







使用谢菲尔德大学的MATLAB遗传算法工具箱
1.简单一元函数优化:计算函数最小值
f(x) = sin(10*pi*x)/x , x范围[1,2]
clc
clear all
close all
%%画出函数图
figure(1);
hold on;
lb = 1;ub = 2; %函数自变量范围
ezplot('sin(10*pi*X)/X',[lb,ub]); %画出函数曲线
xlabel('自变量/X')
ylabel('函数值/Y')
%%定义遗传算法参数
NIND = 40; %种群大小
MAXGEN = 20; %最大遗传代数
PRECI = 20; %个体长度
GGAP = 0.95; %代沟
px = 0.7; %交叉概率
pm = 0.01; %变异概率
trace = zeros(2,MAXGEN); %寻优结果的初始值
FieldD = [PRECI;lb;ub;1;0;1;1]; %区域描述器
Chrom = crtbp(NIND,PRECI); %创建任意离散随机种群
%%优化
gen = 0; %代计数器
X = bs2rv(Chrom,FieldD); %初始种群的十进制转换
ObjV = sin(10*pi*X)./X; %计算目标函数值
while gen<MAXGEN
FitnV = ranking(ObjV); %分配适应度值
SelCh = select('sus',Chrom,FitnV,GGAP); %选择
SelCh = recombin('xovsp',SelCh,px); %重组
SelCh = mut(SelCh,pm); %变异
X = bs2rv(SelCh,FieldD); %子代个体的十进制转换
ObjVSel = sin(10*pi*X)./X; %计算子代的目标函数值
[Chrom,ObjV] = reins(Chrom,SelCh,1,1,ObjV,ObjVSel);%重插入子代到父代,得到新种群
X = bs2rv(Chrom,FieldD);
gen = gen + 1; %代计数器增加
%获取每代的最优解及其序号,Y为最优解,I为个体的序号
[Y,I] = min(ObjV);
trace(1,gen) = X(I); %记下每代的最优值
trace(2,gen) = Y; %记下每代的最优值
end
plot(trace(1,:),trace(2,:),'bo'); %画出每代的最优值
grid on;
plot(X,ObjV,'b*'); %画出最后一代的种群
hold off
%%画进化图
figure(2);
plot(1:MAXGEN,trace(2,:));
grid on
xlabel('遗传代数')
ylabel('解得变化')
title('进化过程')
bestY = trace(2,end);
bestX = trace(1,end);
fprintf(['最优解:\nX = ',num2str(bestX),'\nY = ',num2str(bestY),'\n'])
2.运行结果:
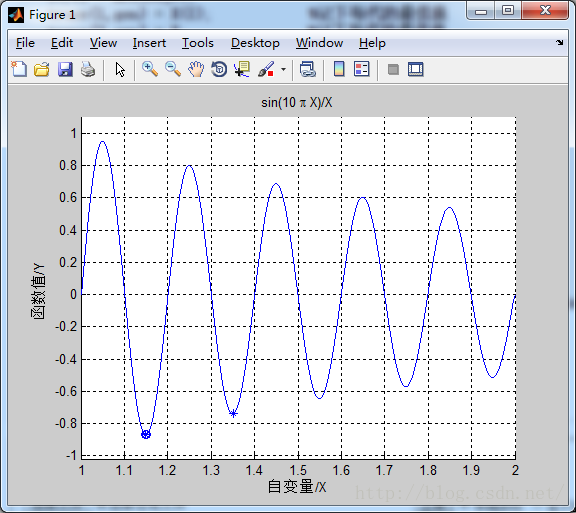
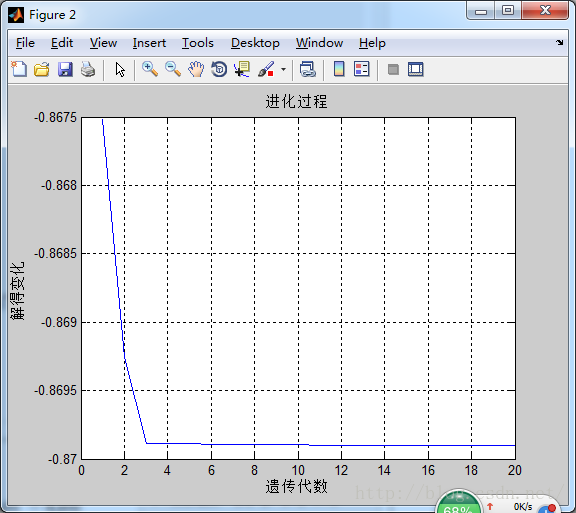

3.疑问:
(1)FieldD区域扫描器:FieldD=[len lb ub code scale lbin ubin]' 是译码矩阵,一般用于二进制串到实值的转换其中len是包含在Chrom中每个字符串的长度,lb和ub是行向量,指明每个变量的下界和上界,code表明如何编码(code=1二进制,code=0格雷),scale指明刻度(scale=0算数,scale=1对数),lbin和ubin表示是否包含边界,0表示去掉,1表示包含
(2)代沟GGAP:代沟是用于控制每代中种群被替换的比例,即每代有N*(1-G)个父代个体被选中进入下一代种群。G=50%意味着一半的种群将被置换。















 4761
4761

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









