 及 IRAM2),当在bsp_led.c 文件定义了一些 RW-data 内容时(如初值非 0 的全局变量),该变量将会被分配到IRAM2 空间,配置完成后点击 OK,然后编译工程,查看到的 sct 文件内容。
LR_IROM1 0x08000000 0x00080000{ ; load region size_region
ER_IROM1 0x08000000 0x00080000{ ; load address = execution address
*.o (RESET, +First)
*(InRoot$$Sections)
.ANY (+RO)
}
RW_IRAM1 0x20000000 0x00008000 { ; RW data
.ANY (+RW +ZI)
}
RW_IRAM2 0x20008000 0x00008000 {
bsp_led.o (+RW)
.ANY (+RW +ZI)
}
}
可以看到在 sct 文件中的 RW_IRAM2 执行域中增加了一个选择 bsp_led.o 中 RW 内容的语句。
■ 手动修改sct文件
虽然 MDK 的这些存储器配置选项很方便,但有很多高级的配置还是需要手动编写 sct文件实现的,
例如 MDK 选项中的内部 ROM 选项最多只可以填充两个选项位置,若想把内部 ROM 分成多片地址管理就无法实现了;另外 MDK 配置可控的最小粒度为文件,若想控制特定的节区也需要直接编辑 sct 文件。
_ _attribute __”关键字的说明
当需要指定某个变量的内存地址时, MDK提供了 一 个关键字“_ _ attribute _ _”实现该功能。
■ 分配变量到指定的地址
/*要指定的地址*/
#define USER_ADDR((uint32_t)0x20005000)
uint8_t testValue __attribute__((at(USER_ADDR)));/*使用 atribute 指定该变量存储到 USER_ADDR,这种方式必须定义成全局变量*/
testValue = 0xDD;
attribute((at()) 来指定变量的地址,代码中指定 testValue 存储到USER_ADDR地址 0x20005000中.若把该地址改为外部存储器 SRAM的地址,变量就会被存储到外部 SRAM 了,因而利用该关键字在一定程度上可以定制各种存储器的空间分配。要注意使用这种方法定义变量时,必须在函数外把它定义成全局变量,才可以存储到指定地址上。
■ 自动分配变量到指定的 SRAM 空间
当有多个这样的变量时,为了防止变量占用的空间重叠,或减少碎片空间进行充分利用,就需要手动计算各个变量的地址了,非常麻烦,利用sct文件让链接器自动分配全局变量到指定的存储区域并进行管理,可以使得利用指定存储区域时就跟普通的变量定义一样简单。
取消勾选Options for Target->Linker->Use Memory Layout from Target Dialog
(1) 修改启动文件,在__main 执行之前初始化“指定的存储空间”的硬件
(2) 在 sct 文件中增加“指定的存储空间”对应的执行域;
(3) 使用节区选择语句选择要分配到“指定的存储空间”的内容;
(4) 编写测试程序,编译正常后,查看 map 文件的空间分配情况。
■ 一个普通的分散加载配置
假设,一个Cortex-M3内核的LPC17xx微控制器有Flash、RAM的资源如下:
Flash基址:0x00000000,大小:256KByte
RAM基址:0x10000000,大小:32Kbyte
那么一个分散加载文件应该怎样描述呢?可参考如下:
例子一:
LR_IROM1 0x00000000 0x00040000{ ;定义一个加载时域,域基址:0x0000000,域大小0x00040000,对应实际Flash的大小
ER_IROM 0x0000000 0x00040000{ ;定义一个运行时域,第一个运行时域必须和加载时域起始地址相同,否则库不能加载到该时域的错误,
;其域大小一般也和加载时域大小相同
*.o(RESET,+First) ;将RESET段最先加载到本域的起始地址外,即RESET的起始地址为0,RESET存储的是向量表
.ANY(+RO) ;加载所有匹配目标文件的只读属性数据,包含:Code、RW-Code、RO-Data。
}
}
例子二:
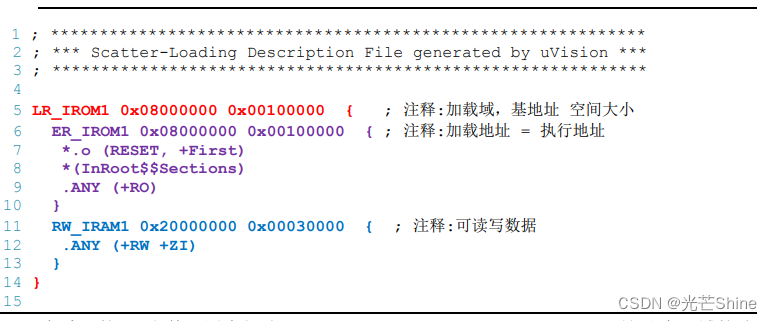
- 在默认的 sct 文件配置中仅分配了 Code、RO-data、RW-data 及 ZI-data 这些大区域的地址,链接时各个节区(函数、变量等)直接根据属性排列到具体的地址空间。
- sct 文件中主要包含描述加载域及执行域的部分,一个文件中可包含有多个加载域,而一个加载域可由多个部分的执行域组成。同等级的域之间使用花括号“{}”分隔开,最外层的是加载域,第二层“{}”内的是执行域。
; *************************************************************
; *** Scatter-Loading Description File generated by uVision ***
; *************************************************************
LR_IROM1 0x08000000 0x00020000 {
//定义一个加载域,域地址0x08000000,域大小为0x00020000
//load region size_region 所有代码需要下载到0x08000000 开始的区域中,且这个区域大小只有0x00020000
ER_IROM1 0x08000000 0x00020000 {
//load address = execution address 第一个运行时域必须和加载域起始地址相同,其大小一般也相同
//只能是只读的代码段和只读数据段
*.o (RESET, +First) //启动代码的首次执行地址,RO执行域名称为ER_IROM1,
//将 RESET 段最先加载到本域的起始地址外
//首次执行的地址为RESET标号所表示的地址,RESET 存储的是向量表
//对应启动文件中的AREA RESET, CODE, READONLY
*(InRoot$$Sections) //稍后文件中会单独讲到
.ANY (+RO) //加载所有匹配目标文件的只读属性数据,包含:Code、 RW-Code、 RO-Data。
}
RW_IRAM1 0x20000000 0x00005000 {
//再定义一个运行时域,域基址0x20000000
//RW data 执行域是以0x20000000 开始的长度为0x00004000 一段区域
.ANY (+RW +ZI) //其中包括的是哪些文件
}
}
■ 多块RAM的分散加载文件配置
还是上述的MCU,假设其增加了另一块RAM,其资源如下:
1、Flash基址:0x00000000,大小:256KByte
2、RAM1基址:0x10000000,大小:32Kbyte
3、RAM2基址:0x2007C000,大小:32Kbyte
如果我想将这两块连续的RAM都使用起来(可使用64Kb RAM)?分散加载文件应该怎样描述?
LR_IROM1 0x00000000 0x00040000{ ;定义一个加载时域,域基址:0x0000000,域大小0x00040000,对应实际Flash的大小
ER_IROM 0x0000000 0x00040000{ ;定义一个运行时域,第一个运行时域必须和加载时域起始地址相同,否则库不能加载到该时域的错误,
;其域大小一般也和加载时域大小相同
*.o(RESET,+First) ;将RESET段最先加载到本域的起始地址外,即RESET的起始地址为0,RESET存储的是向量表
.ANY(+RO) ;加载所有匹配目标文件的只读属性数据,包含:Code、RW-Code、RO-Data。
}
RW_IRAM1 0x10000000 0x00008000{ ;定义RAM1的运行时域,使用.ANY进行随意分配变量,这里不能使用*号代替,*表示匹配所有的目标文件,
.ANY(+RW +ZI) ;这样变量就无法分配到第二块RAM空间了
}
RW_IRAM2 0x2007C000 0x00008000{ ;定义RAM2的运行时域,使用.ANY进行随意分配变量,这里不能使用*号代替,*表示匹配所有的目标文件,
.ANY(+RW +ZI) ;这样变量就无法分配到第二块RAM空间了
}
;如果还有另外多的RAM块,在这里增加新的运行时域即可,格式和RAM2的定义相同
}
如上面所示,确实可以将两块RAM都使用起来,即有64KB的RAM可以使用,但其并不能完全等价于一个64KB的RAM,实际应用可能会碰到如下问题。
如我在main.c文件中声明了1个40KB的数值,
unsigned char GucTest0[40*1024]; /*定义一个40KB的数组*/
//unsigned char GucTest2[20*1024]; /*定义一个20KB的数组*/
//unsigned char GucTest3[20*1024]; /*定义一个20KB的数组*/
如上所示的程序在编译的时候会出现错误,并提示没有足够的空间,为什么?因为数组是一个整体,其内部元素的地址是连续的,不能分割的,但是
在两个不连续的32KB空间中,是没办法配出一个连续的40KB的地址空间,所以编译会提示空间不足,分配40KB数组失败。
还是上述程序,申请两个20KB的数组,编译结果会如何?
编译结果还是会提示空间不足,这是为什么?这里出错的原因其实和上面的原因是相同的,
关于大数组分配的解决方法,有两种,分别是:
第一种:将数组分开在不同的C文件中定义,避免在同一个C文件定义的数据大小总量超过其中最大的分区。
第二种:将一个C数组,使用段定义,使其从该C文件中独立除了,这样编译器就不会将它们作为一个整体来划分空间了,示例如下:
#pragma arm section zidata = "SRAM" //在C文件中定义新的段
unsigned char GucTest1[20*1024]; //定义一个20KB的数组
#pragma arm section //恢复原有的段
unsigned char GucTest2[20*1024]; //定义第二个20KB数组,这20KB数组不会和GucTest1作为一个整体来划分空间
■ 多块Flash的分散加载文件配置
多块Flash的分散加载文件配置
再一下上述的MCU,假其增加多了一块Flash,不是RAM,其资源如下:
1、Flash1基址:0x00000000,大小:256KByte;
2、Flash2基址:0x20000000,大小:2048KByte;
3、RAM基址:0x10000000,大小:32Kbyte;
注意这里多增加的一块的不是RAM,而是Flash,其情况会如何呢?假设其相同,
LR_IROM1 0x00000000 0x00040000{ ;定义一个加载时域,域基址:0x0000000,域大小0x00040000,对应实际Flash的大小
ER_IROM 0x0000000 0x00040000{ ;定义Flash1运行时域
*.o(RESET,+First) ;先加载向量表
.ANY(+RO) ;随意分配只读数据
}
ER_IROM1 0x2000000 0x00200000{ ;定义Flash2运行时域
.ANY(+RO) ;随意分配只读数据
}
RW_IRAM2 0x10000000 0x00008000{ ;定义RAM1的运行时域,使用.ANY进行随意分配变量,这里不能使用*号代替,*表示匹配所有的目标文件,
.ANY(+RW +ZI) ;这样变量就无法分配到第二块RAM空间了
}
}
■ 分散加载文件基础知识
要了解分散加载文件前首先需要对以下各个概念进行了解,
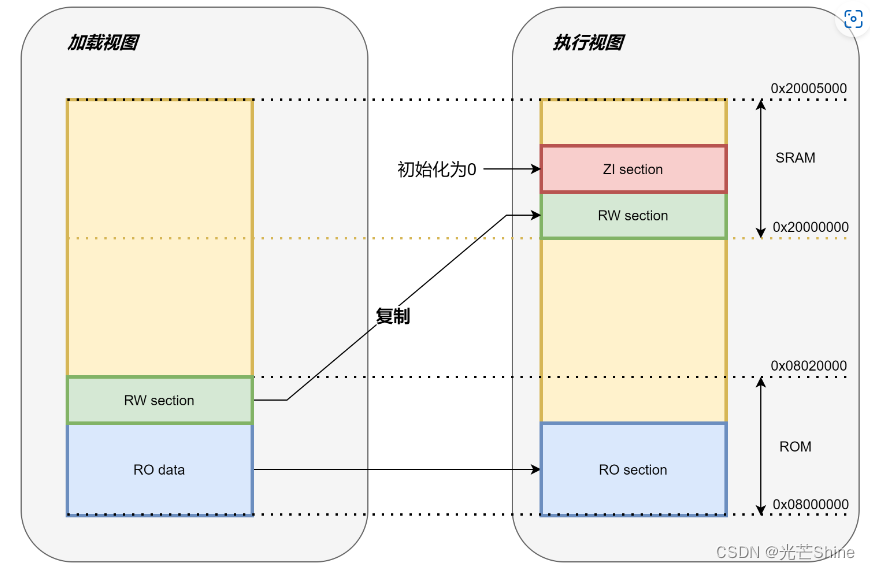
Code:为程序代码部分;
RO-Data:表示程序定义的常量及const型数据;
RW-Data:表示已经初始化的静态变量,变量有初值;
ZI-Data:表示未初始化的静态变量,变量无初值;
{
#define DATA (0x10000000) /*RO-Data */
char const GcChar = 5; /*RO-Data */
char GcStr[] = "string."; /*RW-Data */
char GcZero; /*ZI-Data */
}
Keil工程编译完后,查看其的map文件,可得结果如程序清单2.2类似
{
Total Ro Size(Code+RO-Data) 768( 0.75kB)
Total RW Size(RW-Data+ZI-Data) 2060( 2.01kB)
Total ROM Size(Code+RO-Data+RW-Data) 780( 0x76kB)
}
由程序清单2.2所示的map文件可看出:
ROM (Flash) Size = Code+RO-Data+RW-Data = 0.76KB;
RAM Size = RW-Data+ZI-Data = 2.01KB
为什么上述的RW-Data既占用Flash又占用RAM,变量不是放在RAM中的么,为什么会占用Flash?
因为RW数据不能像ZI那样"无中生有"的,ZI段数据只要求其所在的区域全部初始化为0,所以只需要程序根据编译器
给出的ZI基址及大小来将相应的RAM清0。但RW段数据却不这样做,所以编译器为了完成所有RW段数据赋值,其
先将RW段的所有初值,先保存到flash中,程序执行时,再flash中的数据搬运到RAM中,所以RW段既占用flash
用占用RAM,且占用的空间大小是相等的。
_main()函数主要由以下两个部分功能组成,
第一部分: _main():完成代码和数据的拷贝,并把ZI数据区清零。代码拷贝可将代码拷贝到另一个映射空间并执行,如
将代码拷贝到RAM执行;数据拷贝完成RW段数据赋值;数据区清零完成ZI段数据赋值。以上的代码和分散加载文件密切相关。
第二部分: _rt_entry():进行STACK和HEAP等的初始化。最后_rt_entry跳进main()函数入口。_rt_entry又将控制权交还给调试器。
■ 魔术棒
■ Device(设备)
■ Target(目标)
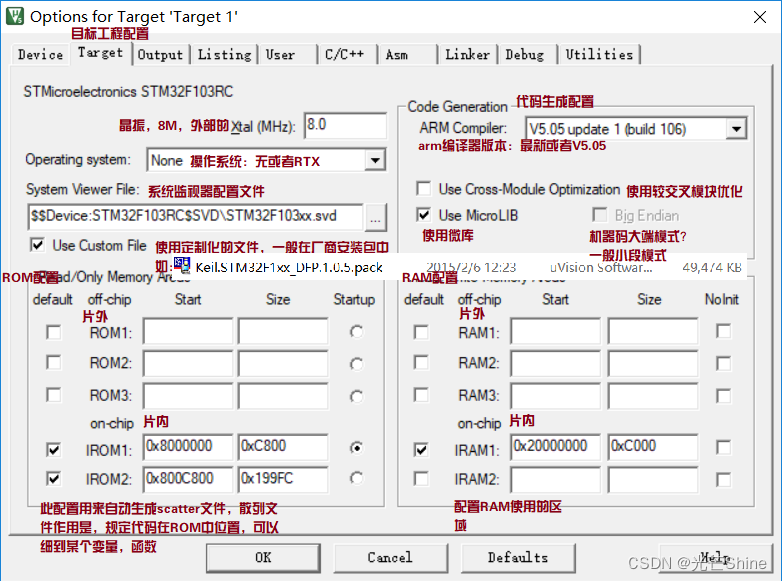
ROM与RAM配置名称介绍:
RAM 就是内存,ROM就是flash。
RAM是随机存取存储器(random access memory),是计算机内部存储器中的一种,也是其中最重要的,计算机和手机中一般把其叫做(运行)内存,它的速度要比硬盘快得多,所以用运行程序在RAM中
ROM是只读存储器(Read-Only Memory),也是计算机内部存储器中的一种,而硬盘是外部存储器 后来随着技术的发展,在ROM的基础上出现了新的半导体存储介质EPROM和EEPROM,这两种可擦写,这就不符合ROM的命名,但是由于是在ROM的技术上衍变出来的,所以延用了一部分原来的叫法,此时非易失的半导体存储介质开始得以广泛应用,被大量用于电脑主板的bios和嵌入式存储,
解释:
ROM 配置是用来自动生成scatter散列文件,如下图所说:
ROM与RAM配置,它帮助编译器定义下ROM,RAM的范围,使得编译时不会把数据放在范围外。当然你也可以将ROM或者RAM切成两部分使用,这里我是特殊使用所以和平常数据不一样。我把ROM分成了4部分,这里没看出来? 我通过scatter文件代码实现的。当使用手动分配的话,这里设置的IROM1和IROM2就失效了。具体在linker这里配置。
我们控制通过某些手段,将代码指定到ROM的任何位置,那么我们再次推,是不是数据也是一样。是的,我们可以设置精确到一个字符都能指定到ROM的某个位置(当然支持flash program,STM32基本都支持)。比如我实现了一个小功能将ROM指定某个1K位置空出来给用户平时存配置数据,掉电还能存在,代替EEROM。
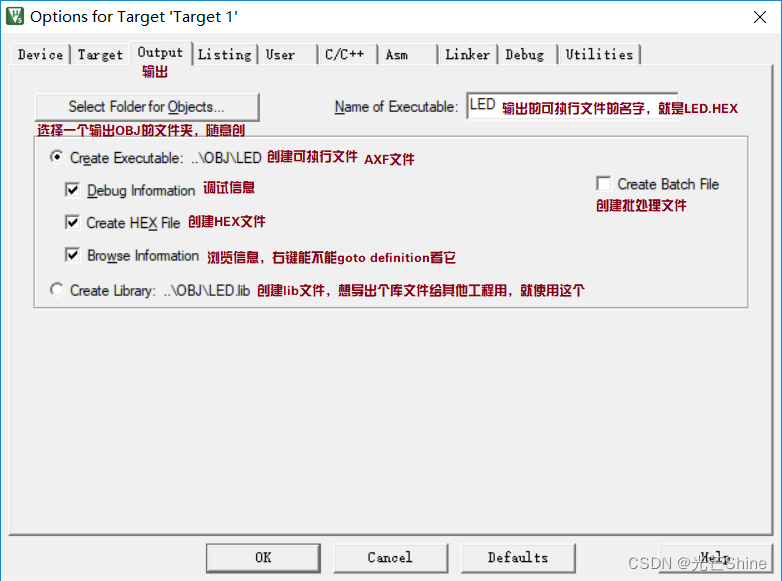
■ output(输出)
若我们想要在AXF文件中加入debug信息的话就勾上Debug Information。
若你想输出lib你就可以点击下面这个create library
■ Listing

■ User(用户)
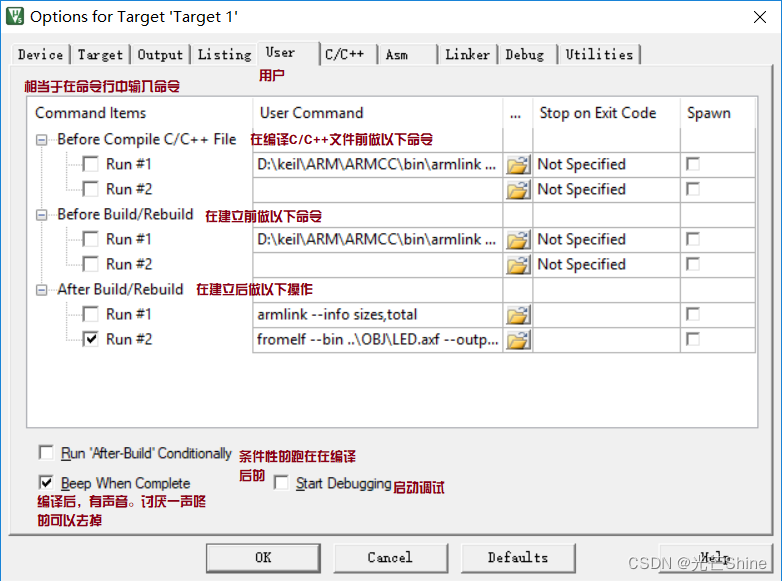
■ C/C++(代码)
说明了就是指定编译器生成规则。
实际核心是使用命令行,而界面的设置只是在编译执行命令行时添加参数而已
■ Asm(汇编)
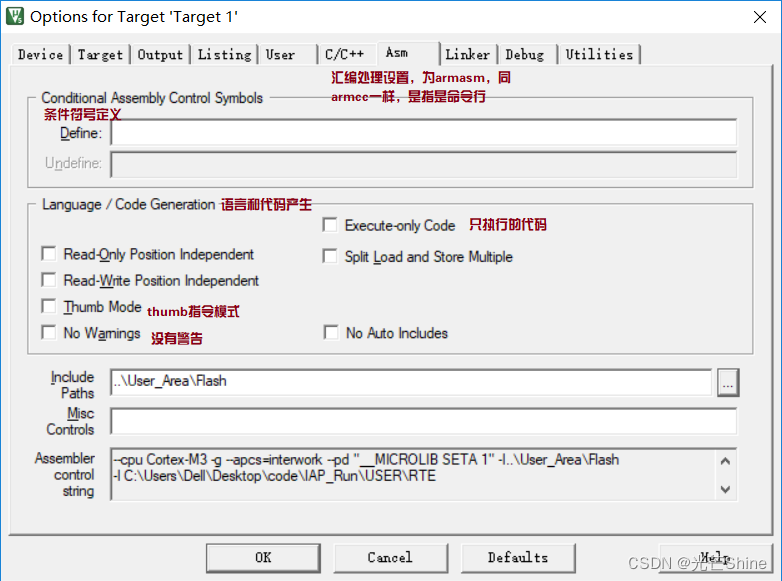
■ Linker(链接器)
链接器,它的设置基本是默认的,所以我们基本不动除非有特殊需要,去掉勾use memory layout from Target Dialog。
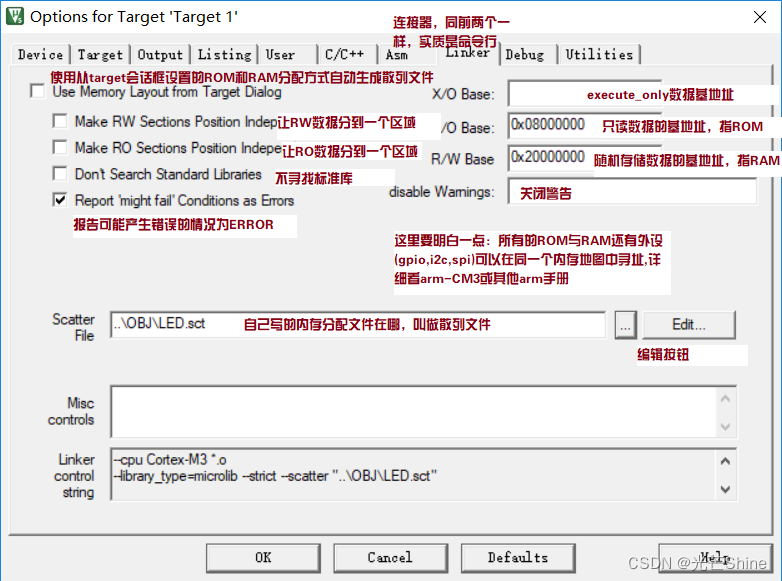
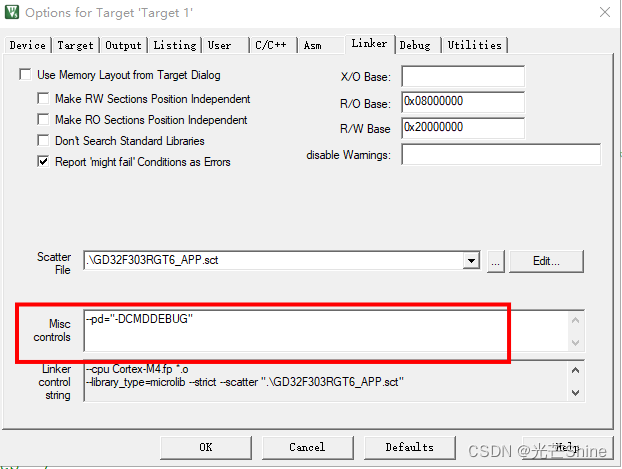
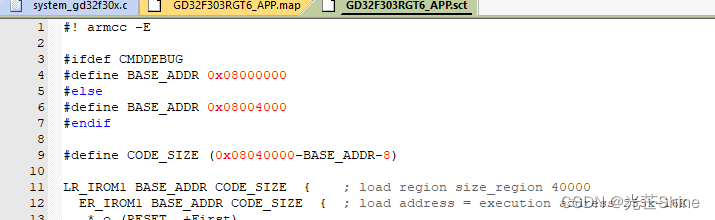
只有添加 --pd=“-DCMDDEBUG” 链接选项后执行sct文件就会执行CMDDEBUG 条件编译地址是 0x08000000
会在map文件中查兰到的生成地址为 0x08000000
RESET 0x08000000 Section 192 startup_n32g031.o(RESET)
屏蔽 //–pd=“-DCMDDEBUG” 链接选项后执行sct文件就会执行CMDDEBUG 条件编译地址是 0x08008000
会在map文件中查兰到的生成地址为 0x08008000
RESET 0x08008000 Section 192 startup_n32g031.o(RESET)
■ Debug(调试)
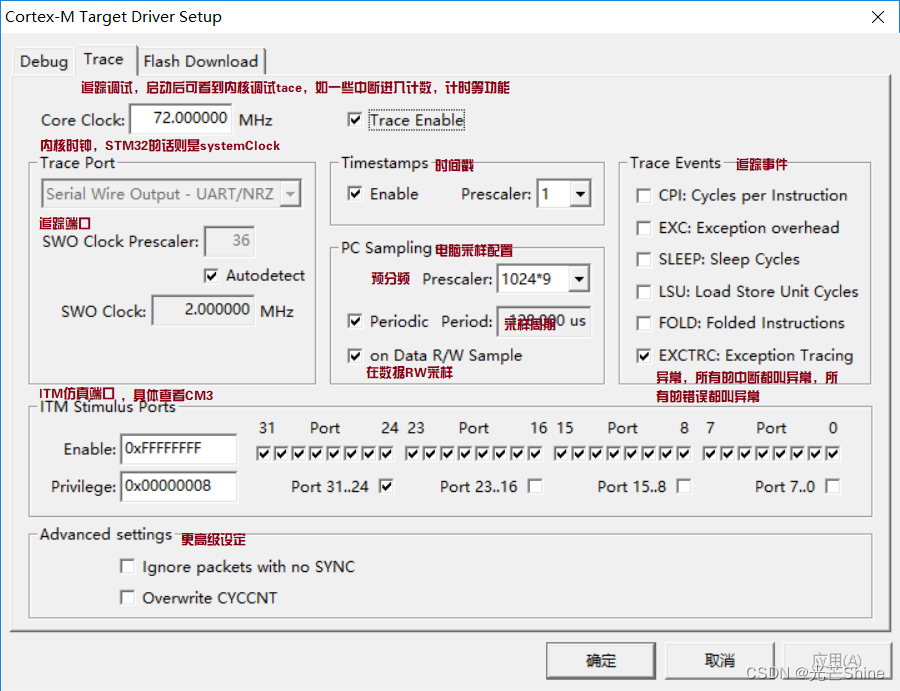
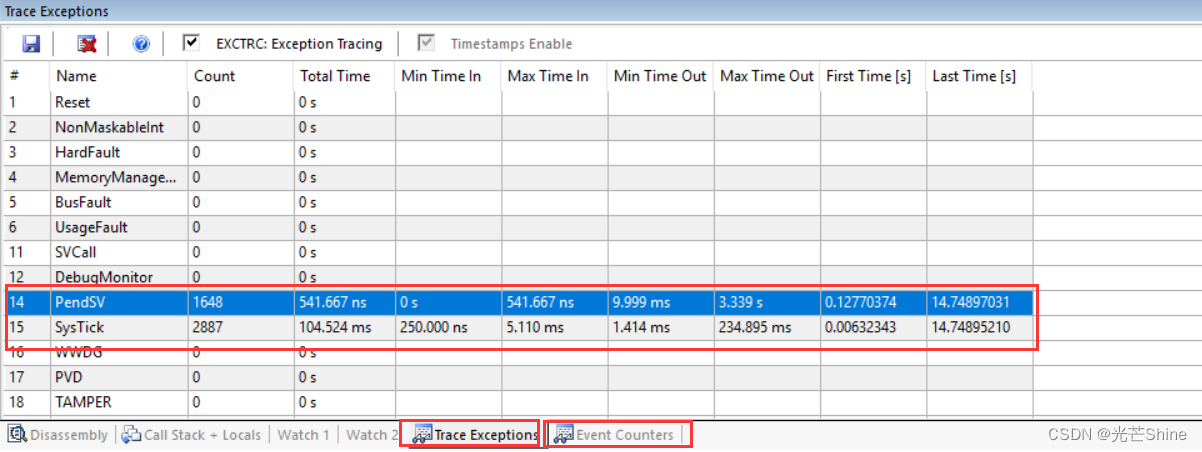
用来追踪异常(中断),比如,我可以看到进入了多少次的SysTick,或者调度程序,又或是查看哪个中断有没有触发,触发多少次。例如:在自己写RTOS时,你可以通过这个来查看PendSV(关于调度的一个异常,查看CM3内核可知)有没有被设置。
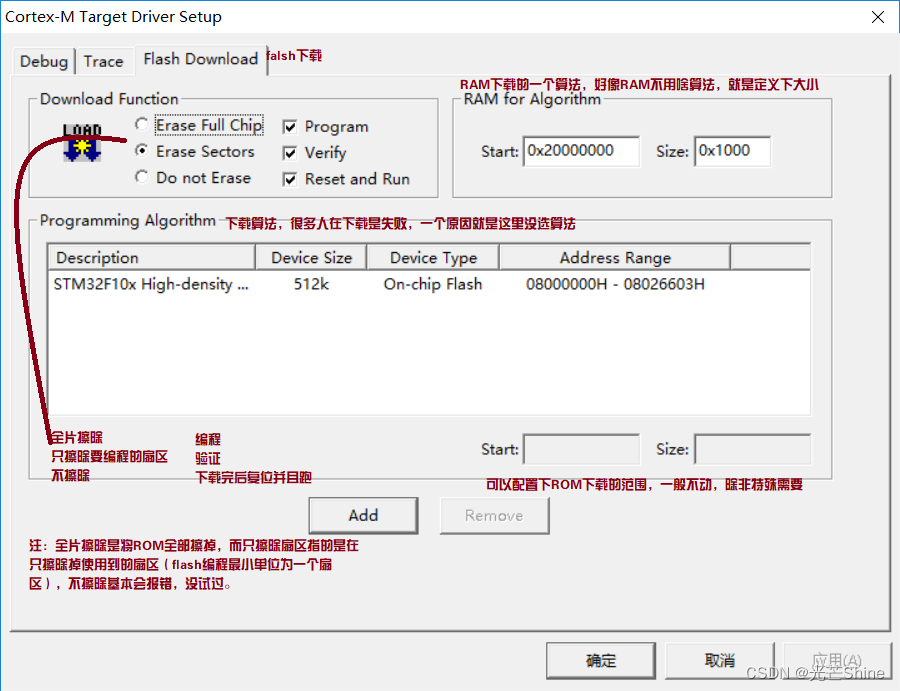
全片擦除,就是整个ROM都擦掉。
扇区擦除,就是你代码到哪个扇区就擦掉哪个。
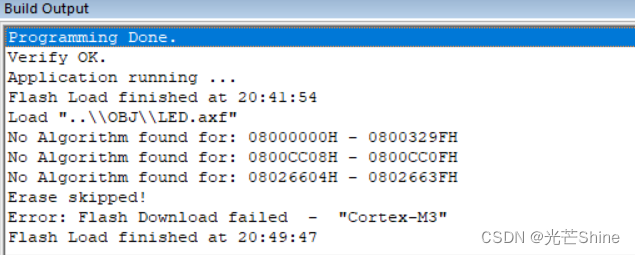
问题在于你的下载算法没有设置,设置一个算法即可。
■ Utilitier(应用)
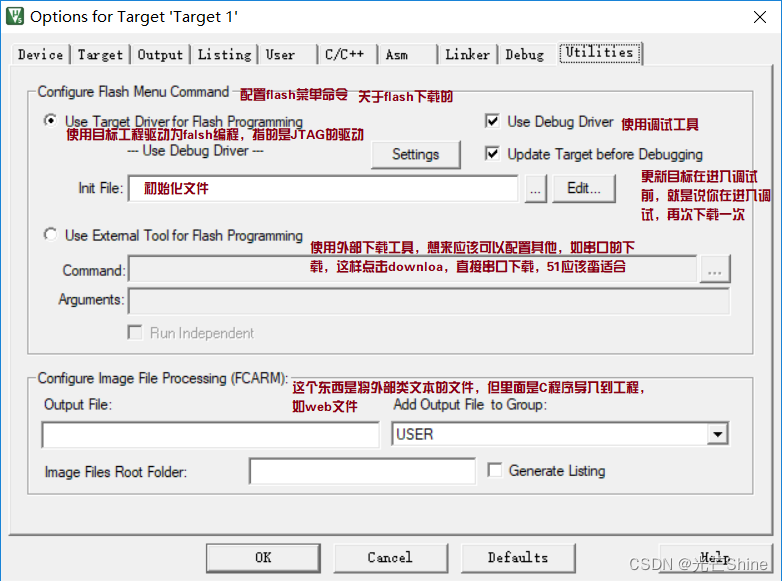
■ 理论介绍
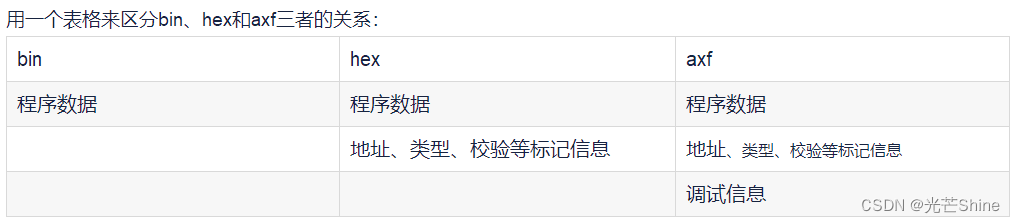
■ axf 和 bin、 hex
axf 和 bin、 hex 同样也属于程序文件,差别在于 axf 具有更多的调试信息。
同样一段代码,编译生成的bin文件最小,axf最大。
■ BIN 文件
BIN 文件本身只是数据,没有包含地址信息,所以在下载bin文件时需要选择内存的起始地址和终止地址,即要把bin文件下载到指定的内存空间。通常需要指定程序内存地址的芯片为ARM芯片和DSP芯片。
BIN 文件本身只是数据,因此,你下载 bin 程序文件的时候,必须要设置起始地址
BIN 文件,通过右键属性查看到的文件的大小就是数据的实际大小。而对HEX文件而言,你看到的文件大小并不是实际的数据的大小。
BIN 是 binary 的缩写,直白的翻译即为二进制文件
主要分4段:文件头,编码表,检索表,点阵信息。
文件头结构体
/*针对 height fixed 存储格式*/
typedef struct gui_font_head_height_fixed{
BYTE magic[4]; //'S'('U'or ’M’), 'F', 'L', X---Unicode(or MBCS) Font Library, X: 表示版本号. 分高低4位。如 0x12表示 Ver 1.2 DWORD Size; // 文件大小
BYTE nSection; // 共分几段数据,主要针对 UNICODE 编码有效。 BYTE YSize; // 字体高度
WORD wCpFlag; // codepageflag: bit0~bit13 每个bit分别代表一个CodePage 标志,如果是1,则表示当前CodePage 被选定,否则为非选定。
WORD nTotalChars; // 总的字符数 BYTE ScanMode; // 扫描模式 BYTE bpp; // 位深度
} GUI_FONT_HEAD_HF, *PGUI_FONT_HEAD_HF;
■ HEX文件
HEX文件是用ASCII来表示数据,
1、hex文件包含地址信息而bin文件只包含数据本身,烧写或下载hex文件时,一般不需要用户指定地址,因为hex文件内部已经包含了地址信息。烧写bin文件时则需要用户指定烧录的地址信息。
2、hex文件是用ASCII码来表示二进制的数值。例如8-BIT的二进制数值0x4E,用ASCII来表示就需要分别表示字符‘4’和字符‘E’,每个字符均需要一个字节,因此hex文件至少需要2倍bin文件的空间。
3、hex可以直接转换为bin文件,但是bin文件要转化为hex文件必须要给定一个基地址。
hex 格式文件由 Intel 制定的一种十六进制标准文件格式,是由编译器转换而成的一种用于下载到处理器里面的ASCII文本文件。
HEX文件本身还包括别的附加信息。
HEX文件包含地址信息。在用ISP方式烧写程序时,我们都有这样的经验:1)选择单片机型号;2)选择串口号;3)设置波特率(或者默认);4)选择下载的文件;5)点击下载按钮下载。
HEX文件包含地址信息 hex 则不可修改(文件中包含地址信息):
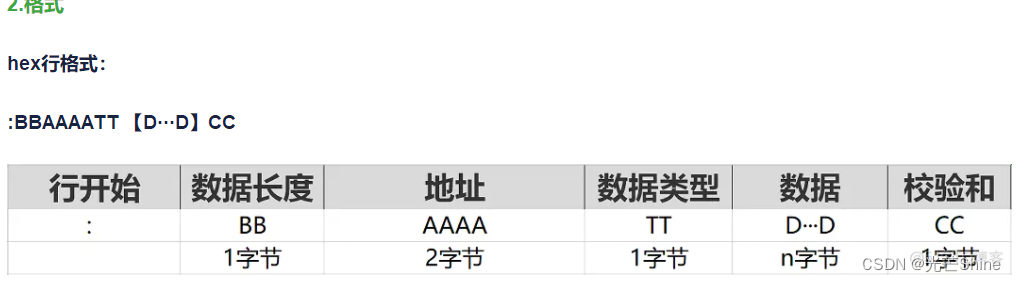
其中:
: 代表行开始,固定为冒号:
BB代表Bytes,数据长度
AAAA代表Address,地址
TT代表Type,数据类型(标识)
D···D代表Date,数据
CC代表CheckSum,校验和
说明:
BB数据长度,也就是D···D这个字段的数据长度;
AAAA地址,起始地址、偏移地址,根据数据类型(TT)有关;
TT数据类型(标识):
00:数据标识
01:文件结束标识
02:扩展段地址
04:线性地址
05:线性开始地址
(地址代表高16位地址,也就是要向左移16bit)
CC校验和计算公式:
CheckSum = 0x100 - (Sum & 0xFF)

■ ELF(Executable and Linkable Format,可执行与可链接格式)
ELF(Executable and Linkable Format,可执行与可链接格式)也算是一种程序文件,这种文件包含信息更多、更复杂。
axf 格式文件是针对ARM编译器的一种格式文件,它是由 ARM 编译器产生。
axf 文件除了包含程序数据(bin)和地址(hex)等数据之外,还包含调试信息。
axf 文件内的调试信息附加在程序文件中,有助于分析和调试。
axf 文件的调试信息作用:
可将源代码包括注释夹在反汇编代码中,这样我们可随时切换到源代码中进行调试。
还可以对程序中的函数调用情况进行跟踪(通过Watch & Call Stack Window查看)。
对变量进行跟踪(利用Watch & Call Stack Window)。
ELF:Executable and Linkable Format,可执行与可链接格式。
elf是一种用于二进制文件、可执行文件、目标代码、共享库和核心转储格式文件。是UNIX系统实验室(USL)作为应用程序二进制接口(Application Binary Interface,ABI)而开发和发布的,也是Linux的主要可执行文件格式。
elf文件和bin、hex、axf文件同样属于可执行文件这一类,但是他们之间差异还是很大,elf文件包含的信息更多,也更复杂。

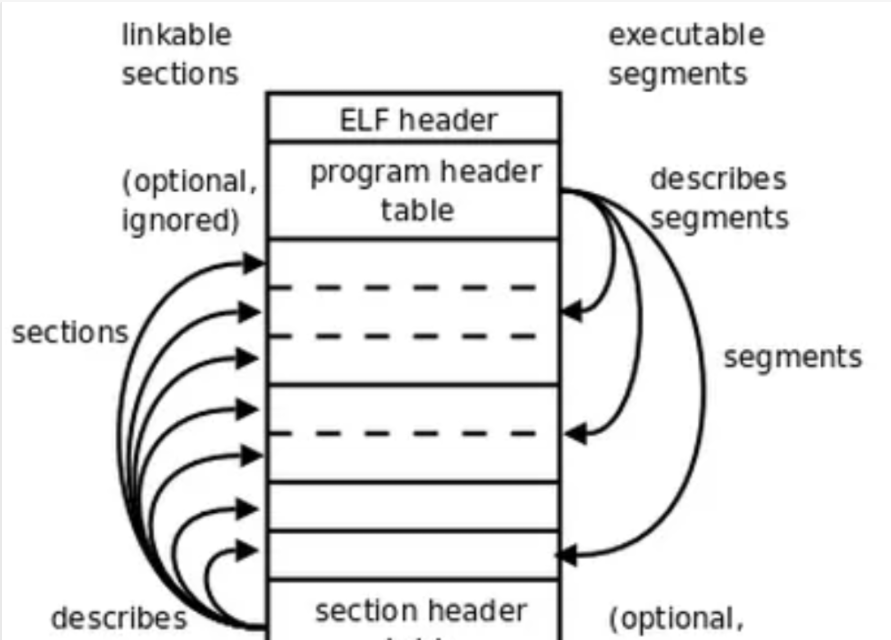
ELF header:描述整个文件的组织。
Program Header Table: 描述文件中的各种segments,用来告诉系统如何创建进程映像的。
Section:是从运行的角度来描述elf文件,sections是从链接的角度来描述elf文件,也就是说,在链接阶段,我们可以忽略program header table来处理此文件,在运行阶段可以忽略section header table来处理此程序(所以很多加固手段删除了section header table)。从图中我们也可以看出,segments与sections是包含的关系,一个segment包含若干个section。
Section Header Table: 包含了文件各个segction的属性信息。
■ 芯片相关数据查找
■ 芯片Flash 起始地址
#define FLASH_BASE_ADDR 0x8000000 // 程序存储区基址
答: 0x8000000 是Flash 起始地址,查芯片手册。
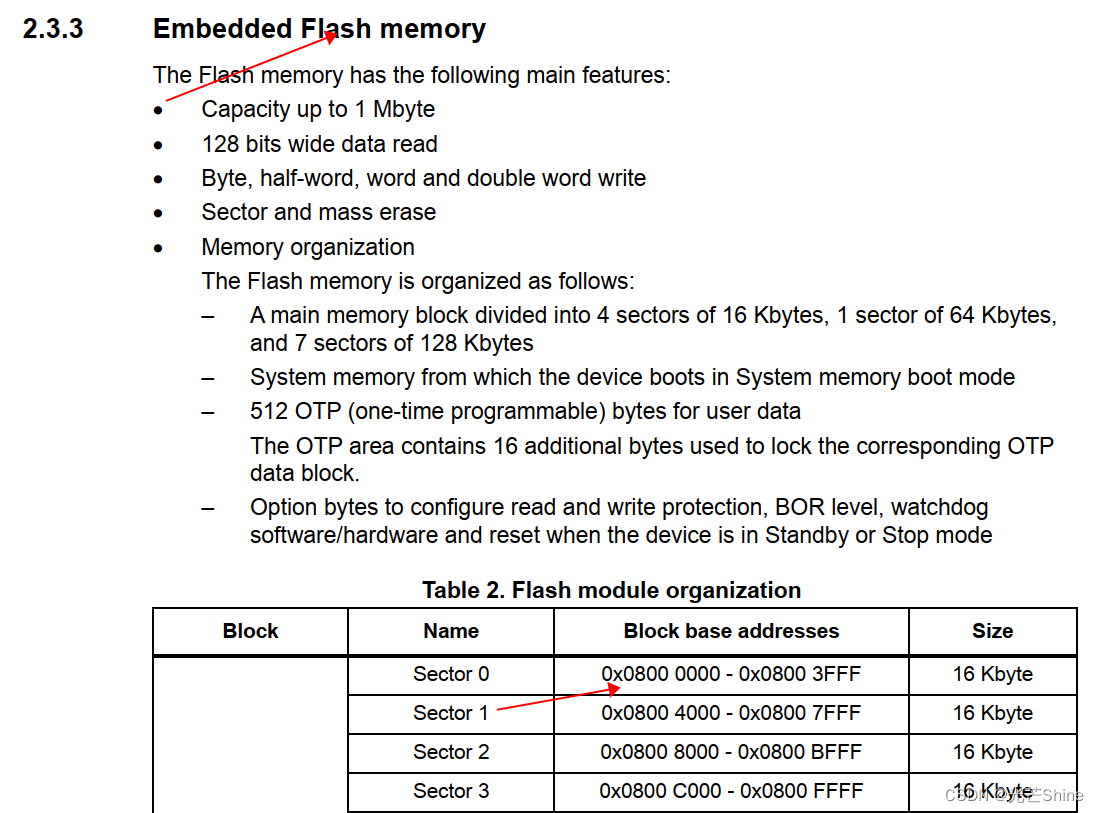
■ FLASH_SECTOR_SIZE 大小
FLASH_SECTOR_SIZE 大小
答:芯片的每个扇区大小都一样,查芯片手册
■ FLASH_EraseSector(u32 startAddr,u32 codeLength)
attribute((section(“.InterruptCode”))) void FLASH_EraseSector(u32 startAddr,u32 codeLength)
答: 这个是芯片示例中有的,不是自己写的擦除芯片Flash代码。
■ STM32F205RBT6Flash大小
STM32F205RBT6Flash大小 R = 64 pins or 66 pins(1) , B = 128 Kbytes of Flash memory
答: 芯片Flash大小为128Kbytes;
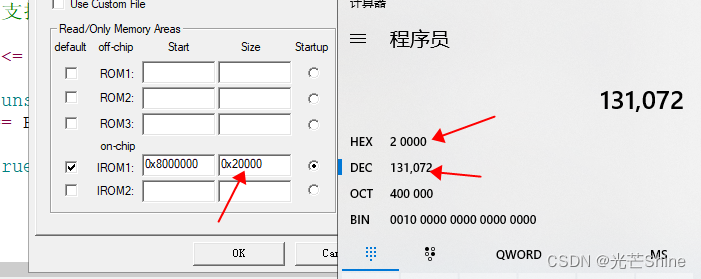
■ IROM1 地址 就是Flash 地址
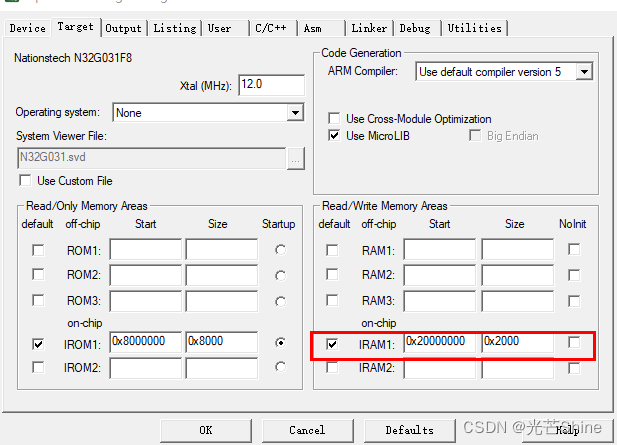
答: IROM1 地址 就是Flash 地址 查看芯片手册。STM32F205RBT6

IROM1地址:是Flash地址 128Kbype 128*1024 = 131072
■ IRAM1 IRAM2地址;
这个地址就是类似电脑DDR内存;
IRAM1 地址在芯片硬件手册里面定义
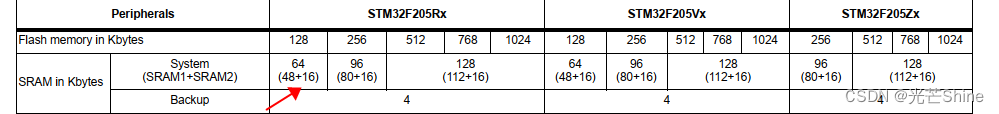
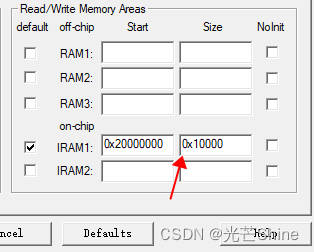
注意点: 有可能修改上图地址大小不一定起效果,还要设置一下sct 文件中的 RW_IRAM1 大小如下:
RW_IRAM1 0x20000000 0x00020000 {
; RW data
.ANY (+RW +ZI)
}
■ IRAM起始地址为啥为0x20000000
■ RAM分段使用
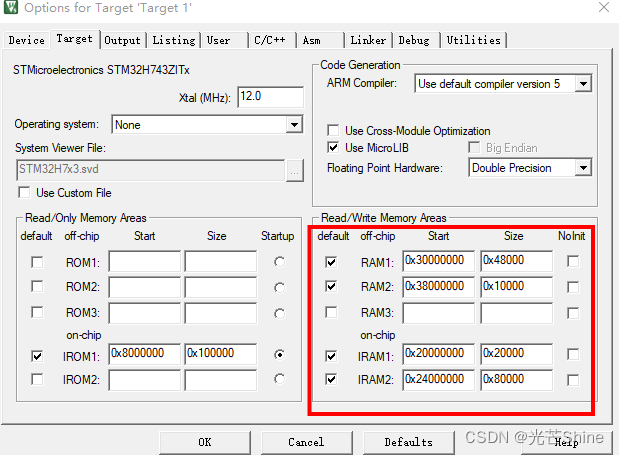
#define DTCM_ADDR (0x20000000)
#define AXISRAM_ADDR (0x24000000)
#define SRAM123_ADDR (0x30000000)
#define SRAM4_ADDR (0x38000000)
#define DTCM_SIZE (0x20000) //128K
#define AXISRAM_SIZE (0x80000) //512K
#define SRAM123_SIZE (0x48000) //288K
#define SRAM4_SIZE (0x10000) //64K
■ Stack_Size Heap_Size
答:堆栈大小,根据程序大小自己设置大小。待补充:

■ 芯片手册分:数据手册(硬件比较关注的),参考手册(软件比较关注的)。
有关性能参数和使用方式的技术资料主要有两类,一类称为数据手册,另一类称为技术参考手册或简称参考手册。
数据手册是有关产品技术特征的基本描述,包含产品的基本配置(如内置Flash和RAM的容量、外设的数量等),
管脚的数量和分配,电气特性,封装信息,和定购代码等。
技术参考手册是有关如何使用该产品的具体信息,包含各个功能模块的内部结构、所有可能的功能描述、
各种工作模式的使用和寄存器配置等详细信息。
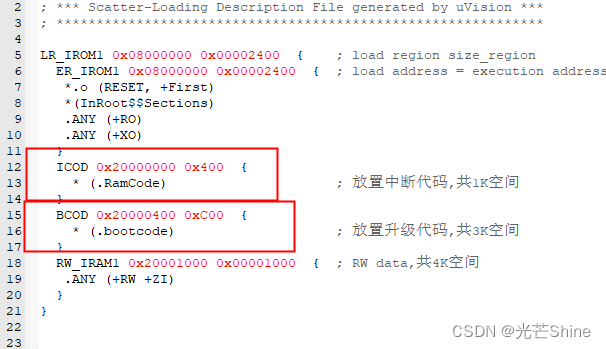
■ sct中(.bootcode) (.RamCode) 意思解析

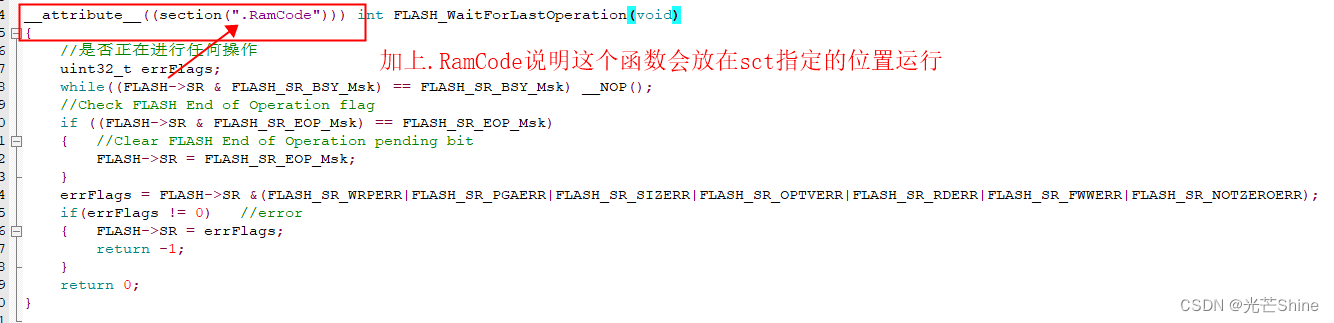
■ Use memory layout from target dialog 选项配合使用的,
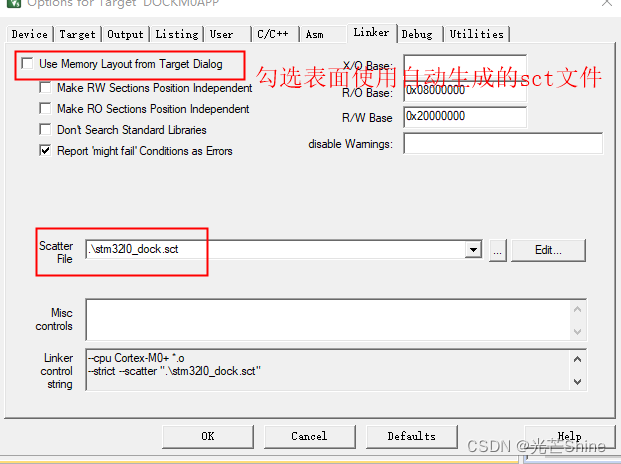
勾选Use memory layout from target dialog 选项配合使用的,就会根据下面的配置生成sct文件

■ _main()函数组成
■ 第一部分: _main():
_main():完成代码和数据的拷贝,并把ZI数据区清零。
代码拷贝可将代码拷贝到另一个映射空间并执行,如
将代码拷贝到RAM执行;数据拷贝完成RW段数据赋值;数据区清零完成ZI段数据赋值。
以上的代码和分散加载文件密切相关。
■ 第二部分:_rt_entry():
_rt_entry():进行STACK和HEAP等的初始化。
最后_rt_entry跳进main()函数入口。
_rt_entry又将控制权交还给调试器。



















 7595
7595

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











