







本人录制技术视频地址:https://edu.csdn.net/lecturer/1899 欢迎观看。
查找是指从一组记录集合中找出满足给定条件的记录。今天给大家介绍三种基本的查找算法: 顺序查找、折半查找和索引查找。
一、顺序查找
基本思想:
从查找表的一端开始,逐个将记录的关键字和给定的值进行比较,如果某个记录的关键字和给定值相等,则称查找成功;否则说明查找表中不存在关键值为给定值的记录,则称查找失败。
代码清单:
int sequenceSearch(int *a, int length, int k) {
for (int i = 0; i < length; i++) {
if (k == a[i]) {
return i;
}
}
return -1;
}参数说明:
a: 表示给定的记录集合。
length: 表示给定记录集合的个数。
k: 表示给定值。
结论分析:
顺序查找的优点是算法简单,且对表的结构没有任何要求。它的缺点就是查询效率低,因此,当表中元素个数比较多时,不宜采用顺序查找。
二、折半查找(二分查找)
前提条件:
1. 要求查找表中的记录按关键字有序排列。
2. 只能适用于顺序存储结构。
基本思想:
先取查找表的中间位置的关键字与给定值作比较,若他们的值相等,则查找成功;如果给定值比该记录的关键字值大,说明要查找的记录一定在查找表的后半部分,则在查找表的后半分继续使用遮半查找;反之,在查找表的前半部分使用折半查找....... 直到查找成功,或者直到确定查找表中没有待查找的记录为止,即查找失败。
流程图演示:

代码清单:
int binSearch(int *a, int length, int k) {
int low = 0, high = length - 1, mid = 0, find = 0;
while ((low <= high) && (!find)) {
mid = (low + high) / 2;
if (k == a[mid]) {
find = 1;
break;
} else {
if (k > a[mid]) {
low = mid + 1;
} else {
high = mid - 1;
}
}
}
if (find) {
return mid;
} else {
return -1;
}
}参数说明:
a: 表示给定的记录集合。
length: 表示给定记录集合的个数。
k: 表示给定值。
结论分析:
折半查找要求查找表按关键字有序,而排序是一种很费事的运算;另外,折半查找要求表是顺序存储的,为保持表的有序性,在进行插入和删除操作时,都必须移动大量记录。因此,折半查找的高查找效率是以牺牲排序为代价的,它特别适合于一经建立就很少移动、而又经常需要查找的线性表。三、索引查找
基本思想:
索引查找又称为分块查找,即把线性表分成若干块,在每一块中记录的关键字不一定有序,但是块与块之间必须有序。假设这种排序是按关键字值递增排序的,抽取各块中的最大关键字及该块的起始位置构成索引表,按块的顺序存放在一个数组中,显然这个数组是有序的,一般按升序排列。文字描述有点晦涩,示意图如下:
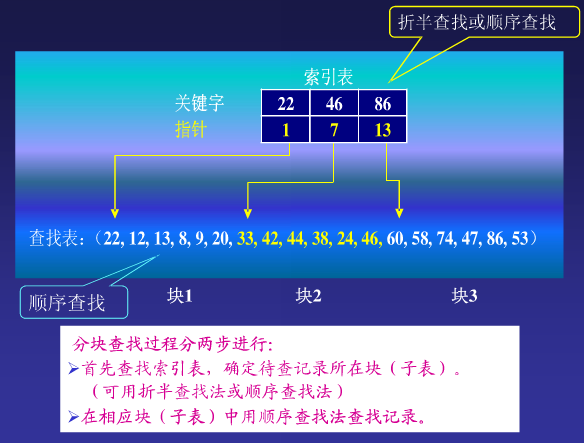
其中,索引表很明显是一个结构体,它的定义如下:
struct idtable {
int key;
int address;
int length;
};key: 索引表中的关键字。
address: 索引表对应块的首地址。
length: 索引表对应块的长度。
从上面的示意图我们可以看出,索引查找,我们可以先对索引表进行折半查找,找出对应的块,然后再在对应的快中利用顺序查找找出需要查找的关键字。
代码清单:
struct idtable {
int key;
int address;
int length;
};
int indexSearch(int *a, int a_length, struct idtable idtables[], int idtables_length, int keyword) {
// 先用二分查找法找出对应的块号
int low1 = 0, high1 = idtables_length - 1, mid = 0;
while (low1 <= high1) {
mid = (low1 + high1) / 2;
if (keyword <= idtables[mid].key) {
high1 = mid - 1;
} else {
low1 = mid + 1; // 查找完毕,low1存放块号
}
}
if (low1 < idtables_length) {
int index = -1;
// low2为块在表中的起始地址
int low2 = idtables[low1].address, high2 = 0;
if (low1 == idtables_length - 1) {
high2 = a_length - 1;
} else {
high2 = idtables[low1 + 1].address - 1;
}
// 用顺序查找法在对应的块中找出符合条件的值
for (int i = low2; i <= high2; i++) {
if (a[i] == keyword) {
index = i;
break;
}
}
return index;
} else {
return -1;
}
}
int main(int argc, const char * argv[]) {
// 主表
int a[] = {22, 12, 13, 8, 9, 20, 33, 42, 44, 38, 24, 46, 60, 58, 74, 47, 86, 53};
// 索引表
struct idtable idtables[3] = {
{22, 0, 6},
{46, 6, 6},
{86, 12, 6}
};
int result = indexSearch(a, 18, idtables, 3, 74);
printf("index:%d", result);
return 0;
}结论分析:
索引查找的效率介于顺序查找和折半查找之间,对于数据量巨大的线性表,它是一种较好的方法。在表中插入或者删除一个记录时,只要找到该记录所属的块,就可以在该块内进行插入和删除运算,插入和删除无需移动大量记录。分块查找的主要代价:需要增加一个辅助数组的存储空间和将初始表分块排序的运算。
















 1404
1404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











