







Tensorflow
TensorFlow是一个采用数据流图(data flow graphs),用于数值计算的开源软件库。**节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor)。**它灵活的架构让你可以在多种平台上展开计算,例如台式计算机中的一个或多个CPU(或GPU),服务器,移动设备等等。TensorFlow 最初由Google大脑小组(隶属于Google机器智能研究机构)的研究员和工程师们开发出来,用于机器学习和深度神经网络方面的研究,但这个系统的通用性使其也可广泛用于其他计算领域。这次的开源发布版本支持单pc或单移动设备上的计算
数据流图(Data Flow Graph)
数据流图用“结点”(nodes)和“线”(edges)的有向图来描述数学计算。“节点” 一般用来表示施加的数学操作,但也可以表示数据输入(feed in)的起点/输出(push out)的终点,或者是读取/写入持久变量(persistent variable)的终点。“线”表示“节点”之间的输入/输出关系。这些数据“线”可以输运“size可动态调整”的多维数据数组,即“张量”(tensor)。张量从图中流过的直观图像是这个工具取名为“Tensorflow”的原因。一旦输入端的所有张量准备好,节点将被分配到各种计算设备完成异步并行地执行运算。
Tensorflow的特征
- 高度的灵活性
TensorFlow 不是一个严格的“神经网络”库。只要你可以将你的计算表示为一个数据流图,你就可以使用Tensorflow。你来构建图,描写驱动计算的内部循环。我们提供了有用的工具来帮助你组装“子图”(常用于神经网络),当然用户也可以自己在Tensorflow基础上写自己的“上层库”。定义顺手好用的新复合操作和写一个python函数一样容易,而且也不用担心性能损耗。当然万一你发现找不到想要的底层数据操作,你也可以自己写一点c++代码来丰富底层的操作。 - 真正的可移植性(Portability)
Tensorflow 在CPU和GPU上运行,比如说可以运行在台式机、服务器、手机移动设备等等。想要在没有特殊硬件的前提下,在你的笔记本上跑一下机器学习的新想法?Tensorflow可以办到这点。准备将你的训练模型在多个CPU上规模化运算,又不想修改代码?Tensorflow可以办到这点。想要将你的训练好的模型作为产品的一部分用到手机app里?Tensorflow可以办到这点。你改变主意了,想要将你的模型作为云端服务运行在自己的服务器上,或者运行在Docker容器里?Tensorfow也能办到 - 多语言支持
Tensorflow 有一个合理的c++使用界面,也有一个易用的python使用界面来构建和执行你的graphs。你可以直接写python/c++程序,也可以用交互式的ipython界面来用Tensorflow尝试些想法,它可以帮你将笔记、代码、可视化等有条理地归置好。当然这仅仅是个起点——我们希望能鼓励你创造自己最喜欢的语言界面,比如Go,Java,Lua,Javascript,或者是R - 性能最优化
比如说你又一个32个CPU内核、4个GPU显卡的工作站,想要将你工作站的计算潜能全发挥出来?由于Tensorflow 给予了线程、队列、异步操作等以最佳的支持,Tensorflow 让你可以将你手边硬件的计算潜能全部发挥出来。你可以自由地将Tensorflow图中的计算元素分配到不同设备上,Tensorflow可以帮你管理好这些不同副本。
Tensorflow有一下几个简单的步骤:
- 使用 tensor 表示数据.
- 使用图 (graph) 来表示计算任务.
- 在会话(session)中运行图
TensorFlow提供多种API。最低级API为您提供完整的编程控制。请注意,tf.contrib.learn这样的高级API可以帮助您管理数据集,估计器,培训和推理。一些高级TensorFlow API(方法名称包含的那些)contrib仍在开发中。某些contrib方法可能会在随后的TensorFlow版本中发生变化或变得过时。这个模块类似于scikit-learn中算法模型。
在 TF 中发生的所有事,都是在会话(Session) 中进行的。所以,当你在 TF 中编写一个加法时,其实你只是设计了一个加法操作,而不是实际添加任何东西。所有的这些设计都是会在图(Graph)中产生,你会在图中保留这些计算操作和张量,而不是具体的值。
图
TensorFlow程序通常被组织成一个构建阶段和一个执行阶段. 在构建阶段, op的执行步骤被描述成一个图. 在执行阶段, 使用会话执行执行图中的op。
构建一个简单的计算图。每个节点采用零个或多个张量作为输入,并产生张量作为输出。一种类型的节点是一个常数。像所有TensorFlow常数一样,它不需要任何输入,它输出一个内部存储的值。
可以创建两个浮点型常量node1 ,node2如下所示:
node1 = tf.constant(3.0, tf.float32)
node2 = tf.constant(4.0)
print(node1, node2) # Tensor("Const:0", shape=(), dtype=float32) Tensor("Const_1:0", shape=(), dtype=float32)
构建图
构建图的第一步, 是创建源 op (source op). 源 op 不需要任何输入, 例如 常量 (Constant). 源 op 的输出被传递给其它 op 做运算.TensorFlow Python 库有一个默认图 (default graph), op 构造器可以为其增加节点. 这个默认图对 许多程序来说已经足够用了
默认Graph值始终注册,并可通过调用访问 tf.get_default_graph()
import tensorflow as tf
# 创建一个常量 op, 产生一个 1x2 矩阵. 这个 op 被作为一个节点,加到默认图中.构造器的返回值代表该常量 op 的返回值.
matrix1 = tf.constant([[3., 3.]])
# 创建另外一个常量 op, 产生一个 2x1 矩阵.
matrix2 = tf.constant([[2.],[2.]])
# 创建一个矩阵乘法 matmul op , 把 'matrix1' 和 'matrix2' 作为输入.返回值 'product' 代表矩阵乘法的结果.
product = tf.matmul(matrix1, matrix2)
print tf.get_default_graph(),matrix1.graph,matrix2.graph
注意:此类对于图形构造不是线程安全的。所有操作都应从单个线程创建,或者必须提供外部同步。除非另有说明,所有方法都不是线程安全的
在会话中启动图
构造阶段完成后,才能启动图。启动图的第一步是创建一个Session对象,如果无任何创建参数,会话构造器将启动默认图。
调用Session的run()方法来执行矩阵乘法op, 传入product作为该方法的参数,会话负责传递op所需的全部输入,op通常是并发执行的。
# 启动默认图.
sess = tf.Session()
# 函数调用 'run(product)' 触发了图中三个 op (两个常量 op 和一个矩阵乘法 op) 的执行.返回值 'result' 是一个 numpy `ndarray` 对象.
result = sess.run(product)
print result
# 任务完成, 关闭会话.
sess.close()
Session对象在使用完后需要关闭以释放资源,当然也可以使用上下文管理器来完成自动关闭动作。
with tf.Session() as sess:
print(sess.run(product))
op
计算图中的每个节点可以有任意多个输入和任意多个输出,每个节点描述了一种运算操作(operation, op),节点可以算作运算操作的实例化(instance)。一种运算操作代表了一种类型的抽象运算,比如矩阵乘法、加法。tensorflow内建了很多种运算操作,如下表所示:
类型 示例
标量运算 Add、Sub、Mul、Div、Exp、Log、Greater、Less、Equal
向量运算 Concat、Slice、Splot、Constant、Rank、Shape、Shuffle
矩阵运算 Matmul、MatrixInverse、MatrixDeterminant
带状态的运算 Variable、Assign、AssignAdd
神经网络组件 SoftMax、Sigmoid、ReLU、Convolution2D、MaxPooling
存储、恢复 Save、Restore
队列及同步运算 Enqueue、Dequeue、MutexAcquire、MutexRelease
控制流 Merge、Switch、Enter、Leave、NextIteration
feed
TensorFlow还提供了feed机制, 该机制可以临时替代图中的任意操作中的tensor可以对图中任何操作提交补丁,直接插入一个 tensor。feed 使用一个 tensor 值临时替换一个操作的输入参数,从而替换原来的输出结果.
**feed 只在调用它的方法内有效, 方法结束,feed就会消失。**最常见的用例是将某些特殊的操作指定为"feed"操作, 标记的方法是使用 tf.placeholder() 为这些操作创建占位符.并且在Session.run方法中增加一个feed_dict参数
# 创建两个个浮点数占位符op
input1 = tf.placeholder(tf.types.float32)
input2 = tf.placeholder(tf.types.float32)
#增加一个乘法op
output = tf.mul(input1, input2)
with tf.Session() as sess:
# 替换input1和input2的值
print sess.run([output], feed_dict={input1:[7.], input2:[2.]})
张量的阶和数据类型
TensorFlow用张量这种数据结构来表示所有的数据.可以把一个张量想象成一个n维的数组或列表.一个张量有一个静态类型和动态类型的维数.张量可以在图中的节点之间流通.其实张量更代表的就是一种多位数组。
阶
在TensorFlow系统中,张量的维数来被描述为阶.但是张量的阶和矩阵的阶并不是同一个概念.张量的阶(有时是关于如顺序或度数或者是n维)是张量维数的一个数量描述.比如,下面的张量(使用Python中list定义的)就是2阶.
t = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
可以认为一个二阶张量就是我们平常所说的矩阵,一阶张量可以认为是一个向量
| 阶 | 数学实例 | Python | 例子 |
|---|---|---|---|
| 0 | 纯量 | (只有大小) | s = 483 |
| 1 | 向量 | (大小和方向) | v = [1.1, 2.2, 3.3] |
| 2 | 矩阵 | (数据表) | m = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] |
| 3 | 3阶张量 | (数据立体) | t = [[[2], [4], [6]], [[8], [10], [12]], [[14], [16], [18]]] |
数据类型
Tensors有一个数据类型属性.可以为一个张量指定下列数据类型中的任意一个类型:
| 数据类型 | Python类型 | 描述 |
| DT_FLOAT | tf.float32 | 32 位浮点数 |
| DT_DOUBLE | tf.float64 | 64 位浮点数 |
| DT_INT64 | tf.int64 | 64 位有符号整型 |
| DT_INT32 | tf.int32 | 32 位有符号整型 |
| DT_INT16 | tf.int16 | 16 位有符号整型 |
| DT_INT8 | tf.int8 | 8 位有符号整型 |
| DT_UINT8 | tf.uint8 | 8 位无符号整型 |
| DT_STRING | tf.string | 可变长度的字节数组.每一个张量元素都是一个字节数组 |
| DT_BOOL | tf.bool | 布尔型 |
| DT_COMPLEX64 | tf.complex64 | 由两个32位浮点数组成的复数:实数和虚数 |
| DT_QINT32 | tf.qint32 | 用于量化Ops的32位有符号整型 |
| DT_QINT8 | tf.qint8 | 用于量化Ops的8位有符号整型 |
| DT_QUINT8 | tf.quint8 | 用于量化Ops的8位无符号整型 |
张量操作
在tensorflow中,有很多操作张量的函数,有生成张量、创建随机张量、张量类型与形状变换和张量的切片与运算
生成张量
固定值张量
- tf.zeros(shape, dtype=tf.float32, name=None)
创建所有元素设置为零的张量。此操作返回一个dtype具有形状shape和所有元素设置为零的类型的张量。 - tf.zeros_like(tensor, dtype=None, name=None)
给tensor定单张量(),此操作返回tensor与所有元素设置为零相同的类型和形状的张量。 - tf.ones(shape, dtype=tf.float32, name=None)
创建一个所有元素设置为1的张量。此操作返回一个类型的张量,dtype形状shape和所有元素设置为1。 - tf.ones_like(tensor, dtype=None, name=None)
给tensor定单张量(),此操作返回tensor与所有元素设置为1 相同的类型和形状的张量。 - tf.fill(dims, value, name=None)
创建一个填充了标量值的张量。此操作创建一个张量的形状dims并填充它value。 - tf.constant(value, dtype=None, shape=None, name=‘Const’)
创建一个常数张量。
t1 = tf.constant([1, 2, 3, 4, 5, 6, 7])
t2 = tf.constant(-1.0, shape=[2, 3])
print(t1,t2)
输出
(<tf.Tensor 'Const:0' shape=(7,) dtype=int32>, <tf.Tensor 'Const_1:0' shape=(2, 3) dtype=float32>)
一个张量包含了一下几个信息
- 一个名字,它用于键值对的存储,用于后续的检索:Const: 0
- 一个形状描述, 描述数据的每一维度的元素个数:(2,3)
- 数据类型,比如int32,float32
创建随机张量
一般经常使用的随机数函数 Math.random() 产生的是服从均匀分布的随机数,能够模拟等概率出现的情况,例如 扔一个骰子,1到6点的概率应该相等,但现实生活中更多的随机现象是符合正态分布的,例如20岁成年人的体重分布等。
假如制作一个游戏,要随机设定许许多多 NPC 的身高,如果还用Math.random(),生成从140 到 220 之间的数字,就会发现每个身高段的人数是一样多的,这是比较无趣的,这样的世界也与习惯不同,现实应该是特别高和特别矮的都很少,处于中间的人数最多,这就要求随机函数符合正态分布。
- tf.random_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None)
从正态分布中输出随机值,由随机正态分布的数字组成的矩阵 - tf.truncated_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None)
从截断的正态分布中输出随机值,和 tf.random_normal() 一样,但是所有数字都不超过两个标准差
# 正态分布的 4X4X4 三维矩阵,平均值 0, 标准差 1
normal = tf.truncated_normal([4, 4, 4], mean=0.0, stddev=1.0)
a = tf.Variable(tf.random_normal([2,2],seed=1))
b = tf.Variable(tf.truncated_normal([2,2],seed=2))
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
print(sess.run(a))
print(sess.run(b))
输出:
[[-0.81131822 1.48459876]
[ 0.06532937 -2.44270396]]
[[-0.85811085 -0.19662298]
[ 0.13895047 -1.22127688]]
- tf.random_uniform(shape, minval=0.0, maxval=1.0, dtype=tf.float32, seed=None, name=None)
从均匀分布输出随机值。生成的值遵循该范围内的均匀分布 [minval, maxval)。下限minval包含在范围内,而maxval排除上限。
a = tf.random_uniform([2,3],1,10)
with tf.Session() as sess:
print(sess.run(a))
输出:
[[2.760602 2.666316 1.3210121]
[8.512259 6.2844787 6.0989685]]
- tf.random_shuffle(value, seed=None, name=None)
沿其第一维度随机打乱 - tf.set_random_seed(seed)
设置图级随机种子
要跨会话生成不同的序列,既不设置图级别也不设置op级别的种子:
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
a = tf.random_uniform([1])
b = tf.random_normal([1])
print ("Session 1")
with tf.Session() as sess1:
print (sess1.run(a))
print (sess1.run(a))
print (sess1.run(b))
print (sess1.run(b))
print ("Session 2")
with tf.Session() as sess2:
print (sess2.run(a))
print (sess2.run(a))
print (sess2.run(b))
print (sess2.run(b))
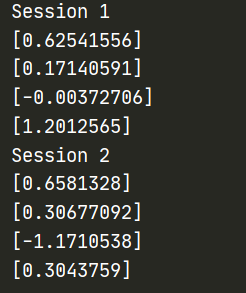
要为跨会话生成一个可操作的序列,请为op设置种子:
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
a = tf.random_uniform([1],seed=1)
b = tf.random_normal([1])
print ("Session 1")
with tf.Session() as sess1:
print (sess1.run(a))
print (sess1.run(a))
print (sess1.run(b))
print (sess1.run(b))
print ("Session 2")
with tf.Session() as sess2:
print (sess2.run(a))
print (sess2.run(a))
print (sess2.run(b))
print (sess2.run(b))
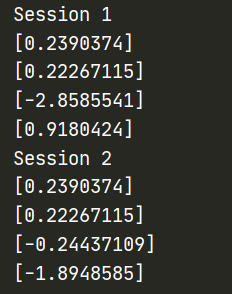
为了使所有op产生的随机序列在会话之间是可重复的,设置一个图级别的种子:
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
tf.set_random_seed(1234)
a = tf.random_uniform([1])
b = tf.random_normal([1])
print ("Session 1")
with tf.Session() as sess1:
print (sess1.run(a))
print (sess1.run(a))
print (sess1.run(b))
print (sess1.run(b))
print ("Session 2")
with tf.Session() as sess2:
print (sess2.run(a))
print (sess2.run(a))
print (sess2.run(b))
print (sess2.run(b))
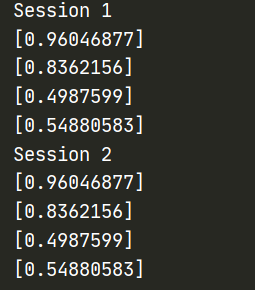
张量变换
改变类型
提供了如下一些改变张量中数值类型的函数
- tf.string_to_number(string_tensor, out_type=None, name=None)
- tf.to_double(x, name=‘ToDouble’)
- tf.to_float(x, name=‘ToFloat’)
- tf.to_bfloat16(x, name=‘ToBFloat16’)
- tf.to_int32(x, name=‘ToInt32’)
- tf.to_int64(x, name=‘ToInt64’)
- tf.cast(x, dtype, name=None)
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
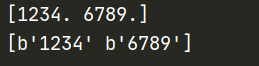
a = tf.constant(['1234','6789'])
b = tf.string_to_number(a,out_type=tf.float32)
with tf.Session() as sess:
print(sess.run(b))
print(sess.run(a))
形状和变换
可用于确定张量的形状并更改张量的形状
- tf.shape(input, name=None)
- tf.size(input, name=None)
- tf.rank(input, name=None)
- tf.reshape(tensor, shape, name=None)
- tf.squeeze(input, squeeze_dims=None, name=None)
- tf.expand_dims(input, dim, name=None)
tf.shape(input, name=None)
返回张量的形状。
t = tf.placeholder(tf.float32,[None,2])
print(t.get_shape())
动态形状 当你在运行你的图时,动态形状才是真正用到的。这种形状是一种描述原始张量在执行过程中的一种张量。如果你定义了一个没有标明具体维度的占位符,即用None表示维度,那么当你将值输入到占位符时,这些无维度就是一个具体的值,并且任何一个依赖这个占位符的变量,都将使用这个值。
tf.shape来描述动态形状
t = tf.placeholder(tf.float32,[None,2])
print(tf.shape(t))
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
# tensorflow:打印出来的形状表示:
# 0 维:() , 1维:(5), 2维:(5,6) 3维:(2,3,4)
# 形状的概念
# 静态形状和动态形状
plt = tf.placeholder(tf.float32,[None,2])
print(plt)
plt.set_shape([3,2])
print(plt)
# 对于静态形状来说,一旦张量形状固定,不能再次设置静态形状,且不能跨维度
# plt.set_shape([4,2])
# 动态形状可以创建一个新的张量,且reshape时,必须保证和原有张量元素数量相当
plt_reshap = tf.reshape(plt,[1,6])
a = tf.constant([1,2,3])
b = tf.constant([4,5,6])
c = tf.concat([a,b],axis=0) # 0按行合并
b = tf.cast(b,tf.float32)
print(b)
print(plt_reshap)
with tf.Session() as sess:
print(c.eval())

- tf.squeeze(input, squeeze_dims=None, name=None)
这个函数的作用是将input中维度是1的那一维去掉。但是如果不想把维度是1的全部去掉,那么可以使用squeeze_dims参数,来指定需要去掉的位置。
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
sess = tf.Session()
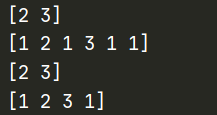
data = tf.constant([[1, 2, 1], [3, 1, 1]])
print (sess.run(tf.shape(data)))
print(sess.run(tf.squeeze(data)))
d_1 = tf.expand_dims(data, 0)
d_1 = tf.expand_dims(d_1, 2)
d_1 = tf.expand_dims(d_1, -1)
d_1 = tf.expand_dims(d_1, -1)
print (sess.run(tf.shape(d_1)))
d_2 = d_1
print (sess.run(tf.shape(tf.squeeze(d_1))))
print (sess.run(tf.shape(tf.squeeze(d_2, [2, 4]))))
sess.close()
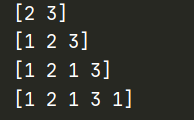
- tf.expand_dims(input, dim, name=None)
该函数作用与squeeze相反,添加一个指定维度
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
sess = tf.Session()
data = tf.constant([[1, 2, 1], [3, 1, 1]])
print (sess.run(tf.shape(data)))
d_1 = tf.expand_dims(data, 0)
print (sess.run(tf.shape(d_1)))
d_1 = tf.expand_dims(d_1, 2)
print (sess.run(tf.shape(d_1)))
d_1 = tf.expand_dims(d_1, -1)
print (sess.run(tf.shape(d_1)))
sess.close()
切片与扩展
TensorFlow提供了几个操作来切片或提取张量的部分,或者将多个张量加在一起
tf.slice(input_, begin, size, name=None)
tf.split(split_dim, num_split, value, name=‘split’)
tf.tile(input, multiples, name=None)
tf.pad(input, paddings, name=None)
tf.concat(concat_dim, values, name=‘concat’)
tf.pack(values, name=‘pack’)
tf.unpack(value, num=None, name=‘unpack’)
tf.reverse_sequence(input, seq_lengths, seq_dim, name=None)
tf.reverse(tensor, dims, name=None)
tf.transpose(a, perm=None, name=‘transpose’)
tf.gather(params, indices, name=None)
tf.dynamic_partition(data, partitions, num_partitions, name=None)
tf.dynamic_stitch(indices, data, name=None)
张量复制与组合
tf.identity(input, name=None)
tf.tuple(tensors, name=None, control_inputs=None)
tf.group(inputs, *kwargs)
tf.no_op(name=None)
tf.count_up_to(ref, limit, name=None)
逻辑运算符
tf.logical_and(x, y, name=None)
tf.logical_not(x, name=None)
tf.logical_or(x, y, name=None)
tf.logical_xor(x, y, name=‘LogicalXor’)
比较运算符
tf.equal(x, y, name=None)
tf.not_equal(x, y, name=None)
tf.less(x, y, name=None)
tf.less_equal(x, y, name=None)
tf.greater(x, y, name=None)
tf.greater_equal(x, y, name=None)
tf.select(condition, t, e, name=None)
tf.where(input, name=None)
判断检查
tf.is_finite(x, name=None)
tf.is_inf(x, name=None)
tf.is_nan(x, name=None)
tf.verify_tensor_all_finite(t, msg, name=None) 断言张量不包含任何NaN或Inf
tf.check_numerics(tensor, message, name=None)
tf.add_check_numerics_ops()
tf.Assert(condition, data, summarize=None, name=None)
tf.Print(input_, data, message=None, first_n=None, summarize=None, name=None)
变量的的创建、初始化、保存和加载
其实变量的作用在语言中相当,都有存储一些临时值的作用或者长久存储。在Tensorflow中当训练模型时,用变量来存储和更新参数。变量包含张量(Tensor)存放于内存的缓存区。建模时它们需要被明确地初始化,模型训练后它们必须被存储到磁盘。值可在之后模型训练和分析是被加载。
Variable类
tf.Variable.init(initial_value, trainable=True, collections=None, validate_shape=True, name=None)
创建一个带值的新变量initial_value
- initial_value:A Tensor或Python对象可转换为a Tensor.变量的初始值.必须具有指定的形状,除非 validate_shape设置为False.
- trainable:如果True,默认值也将该变量添加到图形集合GraphKeys.TRAINABLE_VARIABLES,该集合用作Optimizer类要使用的变量的默认列表
- collections:图表集合键列表,新变量添加到这些集合中.默认为[GraphKeys.VARIABLES]
- validate_shape:如果False允许使用未知形状的值初始化变量,如果True,默认形状initial_value必须提供.
- name:变量的可选名称,默认’Variable’并自动获取
变量的创建
创建当一个变量时,将你一个张量作为初始值传入构造函数Variable().TensorFlow提供了一系列操作符来初始化张量,值初始的英文常量或是随机值。像任何一样Tensor,创建的变量Variable()可以用作图中其他操作的输入。此外,为Tensor该类重载的所有运算符都被转载到变量中,因此您也可以通过对变量进行算术来将节点添加到图形中。
x = tf.Variable(5.0,name="x")
weights = tf.Variable(tf.random_normal([784, 200], stddev=0.35),name="weights")
biases = tf.Variable(tf.zeros([200]), name="biases")
调用tf.Variable()向图中添加了几个操作:
- 一个variable op保存变量值。
- 初始化器op将变量设置为其初始值。这实际上是一个tf.assign操作。
- 初始值的ops,例如 示例中biases变量的zeros op 也被添加到图中。
变量的初始化
变量的初始化必须在模型的其它操作运行之前先明确地完成。最简单的方法就是添加一个给所有变量初始化的操作,并在使用模型之前首先运行那个操作。最常见的初始化模式是使用便利函数 initialize_all_variables()将Op添加到初始化所有变量的图形中。
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
还可以通过运行其初始化函数op来初始化变量,从保存文件还原变量,或者简单地运行assign向变量分配值的Op。实际上,变量初始化器op只是一个assignOp,它将变量的初始值赋给变量本身。assign是一个方法
with tf.Session() as sess:
sess.run(w.initializer)
通过另一个变量赋值
有时候会需要用另一个变量的初始化值给当前变量初始化,由于tf.global_variables_initializer()初始化所有变量,所以需要注意这个方法的使用。
就是将已初始化的变量的值赋值给另一个新变量
weights = tf.Variable(tf.random_normal([784, 200], stddev=0.35),name="weights")
w2 = tf.Variable(weights.initialized_value(), name="w2")
w_twice = tf.Variable(weights.initialized_value() * 0.2, name="w_twice")
所有变量都会自动收集到创建它们的图形中。默认情况下,构造函数将新变量添加到图形集合GraphKeys.GLOBAL_VARIABLES。方便函数 global_variables()返回该集合的内容。
属性
- name
返回变量的名字
weights = tf.Variable(tf.random_normal([784, 200], stddev=0.35),name="weights")
print(weights.name)
- op
返回op操作
weights = tf.Variable(tf.random_normal([784, 200], stddev=0.35))
print(weights.op)
方法
- assign
为变量分配一个新值。
x = tf.Variable(5.0,name="x")
w.assign(w + 1.0)
- eval
在会话中,计算并返回此变量的值。这不是一个图形构造方法,它不会向图形添加操作。方便打印结果
v = tf.Variable([1, 2])
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
# 指定会话
print(v.eval(sess))
# 使用默认会话
print(v.eval())
变量的静态形状与动态形状
TensorFlow中,张量具有静态(推测)形状和动态(真实)形状
- 静态形状:
创建一个张量或者由操作推导出一个张量时,初始状态的形状- tf.Tensor.get_shape:获取静态形状
- tf.Tensor.set_shape():更新Tensor对象的静态形状,通常用于在不能直接推断的情况下
- 动态形状:
一种描述原始张量在执行过程中的一种形状- tf.shape(tf.Tensor):如果在运行的时候想知道None到底是多少,只能通过tf.shape(tensor)[0]这种方式来获得
- tf.reshape:创建一个具有不同动态形状的新张量
1、转换静态形状的时候,1-D到1-D,2-D到2-D,不能跨阶数改变形状
2、对于已经固定或者设置静态形状的张量/变量,不能再次设置静态形状
3、tf.reshape()动态创建新张量时,元素个数不能不匹配
4、运行时候,动态获取张量的形状值,只能通过tf.shape(tensor)[]
管理图中收集的变量
tf.global_variables()
返回图中收集的所有变量
weights = tf.Variable(tf.random_normal([784, 200], stddev=0.35))
print(tf.global_variables())
变量作用域
tensorflow提供了变量作用域和共享变量这样的概念,有几个重要的作用。
让模型代码更加清晰,作用分明
通过tf.variable_scope()创建指定名字的变量作用域
with tf.variable_scope("init"):
print("----")
嵌套使用
变量作用域可以嵌套使用
with tf.variable_scope("init") :
with tf.variable_scope("data") :
print("----")
变量作用域下的变量
在同一个变量作用域下,如果定义了两个相同名称的变量(这里先用tf.Variable())
with tf.variable_scope("itcast") as scope:
a = tf.Variable([1.0,2.0],name="a")
b = tf.Variable([2.0,3.0],name="a")
通过tensoflow提供的计算图界面观察

取了同样的名字,其实tensorflow并没有当作同一个,而是另外又增加了一个a_1,来表示b的图
变量范围
当每次在一个变量作用域中创建变量的时候,会在变量的name前面加上变量作用域的名称
with tf.variable_scope("init"):
a = tf.Variable(1.0,name="a")
b = tf.get_variable("b", [1])
print(a.name,b.name) # init/a:0 init/b:0
图与会话
图
tf.Graph
TensorFlow计算,表示为数据流图。一个图包含一组表示 tf.Operation计算单位的对象和tf.Tensor表示操作之间流动的数据单元的对象。默认Graph值始终注册,并可通过调用访问 tf.get_default_graph。
默认图
通常TensorFlow会默认帮我们创建一张图。
查看默认图的两种方法:
- 通过调用tf.get_default_graph()访问 ,要将操作添加到默认图形中,直接创建OP即可。
- op、sess都含有graph属性 ,默认都在一张图中
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
def graph_demo():
# 图的演示
a_t = tf.constant(10)
b_t = tf.constant(20)
# 不提倡直接运用这种符号运算符进行计算
# 更常用tensorflow提供的函数进行计算
# c_t = a_t + b_t
c_t = tf.add(a_t, b_t)
print("tensorflow实现加法运算:\n", c_t)
# 获取默认图
default_g = tf.get_default_graph()
print("获取默认图:\n", default_g)
# 数据的图属性
print("a_t的graph:\n", a_t.graph)
print("b_t的graph:\n", b_t.graph)
# 操作的图属性
print("c_t的graph:\n", c_t.graph)
# 开启会话
with tf.Session() as sess:
sum_t = sess.run(c_t)
print("在sess当中的sum_t:\n", sum_t)
# 会话的图属性
print("会话的图属性:\n", sess.graph)
return None
if __name__ =='__main__':
graph_demo()

# 实现一个加法运算
con_a = tf.constant(3.0)
con_b = tf.constant(4.0)
sum_c = tf.add(con_a, con_b)
print("打印con_a:\n", con_a)
print("打印con_b:\n", con_b)
print("打印sum_c:\n", sum_c)
打印语句会生成:
打印con_a:
Tensor("Const:0", shape=(), dtype=float32)
打印con_b:
Tensor("Const_1:0", shape=(), dtype=float32)
打印sum_c:
Tensor("Add:0", shape=(), dtype=float32)
注意,打印出来的是张量值,可以理解成OP当中包含了这个值。并且每一个OP指令都对应一个唯一的名称,如上面的Const:0,这个在TensorBoard上面也可以显示
请注意,tf.Tensor 对象以输出该张量的 tf.Operation 明确命名。张量名称的形式为 “<OP_NAME>:”,其中:
- “<OP_NAME>” 是生成该张量的指令的名称
- “<i>” 是一个整数,它表示该张量在指令的输出中的索引
创建图
- 可以通过tf.Graph()自定义创建图
- 如果要在这张图中创建OP,典型用法是使用tf.Graph.as_default()上下文管理器
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
def graph_demo():
# 图的演示
a_t = tf.constant(10)
b_t = tf.constant(20)
# 不提倡直接运用这种符号运算符进行计算
# 更常用tensorflow提供的函数进行计算
# c_t = a_t + b_t
c_t = tf.add(a_t, b_t)
print("tensorflow实现加法运算:\n", c_t)
# 获取默认图
default_g = tf.get_default_graph()
print("获取默认图:\n", default_g)
# 数据的图属性
print("a_t的graph:\n", a_t.graph)
print("b_t的graph:\n", b_t.graph)
# 操作的图属性
print("c_t的graph:\n", c_t.graph)
# 自定义图
new_g = tf.Graph()
print("自定义图:\n", new_g)
# 在自定义图中去定义数据和操作
with new_g.as_default():
new_a = tf.constant(30)
new_b = tf.constant(40)
new_c = tf.add(new_a, new_b)
# 数据的图属性
print("new_a的graph:\n", new_a.graph)
print("new_b的graph:\n", new_b.graph)
# 操作的图属性
print("new_c的graph:\n", new_c.graph)
# 开启会话
with tf.Session() as sess:
sum_t = sess.run(c_t)
print("在sess当中的sum_t:\n", sum_t)
# 会话的图属性
print("会话的图属性:\n", sess.graph)
# 不同的图之间不能互相访问
# sum_new = sess.run(new_c)
# print("在sess当中的sum_new:\n", sum_new)
with tf.Session(graph=new_g) as sess2:
sum_new = sess2.run(new_c)
print("在sess2当中的sum_new:\n", sum_new)
print("会话的图属性:\n", sess2.graph)
# 很少会同时开启不同的图,一般用默认的图就够了
return None
if __name__ =='__main__':
graph_demo()
tensorflow实现加法运算:
Tensor("Add:0", shape=(), dtype=int32)
获取默认图:
<tensorflow.python.framework.ops.Graph object at 0x00000212A47FCF98>
a_t的graph:
<tensorflow.python.framework.ops.Graph object at 0x00000212A47FCF98>
b_t的graph:
<tensorflow.python.framework.ops.Graph object at 0x00000212A47FCF98>
c_t的graph:
<tensorflow.python.framework.ops.Graph object at 0x00000212A47FCF98>
自定义图:
<tensorflow.python.framework.ops.Graph object at 0x00000212B8422DD8>
new_a的graph:
<tensorflow.python.framework.ops.Graph object at 0x00000212B8422DD8>
new_b的graph:
<tensorflow.python.framework.ops.Graph object at 0x00000212B8422DD8>
new_c的graph:
<tensorflow.python.framework.ops.Graph object at 0x00000212B8422DD8>
在sess当中的sum_t:
30
会话的图属性:
<tensorflow.python.framework.ops.Graph object at 0x00000212A47FCF98>
在sess2当中的sum_new:
70
会话的图属性:
<tensorflow.python.framework.ops.Graph object at 0x00000212B8422DD8>
会话
tf.Session
运行TensorFlow操作图的类,一个包含ops执行和tensor被评估
a = tf.constant(5.0)
b = tf.constant(6.0)
c = a * b
sess = tf.Session()
print(sess.run(c))
在开启会话的时候指定图
with tf.Session(graph=g) as sess:
......
资源释放
会话可能拥有很多资源,如 tf.Variable,tf.QueueBase和tf.ReaderBase。在不再需要这些资源时,重要的是释放这些资源。要做到这一点,既可以调用tf.Session.close会话中的方法,也可以使用会话作为上下文管理器。以下两个例子是等效的:
# 使用close手动关闭
sess = tf.Session()
sess.run(...)
sess.close()
# 使用上下文管理器
with tf.Session() as sess:
sess.run(...)
run方法
run(fetches, feed_dict=None, options=None, run_metadata=None)
运行ops和计算tensor
- fetches 可以是单个图形元素,或任意嵌套列表,元组,namedtuple,dict或OrderedDict
- feed_dict 允许调用者覆盖图中指定张量的值
a = tf.placeholder(tf.float32, shape=[])
b = tf.placeholder(tf.float32, shape=[])
c = tf.constant([1,2,3])
with tf.Session() as sess:
a,b,c = sess.run([a,b,c],feed_dict={a: 1, b: 2,c:[4,5,6]})
print(a,b,c) # 1.0 2.0 [4 5 6]
错误
- RuntimeError:如果它Session处于无效状态(例如已关闭)。
- TypeError:如果fetches或feed_dict键是不合适的类型。
- ValueError:如果fetches或feed_dict键无效或引用 Tensor不存在。
其它属性和方法
- graph
返回本次会话中的图 - as_default()
返回使此对象成为默认会话的上下文管理器。
获取当前的默认会话,请使用 tf.get_default_session
c = tf.constant(..)
sess = tf.Session()
with sess.as_default():
assert tf.get_default_session() is sess
print(c.eval())
注意: 使用这个上下文管理器并不会在退出的时候关闭会话,还需要手动的去关闭
c = tf.constant(...)
sess = tf.Session()
with sess.as_default():
print(c.eval())
with sess.as_default():
print(c.eval())
sess.close()
TensorBoard:可视化学习
TensorFlow 可用于训练大规模深度神经网络所需的计算,使用该工具涉及的计算往往复杂而深奥。为了更方便 TensorFlow 程序的理解、调试与优化,TensorFlow提供了TensorBoard 可视化工具。

实现程序可视化过程:
1 数据序列化-events文件
TensorBoard 通过读取 TensorFlow 的事件文件来运行,需要将数据生成一个序列化的 Summary protobuf 对象。
# 返回filewriter,写入事件文件到指定目录(最好用绝对路径),以提供给tensorboard使用
tf.summary.FileWriter('./tmp/summary/test/', graph=sess.graph)
这将在指定目录中生成一个 event 文件,其名称格式如下:
events.out.tfevents.{timestamp}.{hostname}

2 启动TensorBoard
tensorboard --logdir="./tmp/tensorflow/summary/test/"
注意:必须是双引号
在浏览器中打开 TensorBoard 的图页面 127.0.0.1:6006 ,会看到与以下图形类似的图,在GRAPHS模块我们可以看到以下图结构


节点符号

import tensorflow as tf
graph = tf.Graph()
with graph.as_default():
with tf.name_scope("name1") as scope:
a = tf.Variable([1.0,2.0],name="a")
with tf.name_scope("name2") as scope:
b = tf.Variable(tf.zeros([20]),name="b")
c = tf.Variable(tf.ones([20]),name="c")
with tf.name_scope("cal") as scope:
d = tf.concat([b,c],0)
e = tf.add(a,5)
with tf.Session(graph=graph) as sess:
tf.global_variables_initializer().run()
# merged = tf.summary.merge_all()
summary_writer = tf.summary.FileWriter('/tmp/summary/test/', graph=sess.graph)
sess.run([d,e])
这里定义了三个名称域,分别为name1,name2和cal。

那么所有的常数、变量或者操作都在对应的名称域中,我们可以通过点击加号或者减号来查看详细内容。在name1中,有我们定义的变量a,依赖于初始化,并且也有对应的张量的阶。同样在name2中,有变量b和c。图中实线是我们整个程序的数据流向边。在cal名称域中,有两个运算操作,数据从前面两个名称域中流入。
节点详细信息
每点击一个节点在整个tensorboard右上角会出现节点的详细信息。

添加节点汇总操作
那么tensorboard还提供了另外重要的功能,那就是追踪程序中的变量以及图片相关信息,也就是可以一直观察程序中的变量值的变化曲线首先在构建计算图的时候一个变量一个变量搜集,构建完后将这些变量合并然后在训练过程中写入到事件文件中。
收集操作
- tf.summary.scalar() 收集对于损失函数和准确率等单值变量
- tf.summary.histogram() 收集高维度的变量参数
- tf.summary.image() 收集输入的图片张量能显示图片
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_label, logits=y))
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_label, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar("loss",cross_entropy)
tf.summary.scalar("accuracy", accuracy)
tf.summary.histogram("W",W)
然后合并所有的变量,将这些信息一起写入事件文件中
# 合并
merged = tf.summary.merge_all()
summary_writer = tf.summary.FileWriter(FLAGS.summary_dir, graph=sess.graph)
# 运行
summary = sess.run(merged)
#写入
summary_writer.add_summary(summary,i)
通过运行tensorboard


import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
def tensorflow_test():
a = 10
b = 20
c = a + b
print(c)
con1 = tf.constant(10,name='a')
con2 = tf.constant(20,name='b')
sum_t = tf.add(con1,con2,name='sum')
print(sum_t)
# 打印默认图
print(tf.get_default_graph())
print(con1.graph)
print(con2.graph)
print(sum_t.graph)
# 创建一个自定义图
new_g = tf.Graph()
with new_g.as_default():
new_a = tf.constant(10)
new_b = tf.constant(20)
sum_n = tf.add(new_a, new_b)
print(new_a.graph)
print(new_b.graph)
print(sum_n.graph)
# 开启会话
# Session(graph=指定运行该图,不传默认为默认图,而非自定义图)
# with tf.Session(graph=new_g) as sess:
with tf.Session() as sess:
print(sess.run(sum_t))
# board可视化,先序列化为events文件
# sess.graph 获取默认图即tf.get_default_graph()
# 这将在指定目录中生成一个event文件,其名称格式如下:
# events.out.tfevents.{timestamp}.{hostname}
file_writter = tf.summary.FileWriter('./temp/summary/',graph=sess.graph)
print(sess.graph)
if __name__ =="__main__":
tensorflow_test()

模型保存与恢复、自定义命令行参数、
训练或者测试过程中,总会遇到需要保存训练完成的模型,然后从中恢复继续我们的测试或者其它使用。模型的保存和恢复也是通过tf.train.Saver类去实现,它主要通过将Saver类添加OPS保存和恢复变量到checkpoint。它还提供了运行这些操作的便利方法。
tf.train.Saver(var_list=None, reshape=False, sharded=False, max_to_keep=5, keep_checkpoint_every_n_hours=10000.0, name=None, restore_sequentially=False, saver_def=None, builder=None, defer_build=False, allow_empty=False, write_version=tf.SaverDef.V2, pad_step_number=False)
- var_list:指定将要保存和还原的变量。它可以作为一个dict或一个列表传递.
- max_to_keep:指示要保留的最近检查点文件的最大数量。创建新文件时,会删除较旧的文件。如果无或0,则保留所有检查点文件。默认为5(即保留最新的5个检查点文件。)
- keep_checkpoint_every_n_hours:多久生成一个新的检查点文件。默认为10,000小时
保存
保存我们的模型需要调用Saver.save()方法。save(sess, save_path, global_step=None),checkpoint是专有格式的二进制文件,将变量名称映射到张量值。
import tensorflow as tf
a = tf.Variable([[1.0,2.0]],name="a")
b = tf.Variable([[3.0],[4.0]],name="b")
c = tf.matmul(a,b)
saver=tf.train.Saver()
with tf.Session() as sess:
tf.global_variables_initializer().run()
print(sess.run(c))
saver.save(sess, '/tmp/ckpt/test/matmul')
在多次训练的时候可以指定多少间隔生成检查点文件
saver.save(sess, '/tmp/ckpt/test/matmu', global_step=0) ==> filename: 'matmu-0'
saver.save(sess, '/tmp/ckpt/test/matmu', global_step=1000) ==> filename: 'matmu-1000'
恢复
恢复模型的方法是restore(sess, save_path),save_path是以前保存参数的路径,我们可以使用tf.train.latest_checkpoint来获取最近的检查点文件(也恶意直接写文件目录)
import tensorflow as tf
a = tf.Variable([[1.0,2.0]],name="a")
b = tf.Variable([[3.0],[4.0]],name="b")
c = tf.matmul(a,b)
saver=tf.train.Saver(max_to_keep=1)
with tf.Session() as sess:
tf.global_variables_initializer().run()
print(sess.run(c))
saver.save(sess, '/tmp/ckpt/test/matmul')
# 恢复模型
model_file = tf.train.latest_checkpoint('/tmp/ckpt/test/')
saver.restore(sess, model_file)
print(sess.run([c], feed_dict={a: [[5.0,6.0]], b: [[7.0],[8.0]]}))
自定义命令行参数
tf.app.run(),默认调用main()函数,运行程序。main(argv)必须传一个参数。
tf.app.flags,它支持应用从命令行接受参数,可以用来指定集群配置等。在tf.app.flags下面有各种定义参数的类型
- DEFINE_string(flag_name, default_value, docstring)
- DEFINE_integer(flag_name, default_value, docstring)
- DEFINE_boolean(flag_name, default_value, docstring)
- DEFINE_float(flag_name, default_value, docstring)
第一个也就是参数的名字,路径、大小等等。第二个参数提供具体的值。第三个参数是说明文档
tf.app.flags.FLAGS,在flags有一个FLAGS标志,它在程序中可以调用到前面具体定义的flag_name.
import tensorflow as tf
FLAGS = tf.app.flags.FLAGS
tf.app.flags.DEFINE_string('data_dir', '/tmp/tensorflow/mnist/input_data',
"""数据集目录""")
tf.app.flags.DEFINE_integer('max_steps', 2000,
"""训练次数""")
tf.app.flags.DEFINE_string('summary_dir', '/tmp/summary/mnist/convtrain',
"""事件文件目录""")
def main(argv):
print(FLAGS.data_dir)
print(FLAGS.max_steps)
print(FLAGS.summary_dir)
print(argv)
if __name__=="__main__":
tf.app.run()
/tmp/tensorflow/mnist/input_data
2000
/tmp/summary/mnist/convtrain
['D:/recommend/DL/test111.py']
案例:实现线性回归的训练
根据数据建立回归模型,w1x1+w2x2+……+b = y,通过真实值与预测值之间建立误差,使用梯度下降优化得到损失最小对应的权重和偏置。最终确定模型的权重和偏置参数。最后可以用这些参数进行预测。
- 假设随机指定100个点,只有一个特征
- 数据本身的分布为 y = 0.8 * x + 0.7
API
- 运算
- 矩阵运算
- tf.matmul(x, w)
- 平方
- tf.square(error)
- 均值
- tf.reduce_mean(error)
- 矩阵运算
- 梯度下降优化
tf.train.GradientDescentOptimizer(learning_rate)
梯度下降优化- learning_rate:学习率,一般为0~1之间比较小的值
- method:
- minimize(loss)
- return:梯度下降op
步骤分析
- 准备好数据集:y = 0.8x + 0.7 100个样本
- 建立线性模型
随机初始化W1和b1
y = W·X + b,目标:求出权重W和偏置b - 确定损失函数(预测值与真实值之间的误差)-均方误差
- 梯度下降优化损失:需要指定学习率(超参数)
实现
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
def linear_regression():
"""
根据数据实现一个线性回归问题
"""
# 训练数据:
# 特征值:100个点,只有一个特征, 100个样本[100, 1]
# 1 准备好数据集:y = 0.8x + 0.7 100个样本
X = tf.random_normal(shape=(100,1),mean=2,stddev=1.0,name='feature') # 正太分布获取
# 目标值:y =( 0.8 *x + 0.7)这个模型参数的值,是不知道的
# [100,1] * [1,1]
y_true = tf.matmul(X,[[0.8]])+0.7 # matmul矩阵乘法
# 2 建立线性模型
# x [100,1] * [1,1] , y[100]
# y = wx +b,w[1,1],b[1,1]
# 训练模型参数必须使用tf.Variable
# 随机初始化W1和b1
weight = tf.Variable(initial_value=tf.random_normal([1,1]),name='w') # 标准正太分布生成一个初始随机参数
# trainable 改变量是否在训练过程时改变 ,默认为True
# bias = tf.Variable(initial_value=tf.random_normal([1,1]),name='bias',trainable=False)
bias = tf.Variable(initial_value=tf.random_normal([1, 1]), name='bias') # 随机初始化偏置
# y = W·X + b,目标:求出权重W和偏置b
y_predict = tf.matmul(X,weight) + bias # y=wx+b
# 3 确定损失函数(预测值与真实值之间的误差)-均方误差
loss = tf.reduce_mean(tf.square(y_true-y_predict)) # reduce_mean 求和再求均值
# 4 梯度下降优化损失:需要指定学习率(超参数)
# W2 = W1 - 学习率*(方向)
# b2 = b1 - 学习率*(方向)
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01).minimize(loss) # minimize 传入需要优化的变量
# 手动初始化Variable
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
# 训练线性回归模型-运行整个图
print("训练前,损失为:",sess.run(loss))
print('随机初始化weight=%lf,bias=%lf'%(weight.eval(),bias.eval()))
# 将整张图写入文件中
file_writer = tf.summary.FileWriter('./temp/linear',graph=sess.graph)
for i in range(1,101):
sess.run(optimizer)
print("第%d步的误差为%f,权重为%f, 偏置为%f" % (i, loss.eval(), weight.eval(), bias.eval()))
# 总结:学习率和步长是会决定你的训练最后时间
if __name__ == '__main__':
linear_regression()
....
第94步的误差为0.000367,权重为0.780654, 偏置为0.747229
第95步的误差为0.000392,权重为0.780744, 偏置为0.747057
第96步的误差为0.000315,权重为0.780746, 偏置为0.746856
第97步的误差为0.000407,权重为0.780785, 偏置为0.746678
第98步的误差为0.000537,权重为0.780720, 偏置为0.746447
第99步的误差为0.000465,权重为0.780748, 偏置为0.746269
第100步的误差为0.000493,权重为0.780783, 偏置为0.746064
tensorboard 可视化

变量的trainable设置观察
trainable的参数作用,指定是否训练
weight = tf.Variable(tf.random_normal([1, 1], mean=0.0, stddev=1.0), name="weights", trainable=False)
保存和加载模型
import tensorflow as tf
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"]='2'
def linear_regression():
# 实现线性回归
# 1.创建数据,x特征值[1,100], y目标值[100]
x = tf.random_normal(shape=(100,1),mean=1.75,stddev=0.5,name='x_data')
y_true = tf.matmul(x,[[0.7]])+ 0.8
# 2 建立线性模型 --y=kx+b
# x [100,1] * [1,1] , y[100]
# y = wx +b,w[1,1],b[1,1]
# 训练模型参数必须使用tf.Variable
# 随机初始化W1和b1,然后计算损失,在当前y_true下进行优化
weight = tf.Variable(initial_value=tf.random_normal([1,1]),name='w') # 标准正太分布初始化权重
bias = tf.Variable(initial_value=tf.random_normal([1,1]),name='b')
y_predict = tf.matmul(x,weight)+bias
# 3 确定损失函数(预测值与真实值之间的误差)-均方误差
loss = tf.reduce_mean(tf.square(y_true-y_predict))
# 4.梯度下降优化损失
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1,).minimize(loss)
# 初始化变量
init = tf.global_variables_initializer()
# 实例化保存模型加载模型对象
saver = tf.train.Saver()
# 收集需要观察的变量
tf.summary.scalar('losses',loss) # scalar收集标量信息
tf.summary.histogram('weight',weight)
tf.summary.histogram('bias',bias) # 收集直方图信息
# 合并tensor
merge = tf.summary.merge_all()
# 通过会话运行程序
with tf.Session() as sess:
sess.run(init)
# 打印初始化的变量值
print('初始化权重为%lf,偏置为%lf' % (weight.eval(),bias.eval()))
print('训练前损失为',loss)
# 将整张图写入文件
file_writer = tf.summary.FileWriter('./temp/summary/linearmodel_2',graph=sess.graph)
# 保存模型
checkpoint = tf.train.latest_checkpoint('./temp/ckpt/test_2/mymodel.ckpt')
# 若已经存在模型,则加载模型
if checkpoint is not None:
saver.restore(sess,checkpoint)
# if os.path.exists('./temp/ckpt/test_2/mymodel.ckpt'):
# saver.restore(sess, './temp/ckpt/test_2/mymodel.ckpt')
# 训练模型
for i in range(1,101):
sess.run(optimizer)
print("第%d步的误差为%f,权重为%f, 偏置为%f" % (i, loss.eval(), weight.eval(), bias.eval()))
# 运行观察tensor结果
summary = sess.run(merge)
file_writer.add_summary(summary,i) # 观察第i步结果
saver.save(sess,'./temp/ckpt/test_2/mymodel.ckpt')
if __name__ =='__main__':
linear_regression()

增加命名空间
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
# 命令行参数:第一个参数,名字或默认值或说明
# 指定模型训练步数
# tf.app.flags.DEFINE_integer = ('max_step',0,'线性回归模型训练步数')
# tf.app.flags.DEFINE_string('model_pate', '', './temp/ckpt/test/myregression.ckpt')
# FLAGS = tf.app.flags.FLAGS
def linear_regression():
with tf.variable_scope('init_data'):
# 1 准备好数据集:y = 0.8x + 0.7 100个样本
X = tf.random_normal(shape=(100,1),mean=2,stddev=1.0,name='feature') # 正太分布获取
# 目标值:y =( 0.8 *x + 0.7)这个模型参数的值,是不知道的
# [100,1] * [1,1]
y_true = tf.matmul(X,[[0.8]],name='original_matmul')+0.7 # matmul矩阵乘法
# 2 建立线性模型
with tf.variable_scope('linear_model'):
weight = tf.Variable(initial_value=tf.random_normal([1,1]),name='w') # 标准正太分布生成一个初始随机参数
bias = tf.Variable(initial_value=tf.random_normal([1, 1]), name='bias') # 随机初始化偏置
# y = W·X + b,目标:求出权重W和偏置b
y_predict = tf.matmul(X,weight,name='matmul_model') + bias # y=wx+b
# 3 确定损失函数(预测值与真实值之间的误差)-均方误差
with tf.variable_scope('loss_model'):
loss = tf.reduce_mean(tf.square(y_true-y_predict)) # reduce_mean 求和再求均值
# 4 梯度下降优化损失:需要指定学习率(超参数)
with tf.variable_scope('gd_optimizer'):
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01,name='optimizer').minimize(loss) # minimize 传入需要优化的变量
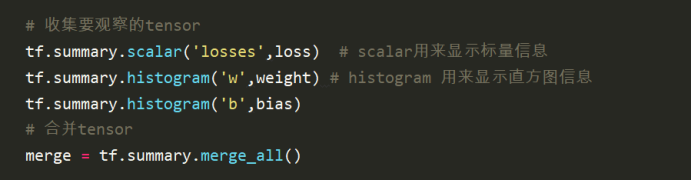
# 收集要观察的tensor
tf.summary.scalar('losses',loss) # scalar用来显示标量信息
tf.summary.histogram('w',weight) # histogram 用来显示直方图信息
tf.summary.histogram('b',bias)
# 合并tensor
merge = tf.summary.merge_all()
# 模型的保存
saver = tf.train.Saver()
# 手动初始化Variable
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
# 训练线性回归模型-运行整个图
print("训练前,损失为:",sess.run(loss))
print('随机初始化weight=%lf,bias=%lf'%(weight.eval(),bias.eval()))
# 将整张图写入文件中
file_writer = tf.summary.FileWriter("./temp/summary/linearmodel",graph=sess.graph)
# 加载历史模型,基于历史模型训练
checkpoint = tf.train.latest_checkpoint("./temp/ckpt/test/myregression.ckpt")
if checkpoint is not None:
saver.restore(sess, checkpoint)
# for i in range(FLAGS.max_step):
for i in range(1,101):
sess.run(optimizer)
print("第%d步的误差为%f,权重为%f, 偏置为%f" % (i, loss.eval(), weight.eval(), bias.eval()))
# 运行观察tensor结果
summary = sess.run(merge)
file_writer.add_summary(summary,i) # 观察第N步的损失值
# 训练每一步进行模型保存 ckeckpoint类型,而filewrite 是events类型
# 指定目录+模型名字 save默认保存最近5个模型
saver.save(sess,"./temp/ckpt/test/myregression.ckpt")
# 总结:学习率和步长是会决定你的训练最后时间
if __name__ == '__main__':
linear_regression()



增加命令行参数
import tensorflow as tf
import os
tf.app.flags.DEFINE_string("model_path", "./linear_regression/", "模型保存的路径和文件名")
FLAGS = tf.app.flags.FLAGS
def linear_regression():
# 1)准备好数据集:y = 0.8x + 0.7 100个样本
# 特征值X, 目标值y_true
with tf.variable_scope("original_data"):
X = tf.random_normal(shape=(100, 1), mean=2, stddev=2, name="original_data_x")
# y_true [100, 1]
# 矩阵运算 X(100, 1)* (1, 1)= y_true(100, 1)
y_true = tf.matmul(X, [[0.8]], name="original_matmul") + 0.7
# 2)建立线性模型:
# y = W·X + b,目标:求出权重W和偏置b
# 3)随机初始化W1和b1
with tf.variable_scope("linear_model"):
weights = tf.Variable(initial_value=tf.random_normal(shape=(1, 1)), name="weights")
bias = tf.Variable(initial_value=tf.random_normal(shape=(1, 1)), name="bias")
y_predict = tf.matmul(X, weights, name="model_matmul") + bias
# 4)确定损失函数(预测值与真实值之间的误差)-均方误差
with tf.variable_scope("loss"):
error = tf.reduce_mean(tf.square(y_predict - y_true), name="error_op")
# 5)梯度下降优化损失:需要指定学习率(超参数)
# W2 = W1 - 学习率*(方向)
# b2 = b1 - 学习率*(方向)
with tf.variable_scope("gd_optimizer"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01, name="optimizer").minimize(error)
# 2)收集变量
tf.summary.scalar("error", error)
tf.summary.histogram("weights", weights)
tf.summary.histogram("bias", bias)
# 3)合并变量
merge = tf.summary.merge_all()
# 初始化变量
init = tf.global_variables_initializer()
# 开启会话进行训练
with tf.Session() as sess:
# 运行初始化变量Op
sess.run(init)
# 未经训练的权重和偏置
print("随机初始化的权重为%f, 偏置为%f" % (weights.eval(), bias.eval()))
# 当存在checkpoint文件,就加载模型
# 1)创建事件文件
file_writer = tf.summary.FileWriter(logdir="./summary", graph=sess.graph)
# 训练模型
for i in range(100):
sess.run(optimizer)
print("第%d步的误差为%f,权重为%f, 偏置为%f" % (i, error.eval(), weights.eval(), bias.eval()))
# 4)运行合并变量op
summary = sess.run(merge)
file_writer.add_summary(summary, i)
return None
def main(argv):
print("这是main函数")
print(argv)
print(FLAGS.model_path)
linear_regression()
if __name__ == "__main__":
tf.app.run()
这是main函数
['D:/recommend/DL/test111.py']
./linear_regression/
随机初始化的权重为-0.886332, 偏置为-0.116325
第0步的误差为19.785429,权重为-0.573302, 偏置为-0.029748
第1步的误差为16.971621,权重为-0.330289, 偏置为0.037301
第2步的误差为9.083210,权重为-0.095001, 偏置为0.097254
第3步的误差为6.789061,权重为0.074500, 偏置为0.145402
.....
面向对象实现
# 用tensorflow自实现一个线性回归案例
# 定义一些常用的命令行参数# 训练步数
tf.app.flags.DEFINE_integer("max_step", 0, "训练模型的步数")# 定义模型的路径
tf.app.flags.DEFINE_string("model_dir", " ", "模型保存的路径+模型名字")
FLAGS = tf.app.flags.FLAGS
class MyLinearRegression(object):
"""
自实现线性回归
"""
def __init__(self):
pass
def inputs(self):
"""
获取特征值目标值数据数据
:return:
"""
x_data = tf.random_normal([100, 1], mean=1.0, stddev=1.0, name="x_data")
y_true = tf.matmul(x_data, [[0.7]]) + 0.8
return x_data, y_true
def inference(self, feature):
"""
根据输入数据建立模型
:param feature:
:param label:
:return:
"""
with tf.variable_scope("linea_model"):
# 2、建立回归模型,分析别人的数据的特征数量--->权重数量, 偏置b
# 由于有梯度下降算法优化,所以一开始给随机的参数,权重和偏置
# 被优化的参数,必须得使用变量op去定义
# 变量初始化权重和偏置
# weight 2维[1, 1] bias [1]
# 变量op当中会有trainable参数决定是否训练
self.weight = tf.Variable(tf.random_normal([1, 1], mean=0.0, stddev=1.0),
name="weights")
self.bias = tf.Variable(0.0, name='biases')
# 建立回归公式去得出预测结果
y_predict = tf.matmul(feature, self.weight) + self.bias
return y_predict
def loss(self, y_true, y_predict):
"""
目标值和真实值计算损失
:return: loss
"""
# 3、求出我们模型跟真实数据之间的损失
# 均方误差公式
loss = tf.reduce_mean(tf.square(y_true - y_predict))
return loss
def merge_summary(self, loss):
# 1、收集张量的值
tf.summary.scalar("losses", loss)
tf.summary.histogram("w", self.weight)
tf.summary.histogram('b', self.bias)
# 2、合并变量
merged = tf.summary.merge_all()
return merged
def sgd_op(self, loss):
"""
获取训练OP
:return:
"""
# 4、使用梯度下降优化器优化
# 填充学习率:0 ~ 1 学习率是非常小,
# 学习率大小决定你到达损失一个步数多少
# 最小化损失
train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
return train_op
def train(self):
"""
训练模型
:param loss:
:return:
"""
g = tf.get_default_graph()
with g.as_default():
x_data, y_true = self.inputs()
y_predict = self.inference(x_data)
loss = self.loss(y_true, y_predict)
train_op = self.sgd_op(loss)
# 收集观察的结果值
merged = self.merge_summary(loss)
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# 在没训练,模型的参数值
print("初始化的权重:%f, 偏置:%f" % (self.weight.eval(), self.bias.eval()))
# 开启训练
# 训练的步数(依据模型大小而定)
for i in range(FLAGS.max_step):
sess.run(train_op)
# 生成事件文件,观察图结构
file_writer = tf.summary.FileWriter("./tmp/summary/", graph=sess.graph)
print("训练第%d步之后的损失:%f, 权重:%f, 偏置:%f" % (
i,
loss.eval(),
self.weight.eval(),
self.bias.eval()))
# 运行收集变量的结果
summary = sess.run(merged)
# 添加到文件
file_writer.add_summary(summary, i)
if __name__ == '__main__':
lr = MyLinearRegression()
lr.train()
tf.estimator
TensorFlow 中的 tf.estimator API 封装了基础的机器学习模型。Estimator 是可扩展性最强且面向生产的 TensorFlow 模型类型。Estimator 会封装下列操作:
训练
评估
预测
导出以供使用
Estimator 的优势
Estimator 具有下列优势:
- 可以在本地主机上或分布式多服务器环境中运行基于 Estimator 的模型,而无需更改模型。此外,可以在 CPU、GPU 或 TPU 上运行基于 Estimator 的模型,而无需重新编码模型。
- Estimator 简化了在模型开发者之间共享实现的过程。
- 可以使用高级直观代码开发先进的模型。简言之,采用 Estimator 创建模型通常比采用低阶 TensorFlow API 更简单。
- Estimator 本身在 tf.layers 之上构建而成,可以简化自定义过程。
- Estimator 会构建图。
- Estimator 提供安全的分布式训练循环,可以控制如何以及何时:
- 构建图
- 初始化变量
- 开始排队
- 处理异常
- 创建检查点文件并从故障中恢复
- 保存 TensorBoard 的摘要
使用 Estimator 编写应用时,必须将数据输入管道从模型中分离出来。这种分离简化了不同数据集的实验流程。
预创建的 Estimator
借助预创建的 Estimator,能够在比基本 TensorFlow API 高级很多的概念层面上进行操作。由于 Estimator 会处理所有“管道工作”,因此您不必再为创建计算图或会话而操心。也就是说,预创建的 Estimator 会创建和管理 Graph 和 Session 对象。此外,借助预创建的 Estimator,只需稍微更改下代码,就可尝试不同的模型架构。例如,DNNClassifier 是一个预创建的 Estimator 类,它根据密集的前馈神经网络训练分类模型。
预创建的 Estimator 程序的结构
依赖预创建的 Estimator 的 TensorFlow 程序通常包含下列四个步骤:
1.编写一个或多个数据集导入函数。 例如,创建一个函数来导入训练集,并创建另一个函数来导入测试集。每个数据集导入函数都必须返回两个对象:
- 一个字典,其中键是特征名称,值是包含相应特征数据的张量(或 SparseTensor)
- 一个包含一个或多个标签的张量 **
def input_fn(dataset):
... # manipulate dataset, extracting the feature dict and the label
return feature_dict, label
2.定义特征列。 每个 tf.feature_column 都标识了特征名称、特征类型和任何输入预处理操作。例如,以下代码段创建了三个存储整数或浮点数据的特征列。前两个特征列仅标识了特征的名称和类型。第三个特征列还指定了一个 lambda,该程序将调用此 lambda 来调节原始数据:
population = tf.feature_column.numeric_column('population')
crime_rate = tf.feature_column.numeric_column('crime_rate')
median_education = tf.feature_column.numeric_column('median_education',
normalizer_fn=lambda x: x - global_education_mean)
3.实例化相关的预创建的 Estimator。 例如,下面是对名为 LinearClassifier 的预创建 Estimator 进行实例化的示例代码:
estimator = tf.estimator.LinearClassifier(
feature_columns=[population, crime_rate, median_education],
)
4.调用训练、评估或推理方法。例如,所有 Estimator 都提供训练模型的 train 方法。
# my_training_set is the function created in Step 1estimator.train(input_fn=my_training_set, steps=2000)
Premade Estimators
pre-made Estimators是基类tf.estimator.Estimator的子类,而定制的estimators是tf.estimator.Estimator的实例:

pre-made Estimators是已经做好的。但有时候,需要对一个Estimator的行为做更多控制。这时候就需要定制Estimators了。可以创建一个定制版的Estimator来做任何事。如果希望hidden layers以某些不常见的方式进行连接,可以编写一个定制的Estimator。如果想要模型计算一个唯一的metric,可以编写一个定制的Estimator。基本上,如果想为特定的问题进行优化,可编写一个定制的Estimator。
案例:使用美国普查数据分类
1994 年和 1995 年的美国普查收入数据集。解决的是二元分类问题,目标标签为:如果收入超过 5 万美元,则该值为 1;否则,该值为 0。
- ‘train’: 32561
- ‘validation’: 16281

这些列分为两类 - 类别列和连续列: - 如果某个列的值只能是一个有限集合中的类别之一,则该列称为类别列。例如,婚恋状况(妻子、丈夫、未婚等)或受教育程度(高中、大学等)属于类别列。
- 如果某个列的值可以是连续范围内的任意数值,则该列称为连续列。例如,一个人的资本收益(如 14084 美元)属于连续列。
案例实现
读取美国普查收入数据
tf.data API可以很方便地以不同的数据格式处理大量的数据,以及处理复杂的转换。
- 读取csv文件接口:tf.data.TextLineDataset()
- 路径+文件名称列表
- 返回:Dataset结构
数据设置
import tensorflow as tf
import os
# 普查数据列名
_CSV_COLUMNS = [
'age', 'workclass', 'fnlwgt', 'education', 'education_num',
'marital_status', 'occupation', 'relationship', 'race', 'gender',
'capital_gain', 'capital_loss', 'hours_per_week', 'native_country',
'income_bracket'
] # 指定特征值列名
# 解码数据,默认值
# 读取数据时候进行默认值处理,int类型为0,str类型为空
_CSV_COLUMN_DEFAULTS = [[0], [''], [0], [''], [0], [''], [''], [''], [''], [''],
[0], [0], [0], [''], ['']]
# 指定训练和测试数据目录
train_file = './data/adult.data'
test_file = './data/adult.test'
输入函数
# 1.读取数据函数 input_func(文件名,循环训练次数,批处理大小)
def input_func(file,epoches,batch_size):
"""
tf.data读取数据,并处理数据格式,返回dataset迭代器
:return:
"""
# 定义数据处理函数
def decode_train_data(row):
# 解析文本数据 tf.decode_csv()
data = tf.decode_csv(row,record_defaults=_CSV_COLUMN_DEFAULTS)
# 进行字典映射,其中键是特征名称,值是包含相应特征数据的张量(或 SparseTensor)
feature_dict = dict(zip(_CSV_COLUMNS,data))
# 提取最后一列目标列
label = feature_dict.pop('income_bracket')
# tf.equal(a,b) 若str_a == str_b ,返回1,否则0
labels = tf.equal(label,">50K")
# 返回:特征数据组成的字典,目标值
return feature_dict,labels
dataset = tf.data.TextLineDataset(file)
# map,repeat,batch tf.data
dataset = dataset.map(decode_train_data)
# repeat 重复所有样本次数即循环训练次数,batch_size:1000,16/32/64/128个样本一组,分N组 Batch Size定义:分批训练,一次训练所选取的样本数。
dataset = dataset.repeat(epoches)
dataset = dataset.batch(batch_size)
return dataset
模型选择特征并进行特征工程处理
Estimator 使用名为特征列的机制来描述模型应如何解读每个原始输入特征。Estimator 需要数值输入向量,而特征列会描述模型应如何转换每个特征。
选择和创建一组正确的特征列是学习有效模型的关键。特征列可以是原始特征 dict 中的其中一个原始输入(基准特征列),也可以是对一个或多个基准列进行转换而创建的任意新列(衍生特征列)。
特征列是一个抽象概念,表示可用于预测目标标签的任何原始变量或衍生变量。
- 数值列
最简单的 feature_column 是 numeric_column。它表示特征是数值,应直接输入到模型中。例如:
age = tf.feature_column.numeric_column('age')
education_num = tf.feature_column.numeric_column('education_num')
capital_gain = tf.feature_column.numeric_column('capital_gain')
capital_loss = tf.feature_column.numeric_column('capital_loss')
hours_per_week = tf.feature_column.numeric_column('hours_per_week')
numeric_columns = [age, education_num, capital_gain, capital_loss, hours_per_week]
- 类别列
要为类别特征定义特征列,请使用其中一个 tf.feature_column.categorical_column* 函数创建 CategoricalColumn。如果知道某个列的所有可能特征值的集合,并且集合中只有几个值,请使用 categorical_column_with_vocabulary_list。列表中的每个键会被分配自动递增的 ID(从 0 开始)。例如,对于 relationship 列,可以将整数 ID 0 分配给特征字符串 Husband,将 1 分配给“Not-in-family”,以此类推。- tf.feature_column.categorical_column_with_vocabulary_list: 指定所有类别字符串,对应到具体类别
- tf.feature_column.categorical_column_with_hash_bucket:类别数量过多不确定到底有多少类别,指定一个hash_bucket_size作为上限
relationship = tf.feature_column.categorical_column_with_vocabulary_list(
'relationship',
['Husband', 'Not-in-family', 'Wife', 'Own-child', 'Unmarried', 'Other-relative'])
occupation = tf.feature_column.categorical_column_with_hash_bucket(
'occupation', hash_bucket_size=1000)
education = tf.feature_column.categorical_column_with_vocabulary_list(
'education', [
'Bachelors', 'HS-grad', '11th', 'Masters', '9th', 'Some-college',
'Assoc-acdm', 'Assoc-voc', '7th-8th', 'Doctorate', 'Prof-school',
'5th-6th', '10th', '1st-4th', 'Preschool', '12th'])
marital_status = tf.feature_column.categorical_column_with_vocabulary_list(
'marital_status', [
'Married-civ-spouse', 'Divorced', 'Married-spouse-absent',
'Never-married', 'Separated', 'Married-AF-spouse', 'Widowed'])
workclass = tf.feature_column.categorical_column_with_vocabulary_list(
'workclass', [
'Self-emp-not-inc', 'Private', 'State-gov', 'Federal-gov',
'Local-gov', '?', 'Self-emp-inc', 'Without-pay', 'Never-worked'])
categorical_columns = [relationship, occupation, education, marital_status, workclass]
# 2.模型选择和特征处理,数据必须每列指定类别:连续列和类别列即连续型和离散型
def get_feature_column():
# 对于普查数据进行特征列指定
# 连续型特征 --连续列
age = tf.feature_column.numeric_column('age')
education_num = tf.feature_column.numeric_column('education_num')
capital_gain = tf.feature_column.numeric_column('capital_gain')
capital_loss = tf.feature_column.numeric_column('capital_loss')
hours_per_week = tf.feature_column.numeric_column('hours_per_week')
numeric_column = [age,education_num,capital_gain,capital_loss,hours_per_week]
# 离散型--类别列
# tf.feature_column.categorical_column_with_vocabulary_list: 指定所有类别字符串,对应到具体类别
# tf.feature_column.categorical_column_with_hash_bucket:类别数量过多不确定到底有多少类别,指定一个hash_bucket_size作为上限
workclass = tf.feature_column.categorical_column_with_vocabulary_list\
('workclass',[
'Self-emp-not-inc', 'Private', 'State-gov', 'Federal-gov',
'Local-gov', '?', 'Self-emp-inc', 'Without-pay', 'Never-worked'])
occupation = tf.feature_column.categorical_column_with_hash_bucket('occupation',hash_bucket_size=1000)
marital_status = tf.feature_column.categorical_column_with_vocabulary_list\
('marital_status',['Married-civ-spouse', 'Divorced', 'Married-spouse-absent',
'Never-married', 'Separated', 'Married-AF-spouse', 'Widowed'])
education = tf.feature_column.categorical_column_with_vocabulary_list\
('education',[
'Bachelors', 'HS-grad', '11th', 'Masters', '9th', 'Some-college',
'Assoc-acdm', 'Assoc-voc', '7th-8th', 'Doctorate', 'Prof-school',
'5th-6th', '10th', '1st-4th', 'Preschool', '12th'])
relationship = tf.feature_column.categorical_column_with_vocabulary_list\
(
'relationship',[
'Husband', 'Not-in-family', 'Wife', 'Own-child', 'Unmarried', 'Other-relative'])
categorical_columns = [relationship, occupation, education, marital_status, workclass]
return numeric_column + categorical_columns
模型训练与评估
输入到train当中的train_inpf只是将函数名称放入,如要将原先的input_fn中参数进行取出。可以使用该方法functools.partial方法
import functools
def add(a, b):
return a + b
add(4, 2)
6
plus3 = functools.partial(add, 3)
plus5 = functools.partial(add, 5)
plus3(4)
7
plus3(7)
10
plus5(10)
15
partial方法使用在数据集
import functools
# input_func三个参数,通过partial(函数名,该函数的参数) 指定默认值,调用时候不需要再传递参数
train_input = functools.partial(input_func,train_file,epoches=3,batch_size=32) # 训练集
test_input = functools.partial(input_func, test_file, epoches=1, batch_size=32) # 测试集
tf.estimator进行初始化训练评估:
# 训练评估
estimator = tf.estimator.LinearClassifier(feature_columns=columns)
estimator.train(train_input)
res = estimator.evaluate(test_input)
print(res)
for key,value in sorted(res.items()):
print('%s,%s,'%(key,value))
完成实现
import tensorflow as tf
import os
# 普查数据列名
_CSV_COLUMNS = [
'age', 'workclass', 'fnlwgt', 'education', 'education_num',
'marital_status', 'occupation', 'relationship', 'race', 'gender',
'capital_gain', 'capital_loss', 'hours_per_week', 'native_country',
'income_bracket'
] # 指定特征值列名
# 解码数据,默认值
# 读取数据时候进行默认值处理,int类型为0,str类型为空
_CSV_COLUMN_DEFAULTS = [[0], [''], [0], [''], [0], [''], [''], [''], [''], [''],
[0], [0], [0], [''], ['']]
# 指定训练和测试数据目录
train_file = './data/adult.data'
test_file = './data/adult.test'
# 1.读取数据函数 input_func(文件名,循环训练次数,批处理大小)
def input_func(file,epoches,batch_size):
"""
tf.data读取数据,并处理数据格式,返回dataset迭代器
:return:
"""
# 定义数据处理函数
def decode_train_data(row):
# 解析文本数据 tf.decode_csv()
data = tf.decode_csv(row,record_defaults=_CSV_COLUMN_DEFAULTS)
# 进行字典映射,其中键是特征名称,值是包含相应特征数据的张量(或 SparseTensor)
feature_dict = dict(zip(_CSV_COLUMNS,data))
# 提取最后一列目标列
label = feature_dict.pop('income_bracket')
# tf.equal(a,b) 若str_a == str_b ,返回1,否则0
labels = tf.equal(label,">50K")
# 返回:特征数据组成的字典,目标值
return feature_dict,labels
dataset = tf.data.TextLineDataset(file)
# map,repeat,batch tf.data
dataset = dataset.map(decode_train_data)
# repeat 重复所有样本次数即循环训练次数,batch_size:1000,16/32/64/128个样本一组,分N组 Batch Size定义:分批训练,一次训练所选取的样本数。
dataset = dataset.repeat(epoches)
dataset = dataset.batch(batch_size)
return dataset
# 2.模型选择和特征处理,数据必须每列指定类别:连续列和类别列即连续型和离散型
def get_feature_column():
# 对于普查数据进行特征列指定
# 连续型特征 --连续列
age = tf.feature_column.numeric_column('age')
education_num = tf.feature_column.numeric_column('education_num')
capital_gain = tf.feature_column.numeric_column('capital_gain')
capital_loss = tf.feature_column.numeric_column('capital_loss')
hours_per_week = tf.feature_column.numeric_column('hours_per_week')
numeric_column = [age,education_num,capital_gain,capital_loss,hours_per_week]
# 离散型--类别列
# tf.feature_column.categorical_column_with_vocabulary_list: 指定所有类别字符串,对应到具体类别
# tf.feature_column.categorical_column_with_hash_bucket:类别数量过多不确定到底有多少类别,指定一个hash_bucket_size作为上限
workclass = tf.feature_column.categorical_column_with_vocabulary_list\
('workclass',[
'Self-emp-not-inc', 'Private', 'State-gov', 'Federal-gov',
'Local-gov', '?', 'Self-emp-inc', 'Without-pay', 'Never-worked'])
occupation = tf.feature_column.categorical_column_with_hash_bucket('occupation',hash_bucket_size=1000)
marital_status = tf.feature_column.categorical_column_with_vocabulary_list\
('marital_status',['Married-civ-spouse', 'Divorced', 'Married-spouse-absent',
'Never-married', 'Separated', 'Married-AF-spouse', 'Widowed'])
education = tf.feature_column.categorical_column_with_vocabulary_list\
('education',[
'Bachelors', 'HS-grad', '11th', 'Masters', '9th', 'Some-college',
'Assoc-acdm', 'Assoc-voc', '7th-8th', 'Doctorate', 'Prof-school',
'5th-6th', '10th', '1st-4th', 'Preschool', '12th'])
relationship = tf.feature_column.categorical_column_with_vocabulary_list\
(
'relationship',[
'Husband', 'Not-in-family', 'Wife', 'Own-child', 'Unmarried', 'Other-relative'])
categorical_columns = [relationship, occupation, education, marital_status, workclass]
return numeric_column + categorical_columns
if __name__ == '__main__':
# 1、读取美国普查收入数据
# 打印出来的是一批次的数据形状(32,)
# print(input_func(train_file,3,32))
# tran_file文件中的样本,循环训练3次即共3000个样本,每组32个样本
# 2、模型选择特征并进行特征工程处理
columns = get_feature_column()
# 3、模型训练与评估
estimator = tf.estimator.LinearClassifier(feature_columns=columns)
# estimator.train或者evaluate
# 训练数据输入函数不能有参数,采用functools解决
import functools
# input_func三个参数,通过partial(函数名,该函数的参数) 指定默认值,调用时候不需要再传递参数
train_input = functools.partial(input_func,train_file,epoches=3,batch_size=32) # 训练集
test_input = functools.partial(input_func, test_file, epoches=1, batch_size=32) # 测试集
# 训练评估
estimator.train(train_input)
res = estimator.evaluate(test_input)
print(res)
for key,value in sorted(res.items()):
print('%s,%s,'%(key,value))
{'accuracy': 0.8499478, 'accuracy_baseline': 0.76377374, 'auc': 0.9000656, 'auc_precision_recall': 0.75544393, 'average_loss': 0.3399393, 'label/mean': 0.23622628, 'loss': 10.873383, 'precision': 0.7401575, 'prediction/mean': 0.2092093, 'recall': 0.5621425, 'global_step': 3053}
accuracy,0.8499478,
accuracy_baseline,0.76377374,
auc,0.9000656,
auc_precision_recall,0.75544393,
average_loss,0.3399393,
global_step,3053,
label/mean,0.23622628,
loss,10.873383,
precision,0.7401575,
prediction/mean,0.2092093,
recall,0.5621425,















 2536
2536











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









