







 文章介绍了如何在工作流中使用表格组件,类似于Excel,允许用户向列中插入数据。强调了工作流结束后表格数据会被清除,但通过Connecttoastoragetable功能可保存数据至存储表。重点讨论了数据爬取的难点,包括获取文本设置和避免数据存储陷阱。示例展示了工作流的三步过程:打开网页、爬取数据和通知完成。
文章介绍了如何在工作流中使用表格组件,类似于Excel,允许用户向列中插入数据。强调了工作流结束后表格数据会被清除,但通过Connecttoastoragetable功能可保存数据至存储表。重点讨论了数据爬取的难点,包括获取文本设置和避免数据存储陷阱。示例展示了工作流的三步过程:打开网页、爬取数据和通知完成。
前言
终于来到新内容了!!
表格介绍
点击红色标注,出现的窗口就是表格了。
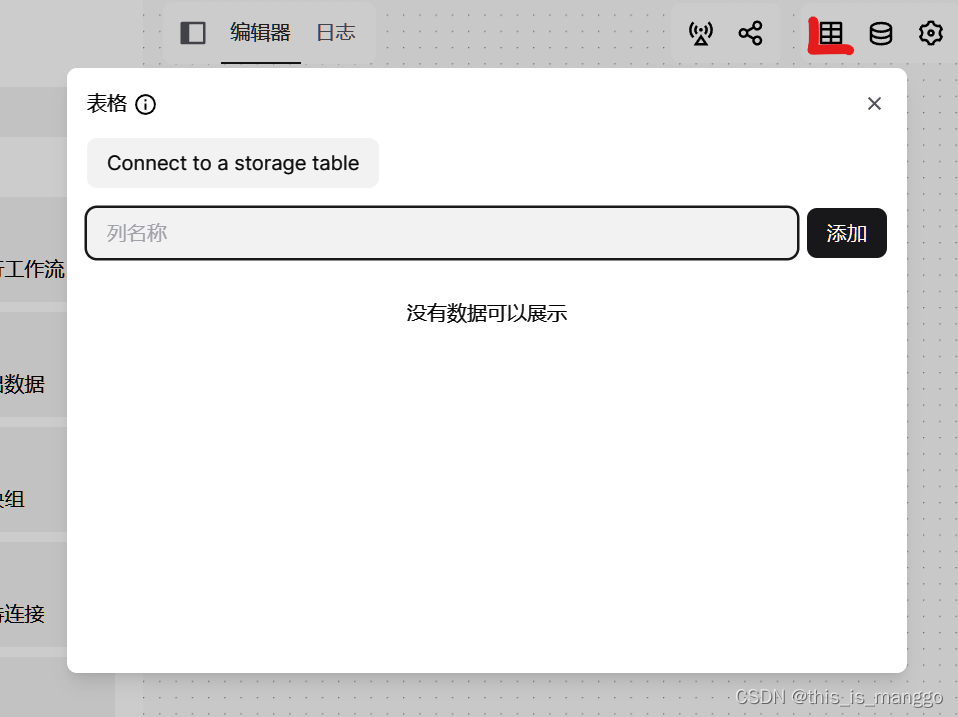
你可以把这部件理解为excel表格,然后你可以使用其他组件往表格中的某一列插入数据。
点击添加可以为这表格的表头添加一个属性。
如果你熟悉数据库的话,这个添加就是往表中添加属性字段。
存储
工作流中的表格存在一定缺点,那就是在工作流结束后,这个表格将会被清空。但请注意Connect to a storage table按钮(上图)。
连接到存储表,它可以将你的数据保存,存储表设置如下图所示。
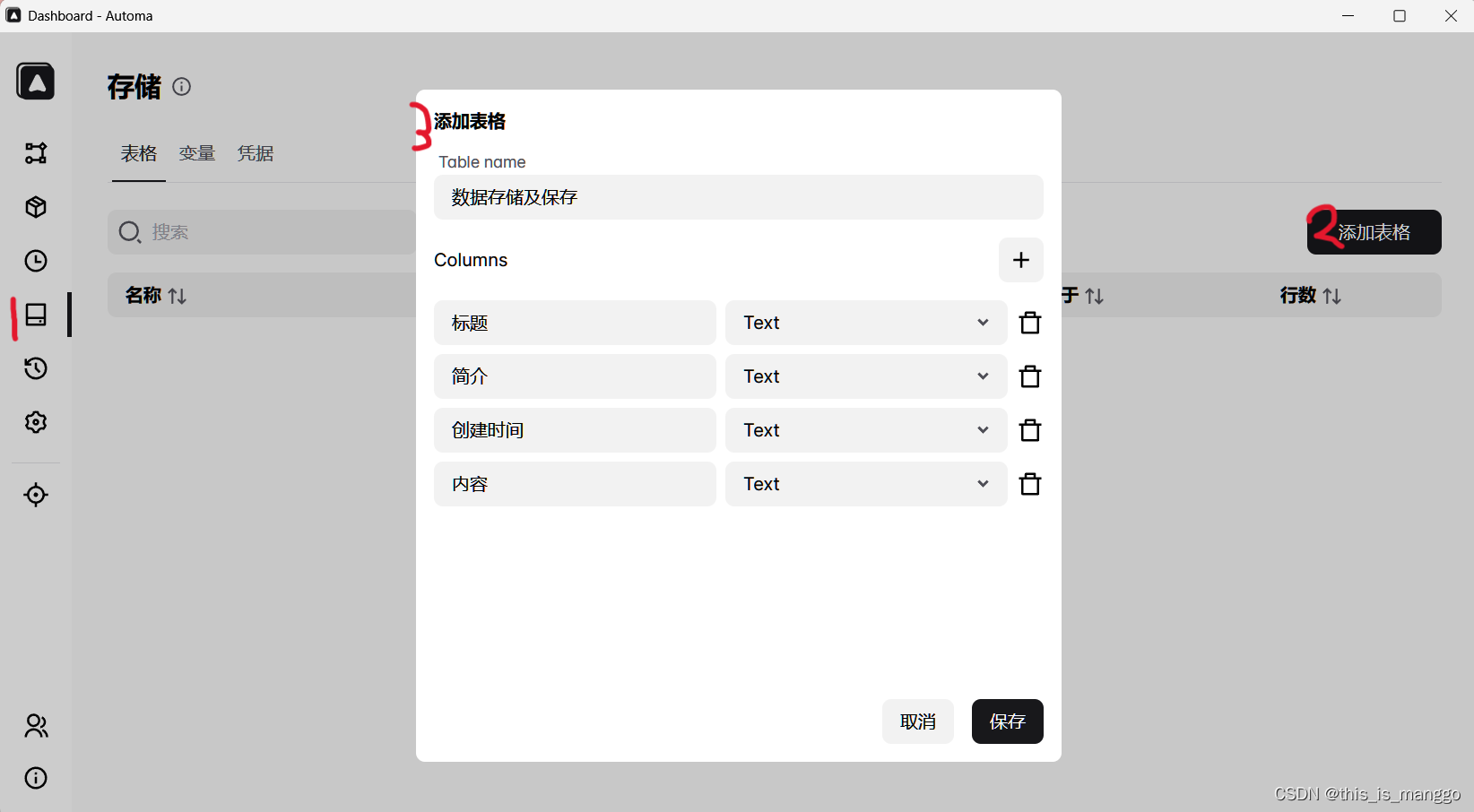
后续介绍都将会以这个表来讲解。
一个小栗子
先看看效果
开头的画面是工作流程和存储表,之后是爬取过程,就打开页面一瞬间的事。

接下来是数据展示
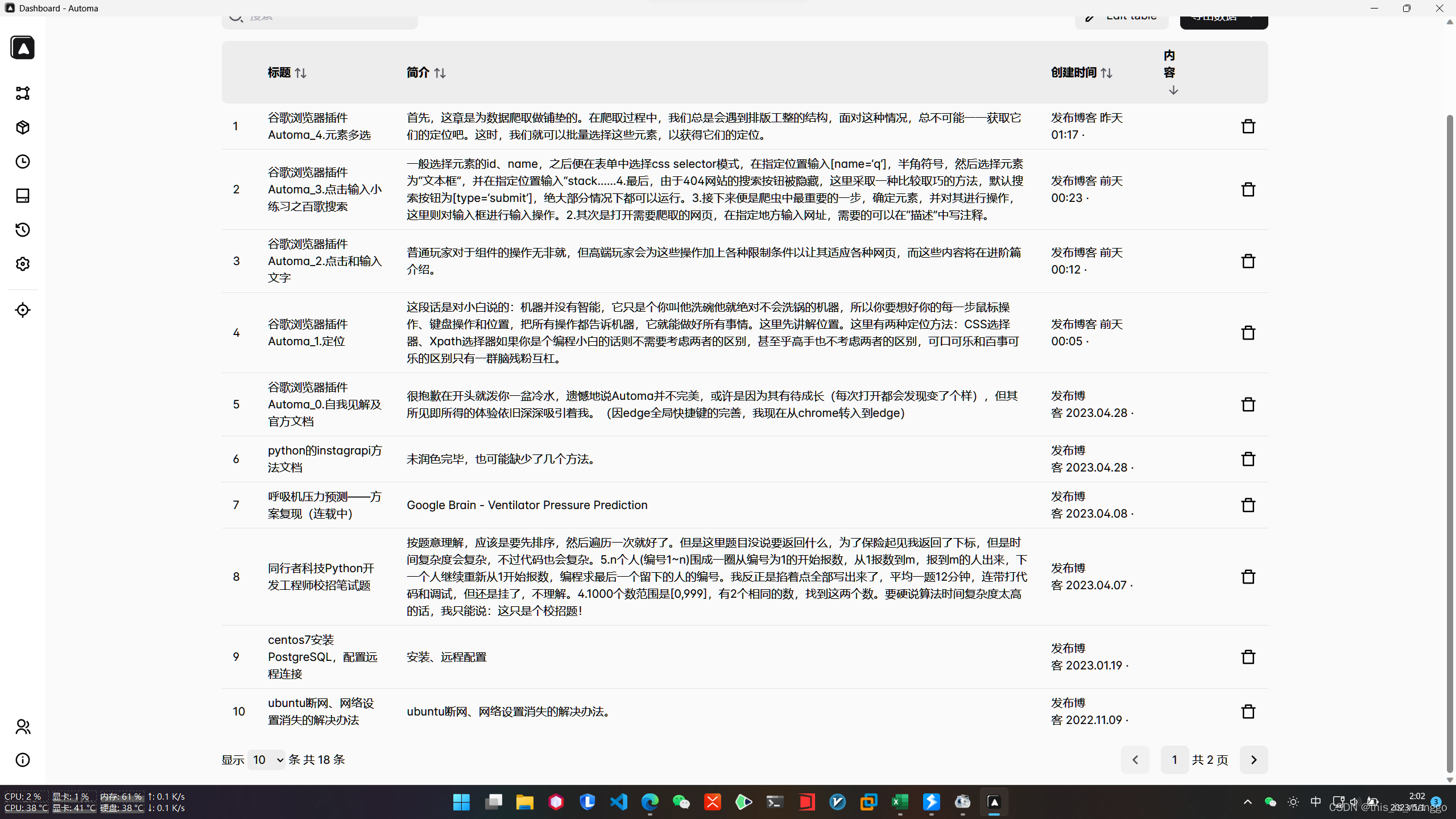
需要数据导出的话就在存储表页面进行导出。
小栗子讲解
首先是工作流展示
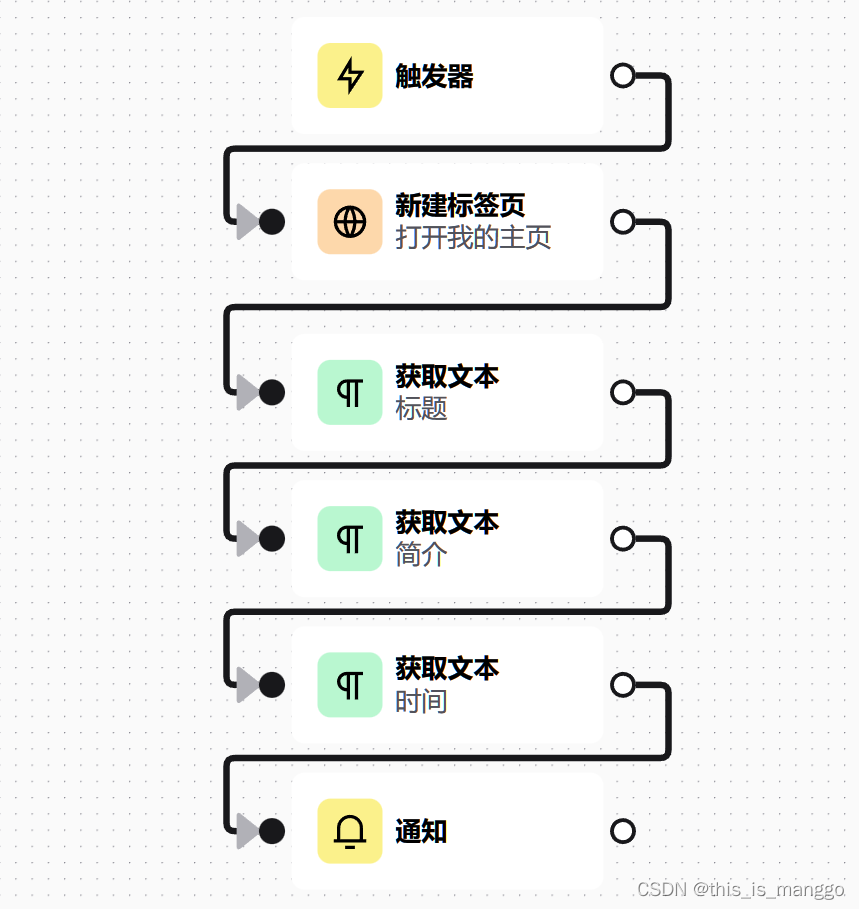
这里其实就三步:
- 打开网页
- 爬取数据
- 通知完成
难点主要集中在数据爬取的部分
难点一:获取文本设置
难点二:数据存储陷阱
(先睡觉,明天再更)

















 2115
2115

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









