







论文链接:Image Captioning with Semantic Attention
框架
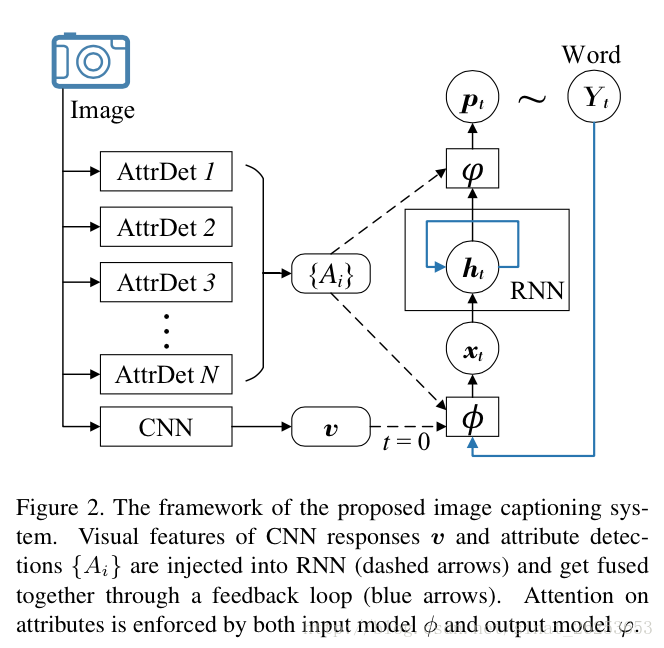
与普通的image Caption框架相比,论文从图片中提取了visual attribute(实际上就是一些单词),并把这些attribute结合进了input跟output attention model里面。
整个框架的公式如下:
x0=ϕ0(v)=Wx,vv x 0 = ϕ 0 ( v ) = W x , v v
ht=RNN(ht−1,xt) h t = R N N ( h t − 1 , x t )
Yt∼pt=φ(ht,{Ai}) Y t ∼ p t = φ ( h t , { A i } )
xt=ϕ(Yt−1,{Ai}), t>0 x t = ϕ ( Y t − 1 , { A i } ) , t > 0
v v : CNN中间层的响应 (global visual description), 只在initial input 中被使用。
{Ai}
{
A
i
}
: a set of visual attributes or concepts
对于这个attributes, 文章提出了三种方法来提取,分别是:
1. 用图像的caption在数据库以最近邻方法查找相近的图片,并选择其标签
2. 使用多标签的分类器
3. 使用全卷积网络(FCN)
而文章重点并不在这里,就不详细介绍了
ϕ,φ ϕ , φ : input and output models
文章把自己的做法和Show Attend and Tell的做法进行了对比,得出了几点主要的区别:
- [2]的attention model由于是从CNN中提取的feature,需要固定的分辨率,而本文的concepts则没有分辨率的限制(attributes 的三种提取方法都不需要固定分辨率),这个concepts甚至也不需要在图片中有直接的展现。
- 本文有一个结合了top-down information (the global visual feature,CNN信息) 和bottom-up concepts(attributes)的feedback过程(个人疑问1:这个feed back体现在哪里?),而[2]并没有这个过程。
- [2]在图片特定的位置使用了pretrained CNN提取出的feature,而本文使用了word feature,因此可以使用外部的图像数据来训练visual concepts,使用文本数据来学习semantics between words。
input attention model
input attention model主要就是计算权重 αit α t i :
αit∝exp(yTt−1U~yi) α t i ∝ e x p ( y t − 1 T U ~ y i )
- exp是指以softmax函数的方式将所有 {Ai} { A i } 进行归一化
- αit α t i : attribute Ai A i 与前一个预测单词 Yt−1 Y t − 1 的相关性
- yt−1, yi y t − 1 , y i : Yt−1 Y t − 1 和 Ai A i 的one-hot representation
-
U~∈R|y|×|y|
U
~
∈
R
|
y
|
×
|
y
|
: 词典大小的矩阵。我认为可以这样理解,这个矩阵存放着每个单词和其他单词之间的相关性,
Yt−1
Y
t
−
1
和
Ai
A
i
这样的one-hot向量对
U~
U
~
相乘就是进行一个查表的操作。这个矩阵因为只跟单词有关,因此同一个单词即使在句子中的不同位置出现,它下一个单词的
αit
α
t
i
都是一样的。对
αit
α
t
i
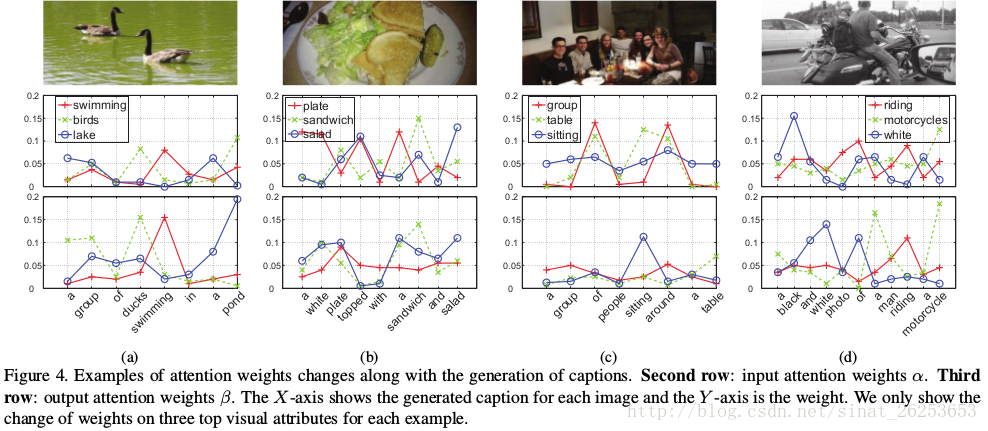
的可视化也验证了这一观点:
图中第二行是 αit α t i 的变化,可以看到,以单词”a”为例,对于出现在句子中不同位置的单词”a”,对应的attribute权重 α α 都是一样的
αit∝exp(yTt−1ETUEyi) α t i ∝ e x p ( y t − 1 T E T U E y i )
- 由于 U~ U ~ 的维度太大,这里加入了word embedding 矩阵 E E 来进行降维。 是以Word2Vec或者Glove来单独训练的,不参与最后的训练
xt=Wx,Y(Eyt−1+diag(wx,A)∑iαitEyi) x t = W x , Y ( E y t − 1 + d i a g ( w x , A ) ∑ i α t i E y i )
- wx,A w x , A 对visual attributes在word space的每个维度的相对重要性进行了建模。个人理解因为 E E 是单独训练的,存在一个不对应的问题,所以要加入
- xt x t 作为模型的输入,这里把直接把attention部分和前一个单词的部分直接相加了,感觉应该用concatenate的方式会好一点?
output attention model
output attention model基本跟前面input attention model类似。
原文对 βit β t i 的解释:
a different set of attention scores are calculated since visual concepts may be attended in different orders during the analysis and synthesis processes of a single sentence.
βit∝exp(hTtVσ(Eyi)) β t i ∝ e x p ( h t T V σ ( E y i ) )
- 由于加入了随时间变化的 hTt h t T ,所以 βit β t i 跟 αit α t i 不一样。在不同位置的同一单词对下一个单词的 βit β t i 是会变化的
- V∈Rn×d V ∈ R n × d :可以理解为V建立了隐状态 ht h t 与单词的embedding之间的相关性
- 因为 ht h t 输出的时候经历了一个非线性变换,因此这里也要加入激活函数 σ σ 来对 Eyi E y i 进行同样的变换
pt∝exp(ETWY,h(ht+diag(wY,A)∑iβitσ(Eyi))) p t ∝ e x p ( E T W Y , h ( h t + d i a g ( w Y , A ) ∑ i β t i σ ( E y i ) ) )
- 最后单词概率分布的输出,基本跟前面一样
loss
minΘA,ΘR−∑tlog p(Yt)+g(α)+g(β) m i n Θ A , Θ R − ∑ t l o g p ( Y t ) + g ( α ) + g ( β )
- 损失函数前面部分和以往的做法一样
- ΘA={U,V,W∗,∗,w∗,∗} Θ A = { U , V , W ∗ , ∗ , w ∗ , ∗ }
- ΘR Θ R : RNN中所有参数
- g(α), g(β) g ( α ) , g ( β ) : {αit} { α t i } 和 {βit} { β t i } 的正则化
g(α)=∥α∥1,p+∥αT∥q,1=[∑i[∑tαit]p]1/p+∑i[∑t(αit)q]1/q g ( α ) = ‖ α ‖ 1 , p + ‖ α T ‖ q , 1 = [ ∑ i [ ∑ t α t i ] p ] 1 / p + ∑ i [ ∑ t ( α t i ) q ] 1 / q
- p > 1 对在整个句子中对一的 Ai A i 的过度attention进行惩罚
- 0 < q < 1 对任意时刻的分散attention进行惩罚
实验
文章是当时state-of-the-art的结果。
作者测试了单独使用input或者output attention的效果,发现只使用一个的话只对模型只有少量的提升,但同时使用则有较大提升,说明两个具有比较强的协同作用。
而对于attributes的提取,作者发现使用FCN的效果是最好的。
对于attributes的使用,除了前面介绍的attention方法ATT,作者还测试了MAX和CON(concatenate),效果都没有ATT好。
总结
文章提出了新的attention模型,结合了top-down和bottom-up的机制,在利用image的overview的同时也利用了丰富的visual semantic aspects。模型的真正威力在于对这些aspects的关注,以及把全局和局部信息利用起来生成更好的captioin。
参考:
https://lisabug.github.io/2016/03/17/image-captioning-with-semantic-attention/















 680
680

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









