







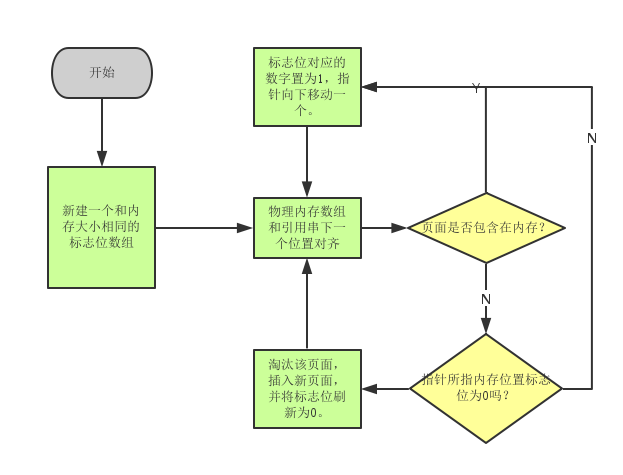
操作系统实验4–页面替换算法
基本数据结构
| 变量名 | 意义 |
|---|---|
| pageNum | 总页面数 |
| rsLen | 引用串长度 |
| frameNum | 物理内存长度 |
| rs[] | 保存引用串的数组 |
| frameArr[] | 保存物理内存的数组 |
| XXModeCounter | XX算法的缺页计数器 |
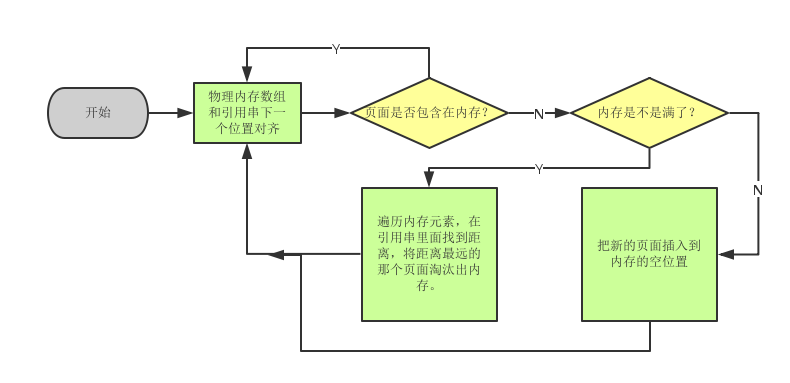
最佳置换算法
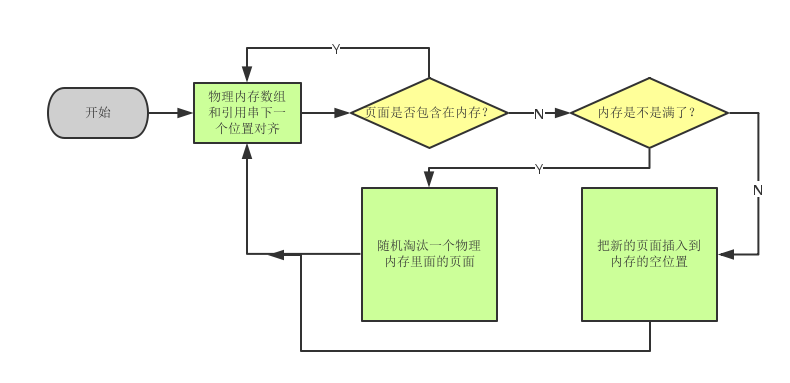
随机置换算法
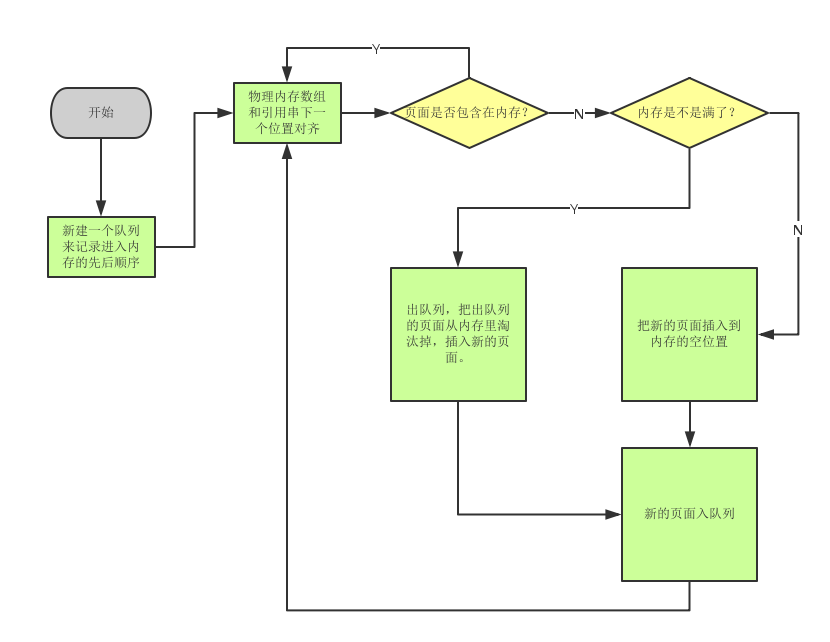
FIFO置换算法
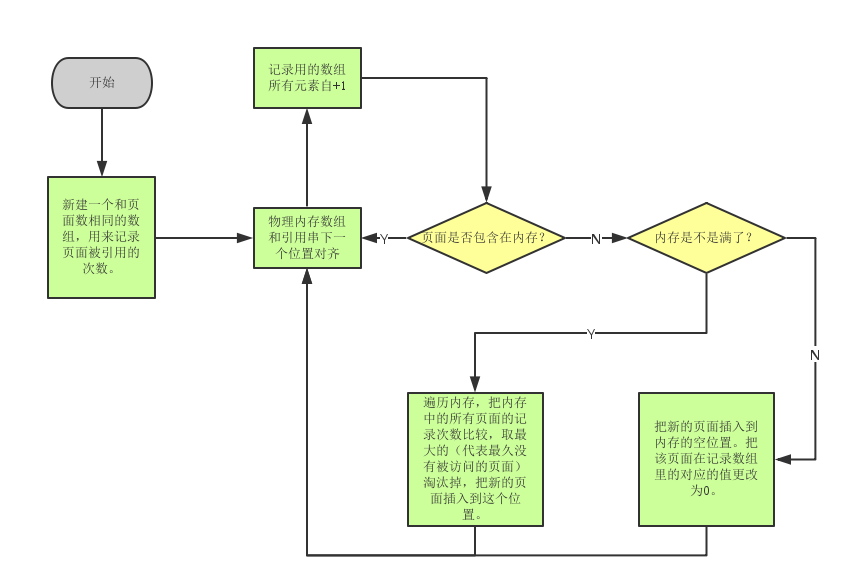
LRU置换算法
Clock置换算法
测试环境
操作系统:Windows 10 - x64
编译器:MinGW
硬件:
CPU:X86构架CPU 2.3 GHz
内存:8GB 1600MHz DDR3
方案详情
基本参数
- 页面总数 pageNum
- 引用串长度 rsLen
- 物理内存大小 frameNum
- 引用串工作集 z
- 引用串移动率 m
- 引用串不稳定率 e
参考参数
这些参数的意义就是作为参考,在围绕这些参数进行倍增,看看各个参数变化对缺页率的影响是怎样的。
- pageNum = 100
- rsLen = 10000
- frameLen = 20
- z = 5
- m = 10
- e = 0.2
随机数生成方案
因为随机数如果用时间函数作为种子就会发生1秒内的所有测试都是一样的结果,这样子在短时间内获得较多的结果不太可能,所以我就使用了时间函数作为初始种子,在每一次实验过程中都自加一,保证了引用串生成的随机性。
测试数据
每组参数测试100组数据,这个测试次数也可以调到更大,如果时间充足,可以测试更多组数据,但为了把测试数据的时间缩短到总共5分钟,所以我大概估计了一下选择了100。
每组数据用时比我预想的要久,可能是因为我的最佳置换算法每次缺页都要比较距离,如果用一个数组把所有下一个页面出现的位置都保存起来会少很多工作。但因为数据结构太复杂了,我调试了好多次都失败了,所以就用了比较简单直接的方法。
每组参数都保存在不同的output_.csv文件中,每个文件包含100组数据。这些数据分别记录了每种算法的替换率,从左到右各列表示最佳置换算法、随机置换算法、FIFO置换算法、LRU置换算法、Clock置换算法。
下面是各组参数对应的原始数据文件:
| 数据文件名 | pageNum | rsLen | frameNum | z | m | e |
|---|---|---|---|---|---|---|
| output1.csv | 100 | 10000 | 20 | 5 | 10 | 0.2 |
| output2.csv | 500 | 10000 | 20 | 5 | 10 | 0.2 |
| output3.csv | 1000 | 10000 | 20 | 5 | 10 | 0.2 |
| output4.csv | 100 | 50000 | 20 | 5 | 10 | 0.2 |
| output5.csv | 100 | 100000 | 20 | 5 | 10 | 0.2 |
| output6.csv | 100 | 10000 | 50 | 5 | 10 | 0.2 |
| output7.csv | 100 | 10000 | 80 | 5 | 10 | 0.2 |
| output8.csv | 100 | 10000 | 20 | 5 | 10 | 0.5 |
| output9.csv | 100 | 10000 | 20 | 5 | 10 | 0.8 |
| output10.csv | 100 | 10000 | 20 | 5 | 50 | 0.2 |
| output11.csv | 100 | 10000 | 20 | 5 | 80 | 0.2 |
| output12.csv | 100 | 10000 | 20 | 10 | 10 | 0.2 |
| output13.csv | 100 | 10000 | 20 | 15 | 10 | 0.2 |
比较参考参数下各个置换算法的替换率
对数据文件output1.csv进行求平均值运算,得到各个算法的平均替换率。
| 数据文件名 | Best | Random | FIFO | LRU | CLOCK |
|---|---|---|---|---|---|
| output1.csv | 0.099187 | 0.164114 | 0.147767 | 0.146462 | 0.298836 |
可以看到在参数为参考参数的时候:
FIFO算法比随机置换算法小幅优越,优越了2%左右。LRU算法和FIFO算法基本相当,前者优越了后者不到1%。LRU算法和最佳置换算法差距明显,后者大幅优越于前者,大概优越了有接近20%。事实上最佳置换算法大幅领先以上任何其他算法,因为这个算法是在确定引用串的情况下才能使用的,实际中基本无法实现。但我分析,在能估计到应用程序对于资源的请求顺序及情况的时候,定制一套接近于最佳置换算法的置换算法也是可能的,比如说某些固定几种操作的小型嵌入式系统。Clock算法比LRU算法的差了一倍,性能甚至不如最简单的FIFO算法。
总页面数PageNum变化对算法替换率的影响
对数据文件output1.csv``output2.csv``output3.csv分别求平均值,得到各个算法的平均替换率。
|BEST|RANDOM|FIFO|LRU|CLOCK|
|—|—|—|—|—|
0.099187|0.164114|0.147767|0.146462|0.298836|
0.141501|0.190631|0.168871|0.168571|0.360583|
0.151291|0.19409|0.171659|0.171526|0.369229|
绘制图表。
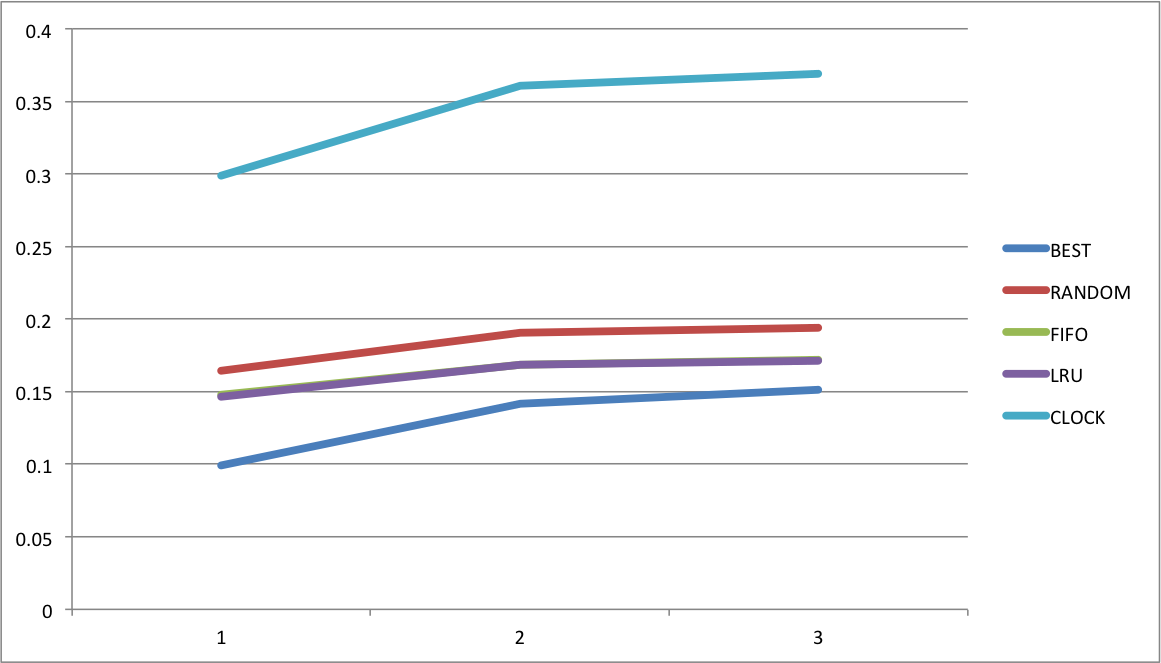
可以看到,随着总页面数的上升,各个算法的替换率都开始上升,因为引用页面更为的复杂了。
引用串长度RsLen变化对算法替换率的影响
对数据文件output1.csv``output4.csv``output5.csv分别求平均值,得到各个算法的平均替换率。
|BEST|RANDOM|FIFO|LRU|CLOCK|
|—|—|—|—|—|
0.099187|0.164114|0.147767|0.146462|0.298836|
0.0996878|0.1648296|0.147628|0.1463678|0.2995668
0.0997916|0.164583|0.1476042|0.1463869|0.2999914
绘制图表。
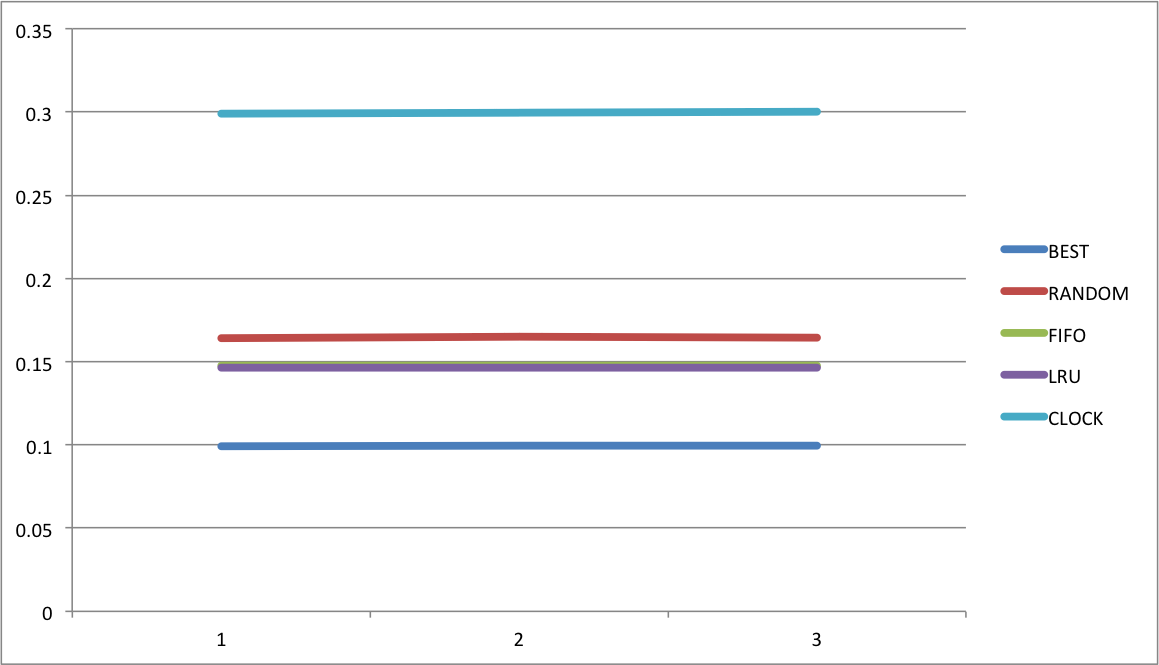
可以看到,引用串长度变化对算法替换率没有影响。
物理内存大小FrameNum变化对算法替换率的影响
对数据文件output1.csv``output6.csv``output7.csv分别求平均值,得到各个算法的平均替换率。
| BEST | RANDOM | FIFO | LRU | CLOCK |
|---|---|---|---|---|
| 0.099187 | 0.164114 | 0.147767 | 0.146462 | 0.298836 |
| 0.042269 | 0.097264 | 0.095484 | 0.094599 | 0.17822 |
| 0.01178 | 0.042507 | 0.044304 | 0.044083 | 0.076999 |
绘制图表。
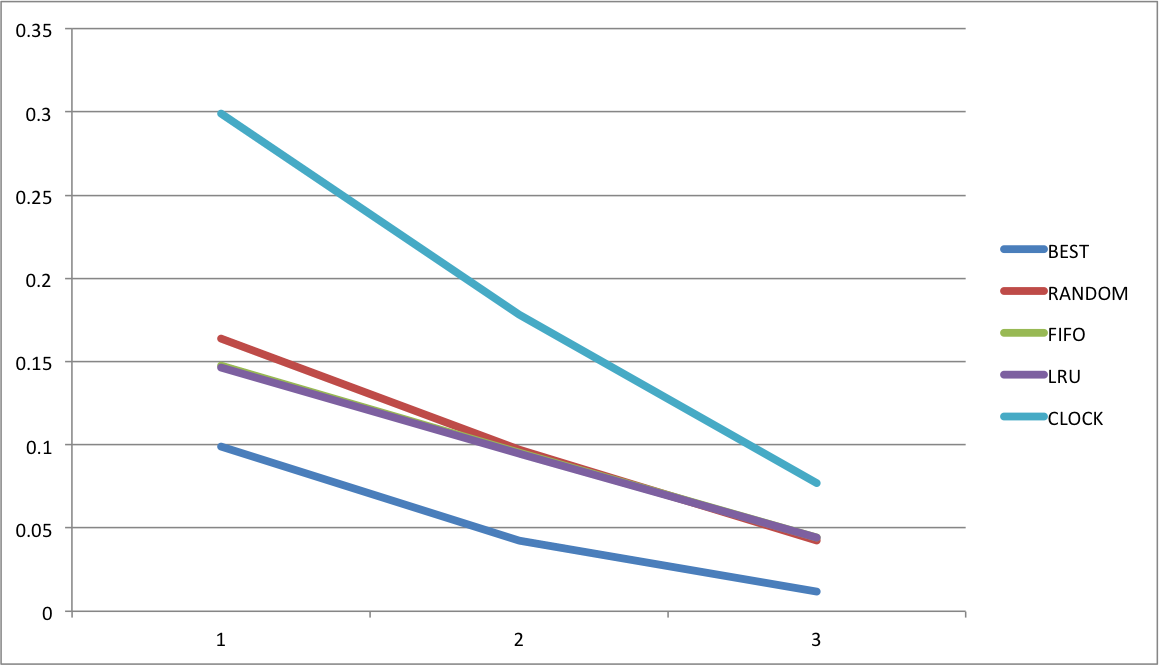
可以看到,物理内存越大,各个算法的替换率越低,说明大的物理内存可以显著提升资源利用率。并且可以看到随机置换算法和LRU算法在越大的内存中替换率越接近。
引用串不稳定率e变化对算法替换率的影响
对数据文件output1.csv``output8.csv``output9.csv分别求平均值,得到各个算法的平均替换率。
| BEST | RANDOM | FIFO | LRU | CLOCK |
|---|---|---|---|---|
| 0.099187 | 0.164114 | 0.147767 | 0.146462 | 0.298836 |
| 0.150565 | 0.249996 | 0.231385 | 0.228987 | 0.432876 |
| 0.200792 | 0.329786 | 0.313261 | 0.31067 | 0.524086 |
绘制图表。
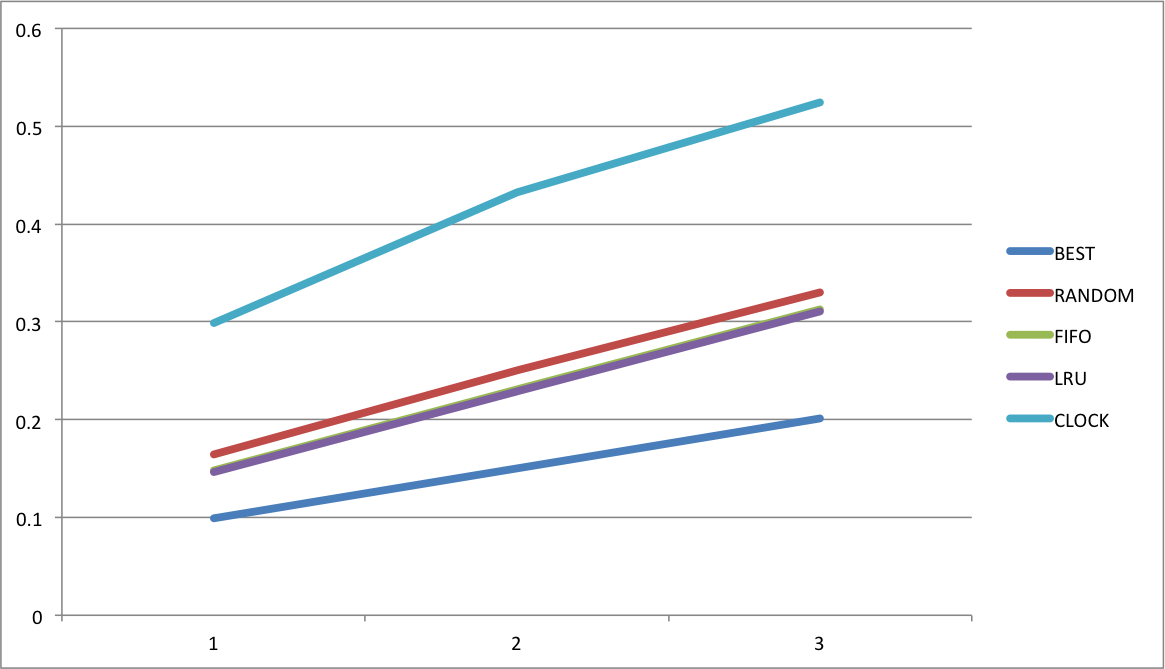
可以看到,引用串越不稳定的取值,各个算法的替换率越高,说明如果不集中使用某一些页面,那么这些算法的效率会降低。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5563
5563











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









