







Automa爬取采集元素属性的方法(以采集网址属性href为例)
前面的帖子一直在研究如何采集网页上可见的文本内容,一般都是使用【获取文本】这个功能,后来在爬取谷歌的搜索结果时,需要采集网站的网址,网站的网址在页面中属于链接的属性,使用原来的方法爬取回来的是不精准的数据。
经过摸索发现,有个专门采集网页元素属性的功能,名称就叫做【属性】,使用起来非常方面,特别适合爬取网页链接。

具体做法如下:
1、在流程中加入采集属性的功能框;
2、用Chrome浏览器打开要采集的网页,按F12进入调试模式,在需要采集网址的位置【图中编号1的位置】,选中然后点右键,点检查;

3、在下面看到代码后,在对应的代码位置【图中编号2】的位置,选中有网址的代码段,点右键,选复制,选复制Xpath,得到 Xpath值为: //[@id=“arc-srp_120”]/div/div[4]/div/div/div[1]/div/div/span/a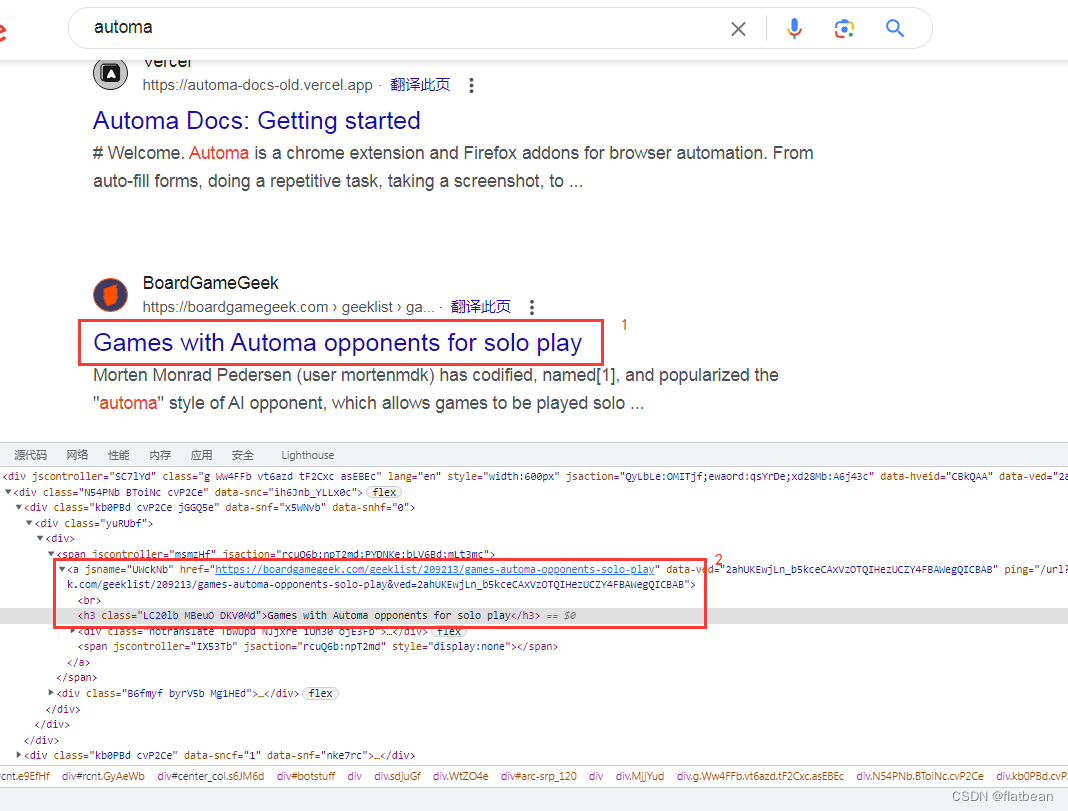
4、接下来,把Xpath中的方括号[]及里面的内容都删掉,变为:
//[@id=“arc-srp_120”]/div/div/div/div/div/div/div/span/a
把这个值放入Xpath选择器下面的文本框【见步骤1】;

5、选中【多选】【等待选择器】【见图中步骤2】
6、在图中步骤3处,写入我们要采集的网址属性值,herf,这个属性是在网页源代码中看到的。

7、在图中步骤4中,为采集到的网址数据指定一个存放的地方,这里我们指定一个表格中的字段weblink来存储采集到的网址。(这个存储的字段是在表格中提前定义好的,表格的定义在下面这个图的位置)

这个问题讲清楚了。















 1780
1780











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









