







笔者寄语:与前面的RsowballC分词不同的地方在于这是一个中文的分词包,简单易懂,分词是一个非常重要的步骤,可以通过一些字典,进行特定分词。大致分析步骤如下:
数据导入——选择分词字典——分词
但是下载步骤比较繁琐,可参考之前的博客: R语言·文本挖掘︱Rwordseg/rJava两包的安装(安到吐血)
——————————————————————————————————
Rwordseg与jiebaR分词之间的区别
中文分词比较有名的包非`Rwordseg`和`jieba`莫属,他们采用的算法大同小异,这里不再赘述,我主要讲一讲他们的另外一个小的不同:
`Rwordseg`在分词之前会去掉文本中所有的符号,这样就会造成原本分开的句子前后相连,本来是分开的两个字也许连在一起就是一个词了,
而`jieba`分词包不会去掉任何符号,而且返回的结果里面也会有符号。
所以在小文本准确性上可能`Rwordseg`就会有“可以忽视”的误差,但是文本挖掘都是大规模的文本处理,由此造成的差异又能掀起多大的涟漪,与其分词后要整理去除各种符号,倒不如提前把符号去掉了,所以我们才选择了`Rwordseg`。
来看一下这篇论文一些中文分词工具的性能比较《开源中文分词器的比较研究_黄翼彪,2013》
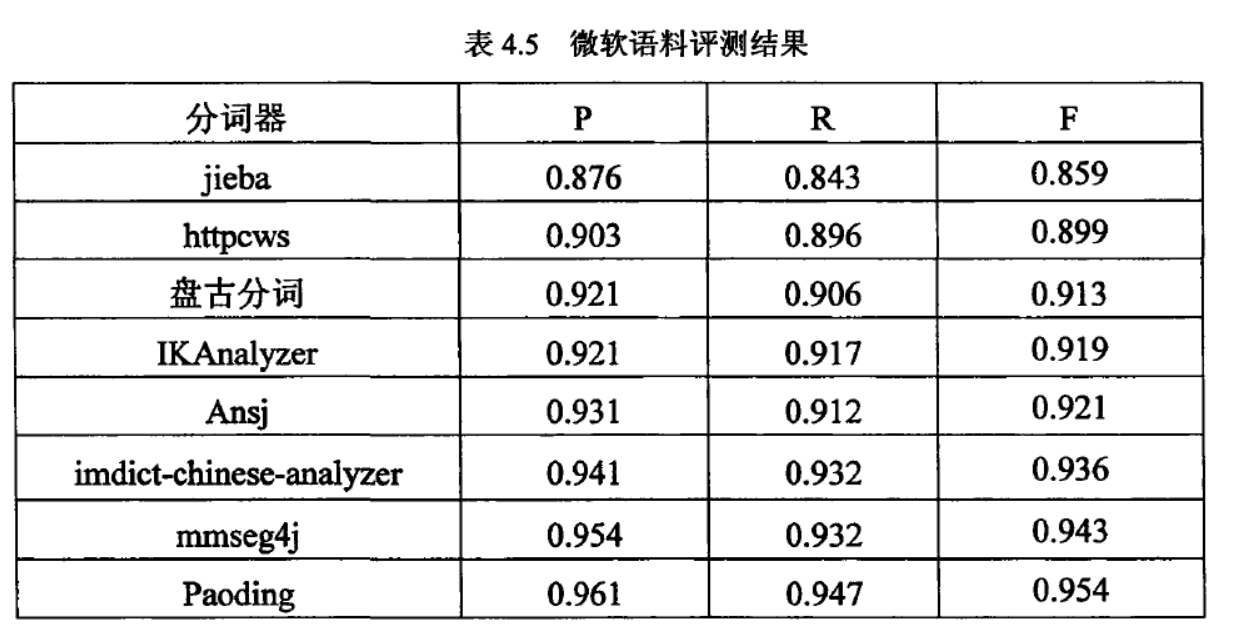
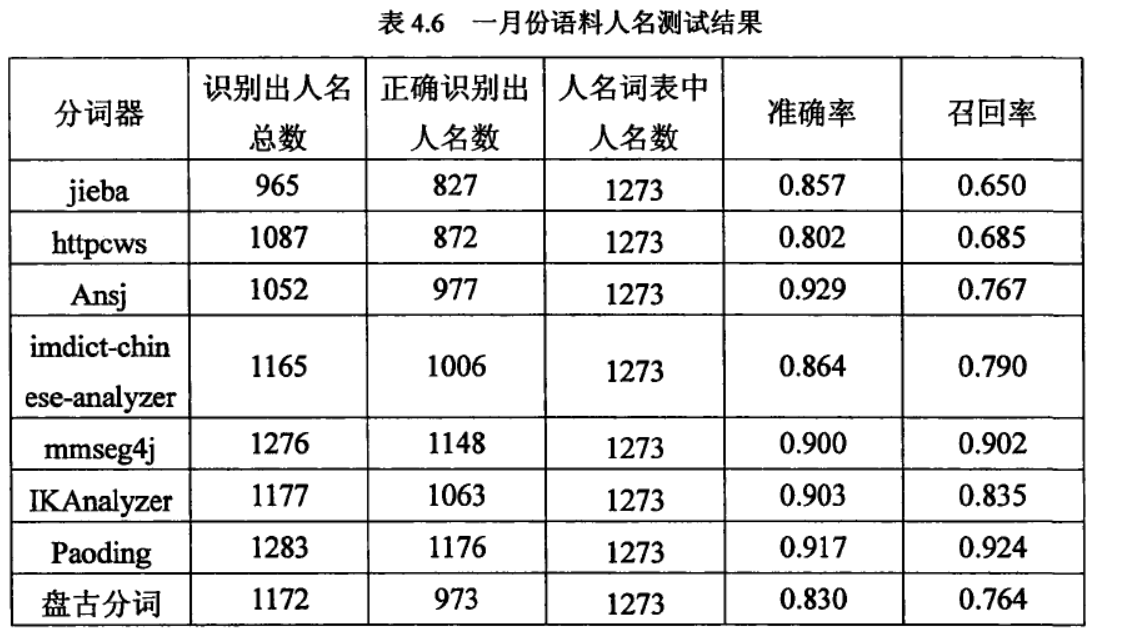
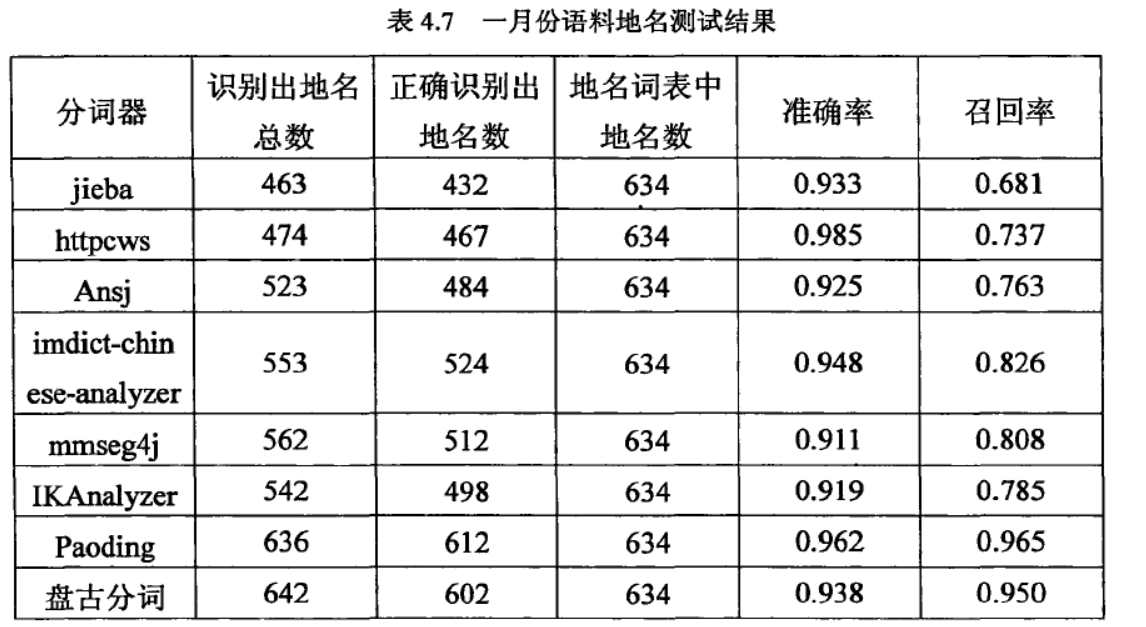
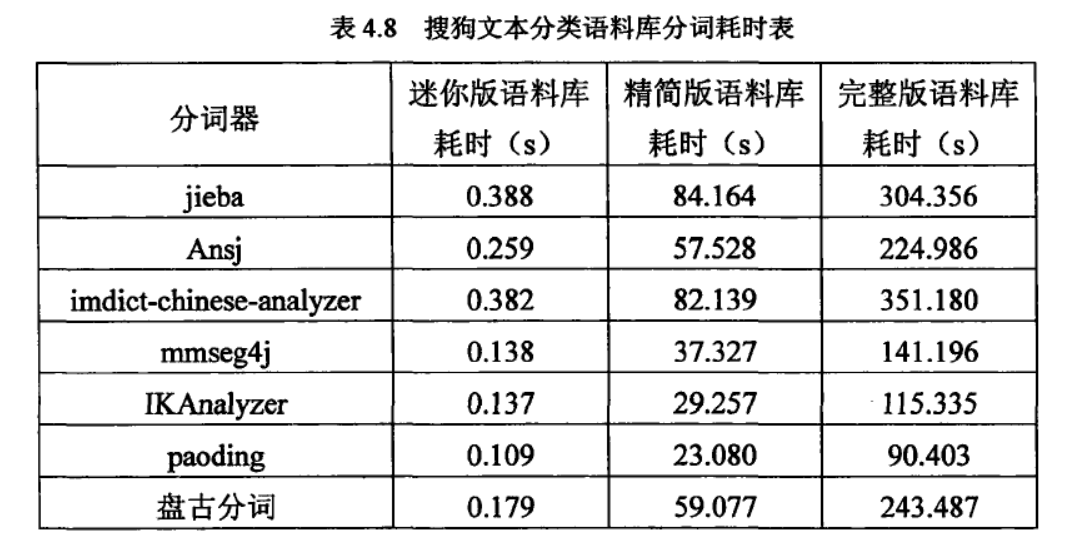
8款中文分词器的综合性能排名:
Paoding(准确率、分词速度、新词识别等,最棒)
mmseg4j(切分速度、准确率较高)
IKAnalyzer
Imdict-chinese-analyzer
Ansj
盘古分词
Httpcws
jieba
——————————————————————————————————
Rwordseg分词原理以及功能详情
Rwordseg 是一个R环境下的中文分词工具,使用 rJava 调用 Java 分词工具 Ansj。
Ansj 也是一个开源的 Java 中文分词工具,基于中科院的 ictclas 中文分词算法, 采用隐马尔科夫模型(Hidden Markov Model, HMM)。作者孙健重写了一个Java版本, 并且全部开源,使得 Ansi 可用于人名识别、地名识别、组织机构名识别、多级词性标注、 关键词提取、指纹提取等领域,支持行业词典、 用户自定义词典。
1、分词原理
n-Gram+CRF+HMM的中文分词的java实现.
分词速度达到每秒钟大约200万字左右(mac air下测试),准确率能达到96%以上
目前实现了.中文分词. 中文姓名识别 . 用户自定义词典,关键字提取,自动摘要,关键字标记等功能
可以应用到自然语言处理等方面,适用于对分词效果要求高的各种项目.
(官方说明文档来源:http://pan.baidu.com/s/1sj5Edjf)该算法实现分词有以下几个步骤:
1、 全切分,原子切分;
2、 N最短路径的粗切分,根据隐马尔科夫模型和viterbi算法,达到最优路径的规划;
3、人名识别;
4、 系统词典补充;5、 用户自定义词典的补充;
6、 词性标注(可选)
2、Ansj分词的准确率
这是我采用人民日报1998年1月语料库的一个测试结果,首先要说明的是这份人工标注的语料库本身就有错误。
- P(准确率):0.984887218571267
- R(召回率):0.9626488103178712
- F(综合指标F值):0.9736410471396494
3、歧义词、未登录词的表现
歧异方面的处理方式自我感觉还可以,基于“最佳实践规则+统计”的方式,虽然还有一部分歧异无法识别,但是已经完全能满足工程应用了。
至于未登录词的识别,目前重点做了中文人名的识别,效果还算满意,识别方式用的“字体+前后监督”的方式,也算是目前我所知道的效果最好的一种识别方式了。
4、算法效率
在我的测试中,Ansj的效率已经远超ictclas的其他开源实现版本。
核心词典利用双数组规划,每秒钟能达到千万级别的粗分。在我的MacBookAir上面,分词速度大约在300w/字/秒,在酷睿i5+4G内存组装机器上,更是达到了400w+/字/秒的速度。
参考文献:
Rwordseg说明:http://jianl.org/cn/R/Rwordseg.html
ansj中文分词github:https://github.com/NLPchina/ansj_seg
ansj中文分词作者专访:http://blog.csdn.net/blogdevteam/article/details/8148451
——————————————————————————————————
一、数据导入、函数测试
本次使用代码与案例是基于北门吹风博客而来。
#导入rJava 和Rwordseg
library(rJava)
library(Rwordseg)
#测试rJava 和Rwordseg是否安装好
teststring1 <- "我爱R语言,我爱文本挖掘"
segmentCN(teststring1) ##Rwordseg中的函数,中文分词
#观察分词1000次花的时间
system.time(for(i in 1:1000) segmentCN(teststring1))
#segmentCN的详细解释
?segmentCN二、分词词典的使用
笔者认为选择分词词典对于后续的分析极为重要,词典库是之后分词的匹配库,这个词库越强大,分词的效果就越好。网上大多使用的是搜狗分词包。
1、从搜狗词库下载分词词典
##用搜狗词库的时候 一定要在官网上下载 ~.scel 文件,
##搜狗下载官网:http://pinyin.sogou.com/dict/cate/index/101
#不能直接将 下载的 ~.txt改为~.scel
installDict("F:/R/文本挖掘分词词库/自然语言处理及计算语言学相关术语.scel","computer",dicttype = "scel")2、查看词典的函数
加载词典函数为installDict,下面有一些简单的介绍,其中的词类名称是自定义的,每个词类名称需要不一样。
#查看词典
#installDict函数介绍
# installDict(dictpath, dictname,dicttype = c("text", "scel"), load = TRUE)
#installDict("工作目录","词类名称",dicttype = c("text", "scel"), load = TRUE)listDict()
#uninstallDict() 删除安装的词典
uninstallDict()
#listDict() 查看剩余的词典
listDict()
分别有查看、安装、删除的函数。
3、自定义词典
可以自己设定哪些关键词需要额外注意区分开来,也可以删除已经加入词库的一些关键词,
对于一些专业领域,专业名词较多的案例,很推荐。
#自定义词典
#手动添加或删除词汇,仅仅只在内存中临时添加,未记录下来
segmentCN("画角声断谯门")
insertWords("谯门") #让某词组放入内存
segmentCN("画角声断谯门")
deleteWords(c("谯门","画角")) #删除某词组
segmentCN("画角声断谯门")
#使用save参数,把操作记录下来,下回启动能直接用
insertWords(c("谯门","画角"),save=TRUE)
segmentCN("画角声断谯门")三、分词
1、Rwordseg分词包核心函数segmentCN
Rwordseg分词包主要函数是segmentCN,这个函数是核心,笔者详解一下这个函数,代码如下:
#segmentCN函数解释
segmentCN(strwords,
analyzer = get("Analyzer", envir = .RwordsegEnv),
nature = FALSE, nosymbol = TRUE,
returnType = c("vector", "tm"), isfast = FALSE,
outfile = "", blocklines = 1000)
#strwords:中文句子
#analyzer:分析的java对象
#nature:是否识别词组的词性(动词、形容词)
#nosymbol:是否保留句子符号
#returnType:默认是一个字符串,也可以保存成其他的样式,比如tm格式,以供tm包分析
#isfast:“否”代表划分成一个个字符,“是”代表保留句子,只是断句
#outfile:如果输入是一个文件,文件的路径是啥
#blocklines:一行的最大读入字符数分词时候的原则是,如果该词是默认词典里面的,那么优先分词出来。那么你insert以及词典加入的词语,都不会被分出来,而且按照默认词典分。
如何有一个新词,容易被拆开了分,那么怎么办?
目前还没有特别棒的方法,不过你在insert时候,可以把出现频次提高,这样好像可以提高优先级。
至于Rwordseg默认词典,在哪呢?
2、关于人名的分词
#参数isNameRecognition 可用来人的名字识别,
getOption("isNameRecognition") #默认是不进行人名识别,输出false
segmentCN("梅超风不是是桃花岛岛主")
segment.options(isNameRecognition = TRUE)
getOption("isNameRecognition")
segmentCN("梅超风是桃花岛岛主")

除了人名之外,rwordseg还有两类识别:
2、数字识别(isNumRecognition ,默认为TRUE,默认识别数字);
3、量词识别(isQuantifierRecognition,默认为TRUE,默认识别量词)。
————————————————————
延伸一:python中的模块——pynlpir
import pynlpir
pynlpir.open()
s = '欢迎科研人员、技术工程师、企事业单位与个人参与NLPIR平台的建设工作。'
pynlpir.segment(s)
[('欢迎', 'verb'), ('科研', 'noun'), ('人员', 'noun'), ('、', 'punctuation mark'), ('技术', 'noun'), ('工程师', 'noun'), ('、', 'punctuation mark'), ('企事业', 'noun'), ('单位', 'noun'), ('与', 'conjunction'), ('个人', 'noun'), ('参与', 'verb'), ('NLPIR', 'noun'), ('平台', 'noun'), ('的', 'particle'), ('建设', 'verb'), ('工作', 'verb'), ('。', 'punctuation mark')]














 1588
1588

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









