







原文链接
其他推荐链接:准确率、精确率、召回率、F1值、ROC/AUC整理笔记
1. 直接复制的原文,非常感谢原作者!
声纹识别算法的技术指标
声纹识别在算法层面可通过如下基本的技术指标来判断其性能,除此之外还有其它的一些指标,如:信道鲁棒性、时变鲁棒性、假冒攻击鲁棒性、群体普适性等指标,这部分后续于详细展开讲解。
-
错误拒绝率(False Rejection Rate,
FRR):分类问题中,若两个样本为同类(同一个人),却被系统误认为异类(非同一个人),则为错误拒绝案例。错误拒绝率为错误拒绝案例在所有同类匹配案例的比例。 -
错误接受率(False Acceptance Rate, FAR)
:分类问题中,若两个样本为异类(非同一个人),却被系统误认为同类(同一个人),则为错误接受案例。错误接受率为错误接受案例在所有异类匹配案例的比例。 -
等错误率(Equal Error Rate,EER):调整阈值,使得误拒绝率(False Rejection
Rate,FRR)等于误接受率(False Acceptance Rate,FAR),此时的FAR与FRR的值称为等错误率。 -
准确率(Accuracy,ACC):调整阈值,使得FAR+FRR最小,1减去这个值即为识别准确率,即ACC=1 – min(FAR+FRR)
-
速度:(提取速度:提取声纹速度与音频时长有关、验证比对速度):Real Time Factor 实时比(衡量提取时间跟音频时长的关系,比如:1秒能够处理80s的音频,那么实时比就是1:80)。验证比对速度是指平均每秒钟能进行的声纹比对次数。
-
ROC曲线:描述FAR与FRR之间相互变化关系的曲线,X轴为FAR的值,Y轴为FRR的值。从左到右,当阈值增长期间,每一个时刻都有一对FAR和FRR的值,将这些值在图上描点连成一条曲线,就是ROC曲线。
-
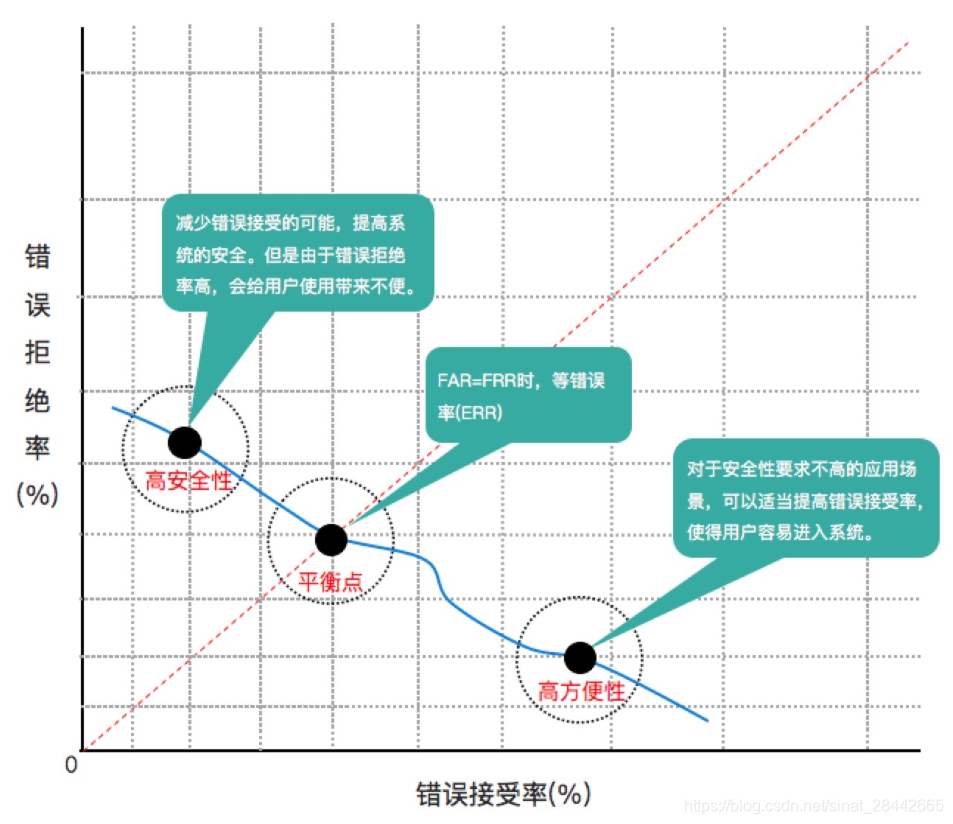
阈值:在接受/拒绝二元分类系统中,通常会设定一个阈值,分数超过该值时才做出接受决定。调节阈值可以根据业务需求平衡FAR与FRR。
当设定高阈值时,系统做出接受决定的得分要求较为严格,FAR降低,FRR升高;当设定低阈值时,系统做出接受决定的得分要求较为宽松,FAR升高,FRR降低。在不同应用场景下,调整不同的阈值,则可在安全性和方便性间平平衡,如下图所示:
影响声纹识别水平的因素
训练数据和算法是影响声纹识别水平的两个重要因素,在应用落地过程中,还会受很多因素的影响。
-
声源采样率:
人类语音的频段集中于50Hz ~ 8KHz之间,尤其在4KHz以下频段
离散信号覆盖频段为信号采样率的一半(奈奎斯特采样定理)。
采样率越高,信息量越大。
常用采样率:8KHz (即0 ~ 4KHz频段),16KHz(即0 ~ 8KHz频段)。
-
信噪比(SNR): 信噪比衡量一段音频中语音信号与噪声的能量比,即语音的干净程度:
15dB以上(基本干净)
6dB(嘈杂)
0dB(非常吵)
-
信道: 不同的采集设备,以及通信过程会引入不同的失真。
声纹识别算法与模型需要覆盖尽可能多的信道。
手机麦克风、桌面麦克风、固话、移动通信(CDMA, TD-LTE等)、微信……
-
语音时长: 语音时长(包括注册语音条数)会影响声纹识别的精度。
有效语音时长越长,算法得到的数据越多,精度也会越高。
短语音(1~3s)
长语音(20s+)
-
文本内容: 通俗地说,声纹识别系统通过比对两段语音的说话人在相同音素上的发声来判断是否为同一个人。
固定文本:注册与验证内容相同
半固定文本:内容一样但顺序不同;文本属于固定集合
自由文本

















 1000
1000

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









