










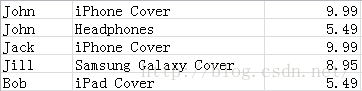
1. 处理如下数据
2. Python代码
#创建两个线程的SparkContext对象,名为 First Spark App
sc = SparkContext("local[2]", "First Spark App")
#读取原始数据并将CSV格式装换为(user, product, price)形式
data = sc.textFile("data/UserPurchaseHistory.csv").map(lambda line: line.split(",")).map(lambda record: (record[0], record[1], record[2]))
#求总共购买次数
numPurchases = data.count()
#求不同客户的人数
uniqueUsers = data.map(lambda record: record[0]).distinct().count()
#求总收入
totalRevenue = data.map(lambda record: float(record[2])).sum()
#求最畅销产品
products = data.map(lambda record: (record[1], 1.0)).reduceByKey(lambda a, b: a+b).collect()
mostPopular = sorted(products, key=lambda x: x[1], reverse=True)[0]
#打印结果
print "Total purchases: %d" % numPurchases
print "Unique users: %d" %uniqueUsers
print "Total revenue: %2.2f" % totalRevenue
print "Most popular product: %s with %d purchases" % (mostPopular[0], mostPopular[1])
1. 运行和结果
1) 将spark解压后的目录设为SPARK_HOME
export SPARK_HOME=~/Software/spark-1.2.0-bin-hadoop2.42) 运行
$SPARK_HOME/bin/spark-submit pythonapp.py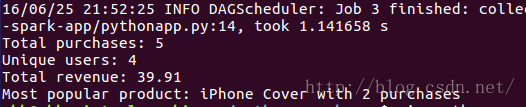















 867
867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









