







今天有个朋友向我求助,希望我帮他爬取一个网站上的内容。网站内容如下:
aHR0cHM6Ly93d3cuY2NwcmVjLmNvbS9uYXZDcXpyLyMvCg==
打开上述网址,进入开发者模式,这些数据的请求接口,正常逻辑是通过搜索页面上内容进行锁定请求接口。但是,进行搜索时,发现什么都搜索不到。
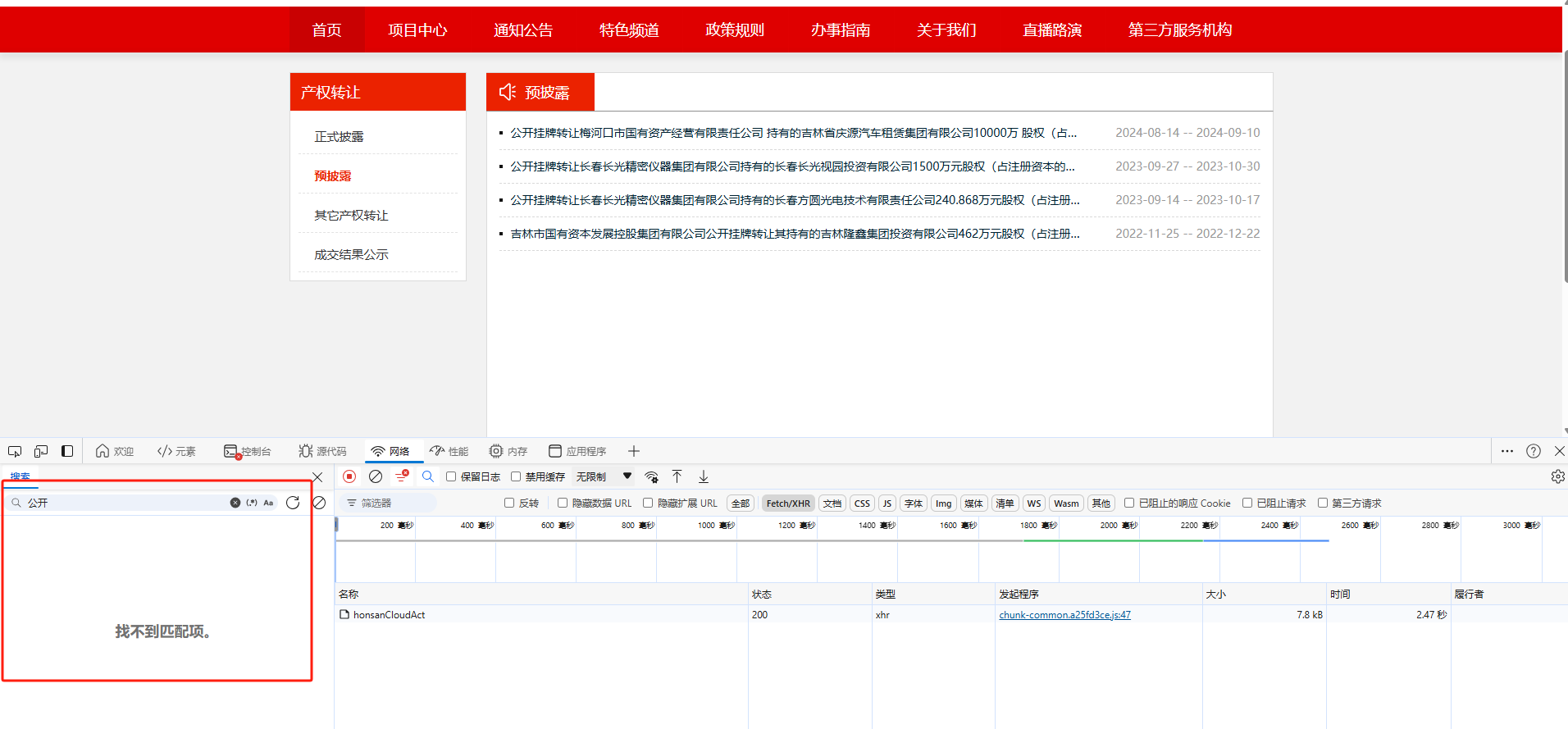
通过上图发现,这些数据只请求了一个接口,当我点击负载和响应这两个标签,发现数据是被加密了,所以,我们搜索不了页面的内容。
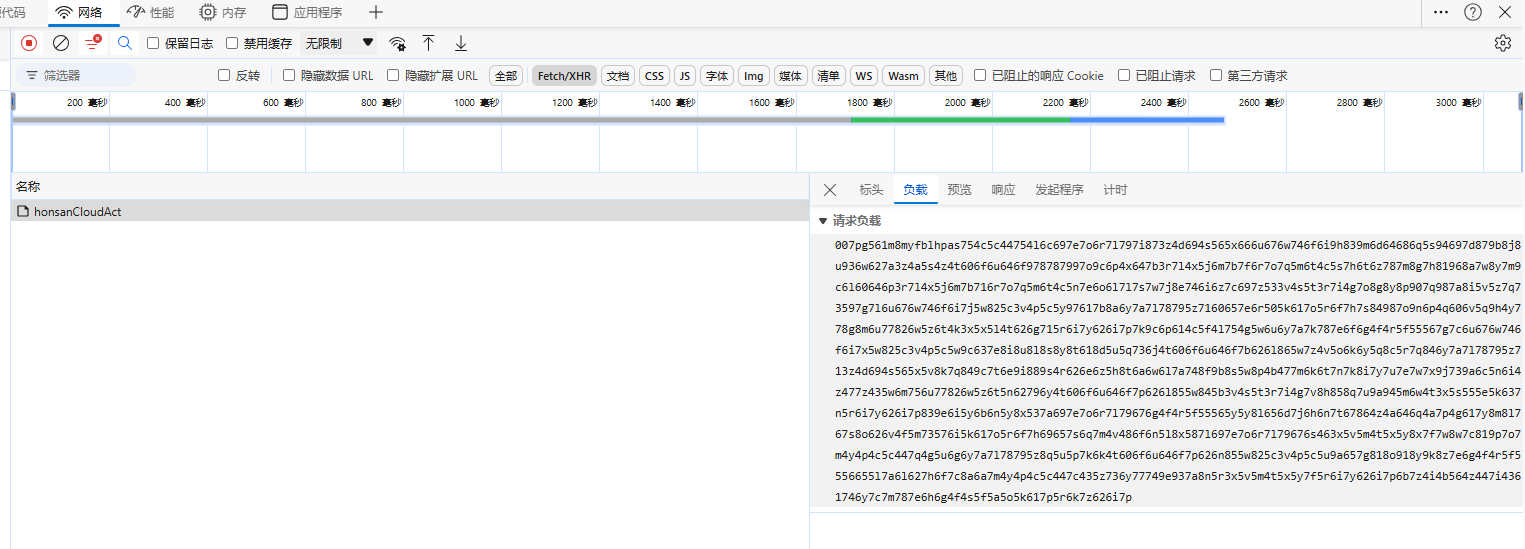
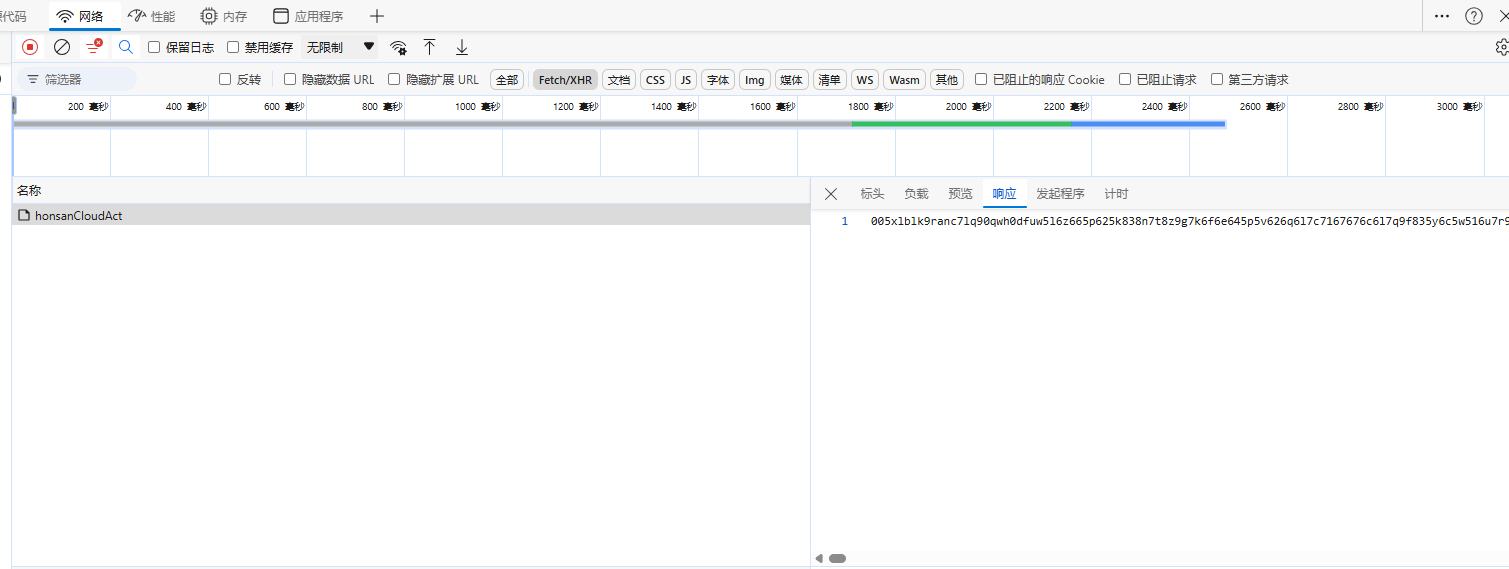
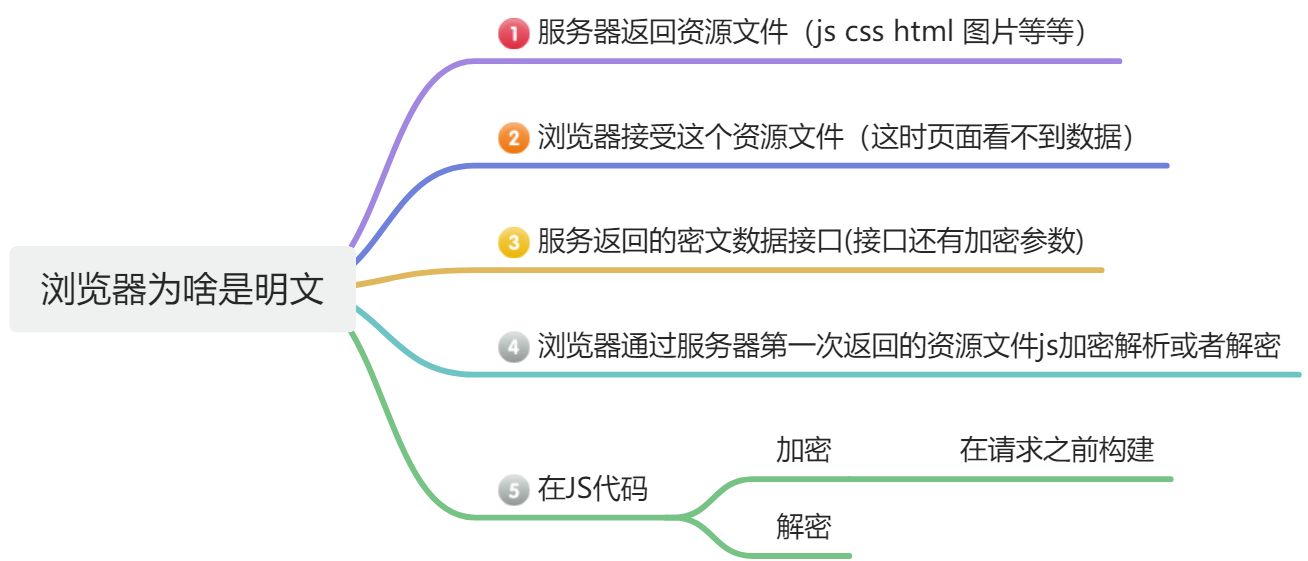
浏览器为啥是明文?
这时相信小伙伴,心中都有一个疑问浏览器为啥是明文? 浏览器在收到数据后,会自动采用服务器返回的资源文件对加密内容进行解密并显示明文,这也是我们能够在页面上看到正常内容的原因。
如何定位到加密资源文件
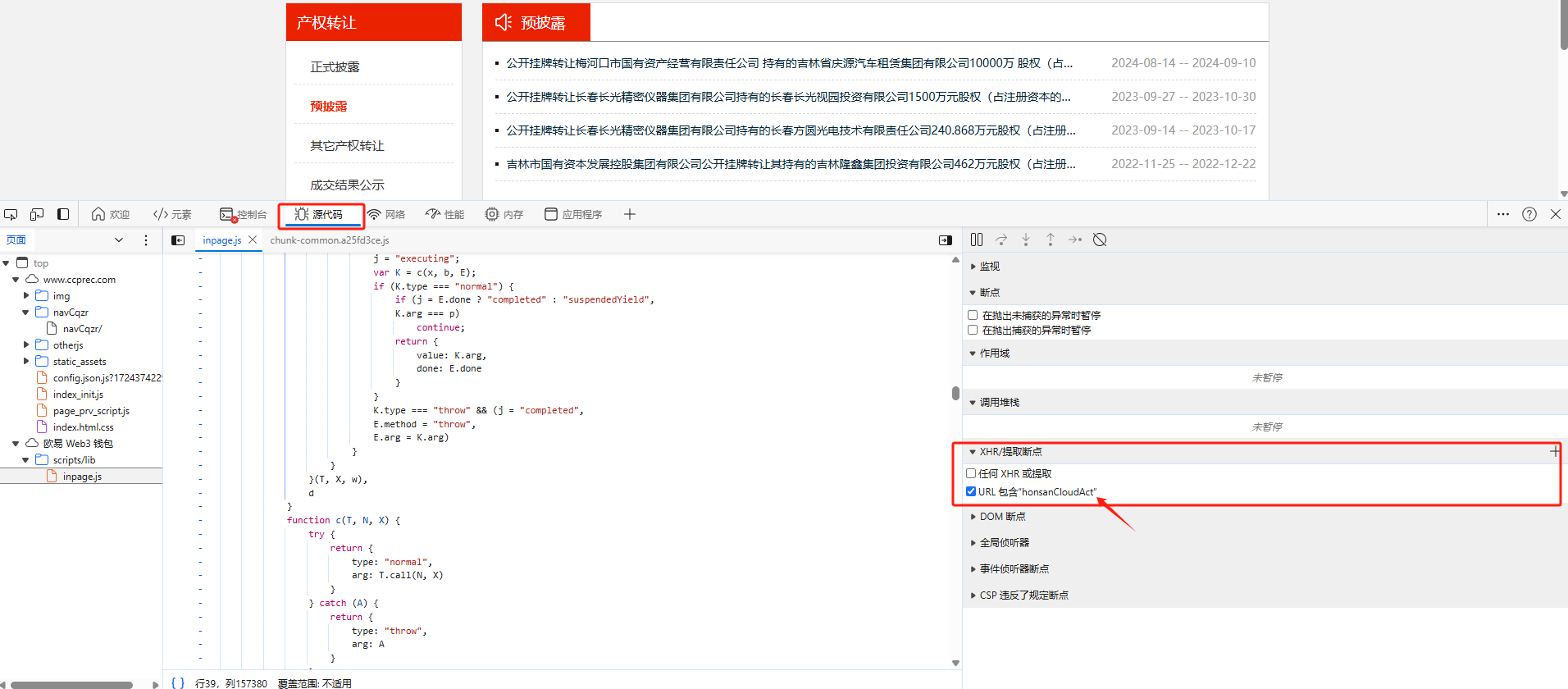
通过XHR/提取断点,该方法是通过匹配URL包括请求路径关键字进行断点,具体配置如下图:
这时我们重新刷新网页,如下图所示,网站就成功进入我们上一步设置的断点中。
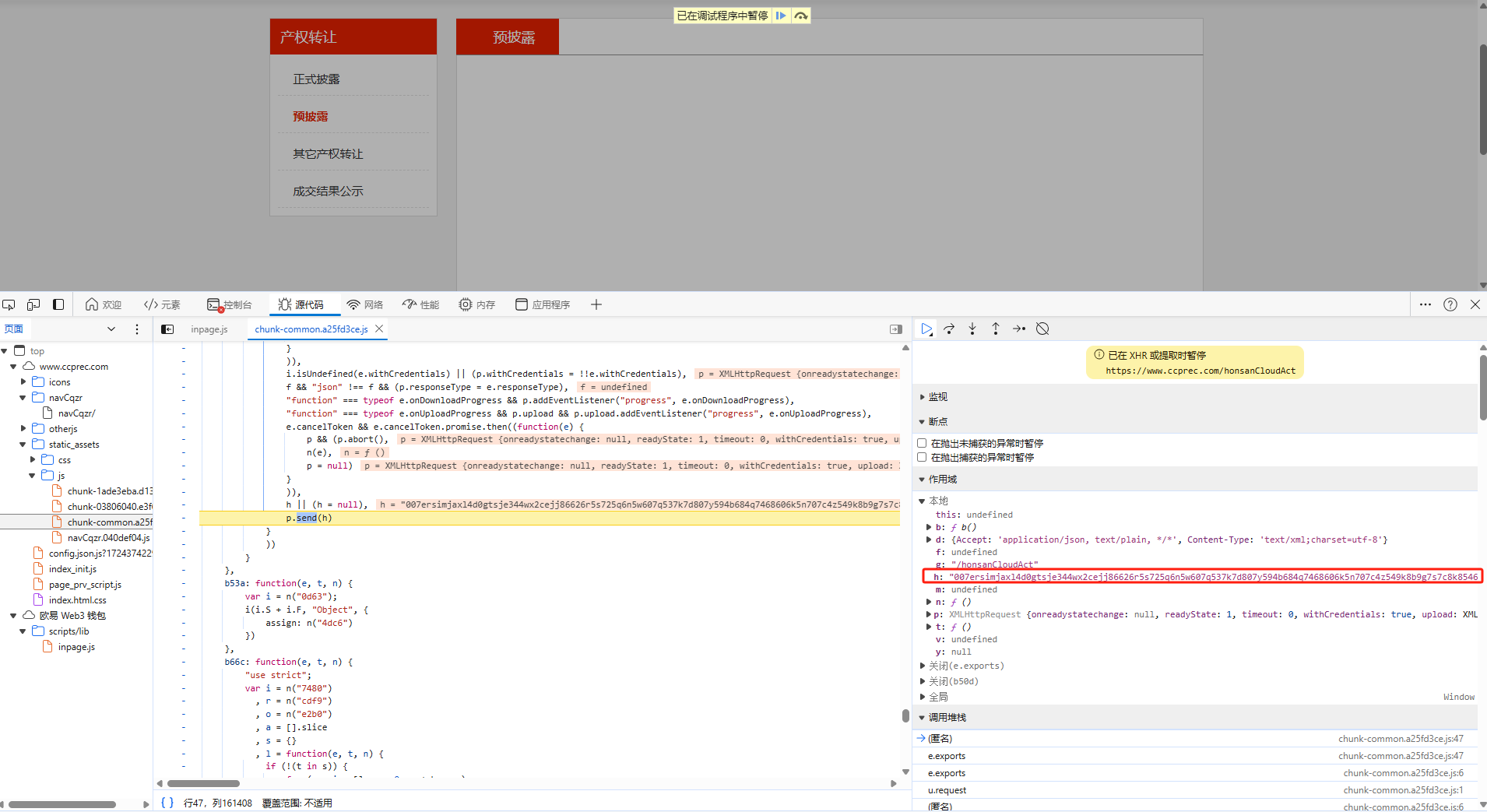
其中,h就是加密后的请求体参数,然后我们从调用堆栈中一步步往前推找。至于如何找呢?这里是有一个技巧的,我们需要找到前一步请求体还没加密,后一步请求体就加密成功了。
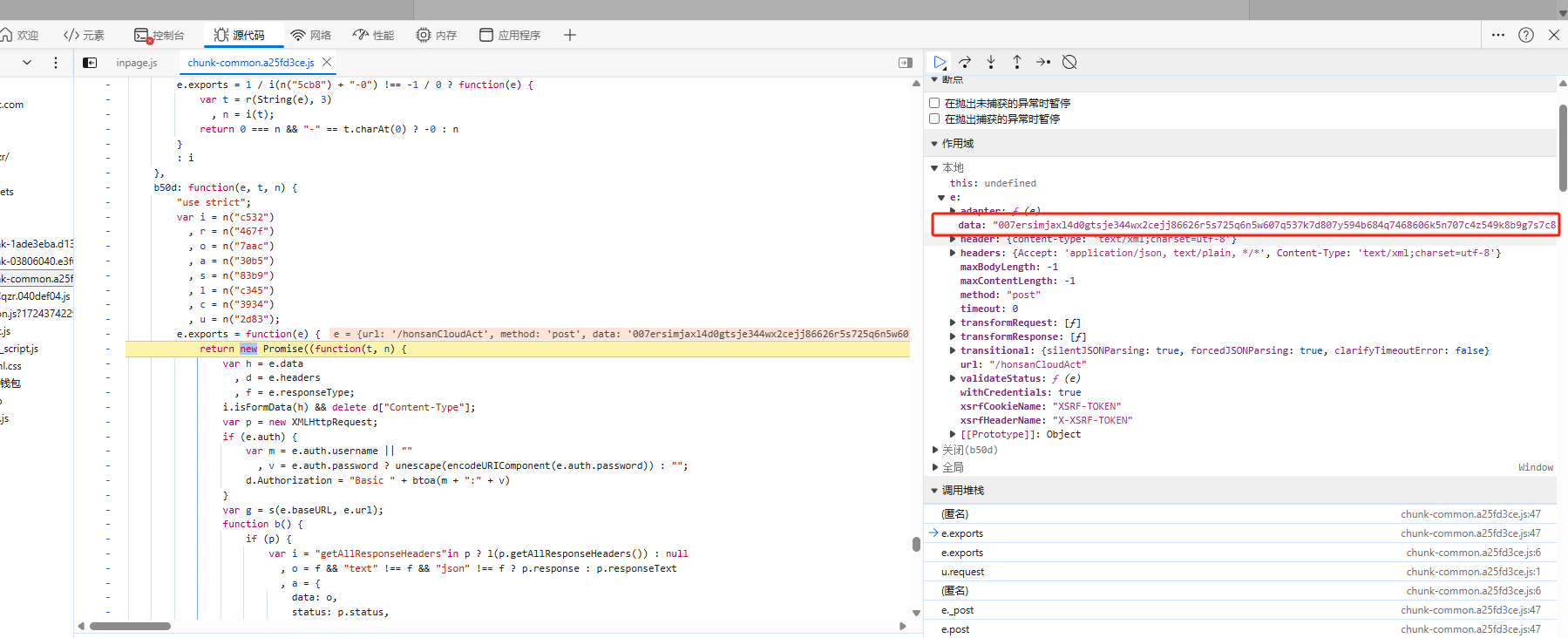
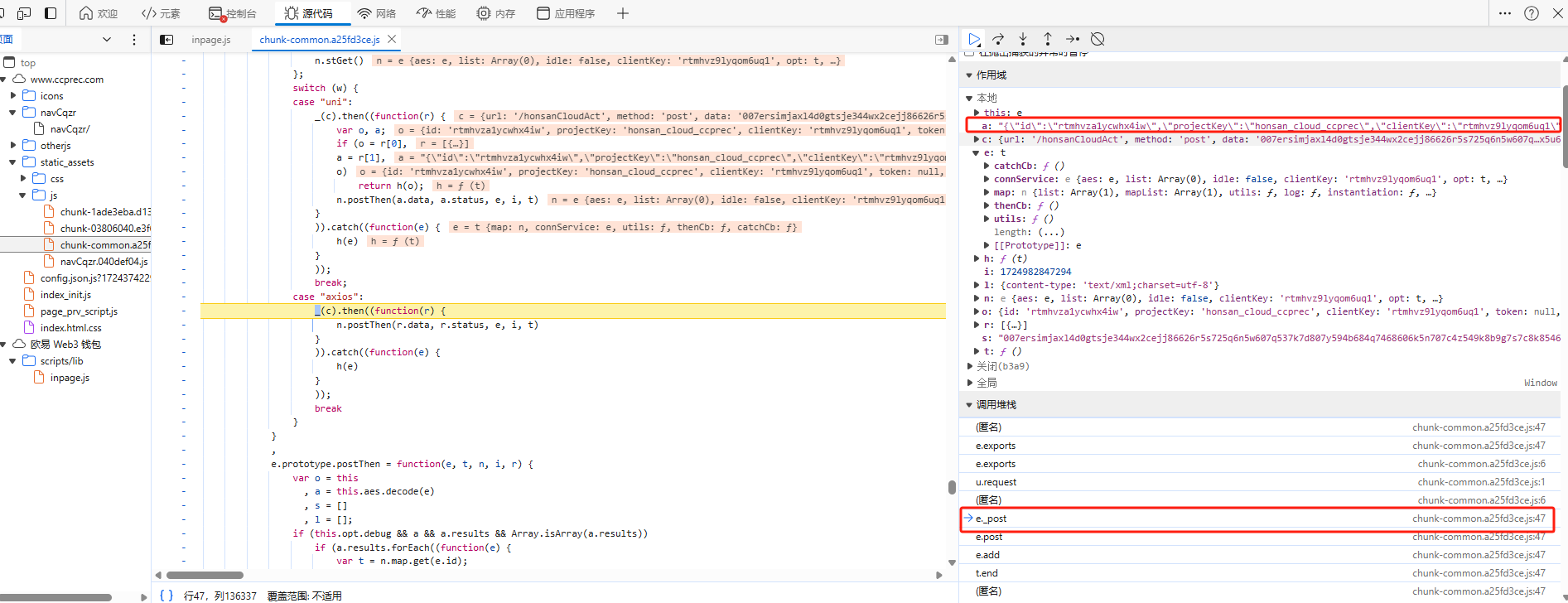
其中上图
o就是请求体加密之前的参数,s就是加密后的参数。chunk-common.a25fd3ce.js就是进行加密的js。通过点击堆栈的js名称就可以定位到对应的地方。
扣取代码
经过上一步分析,我们知道o就是加密之前的参数,就在js代码找o定义的位置,如下图所示:
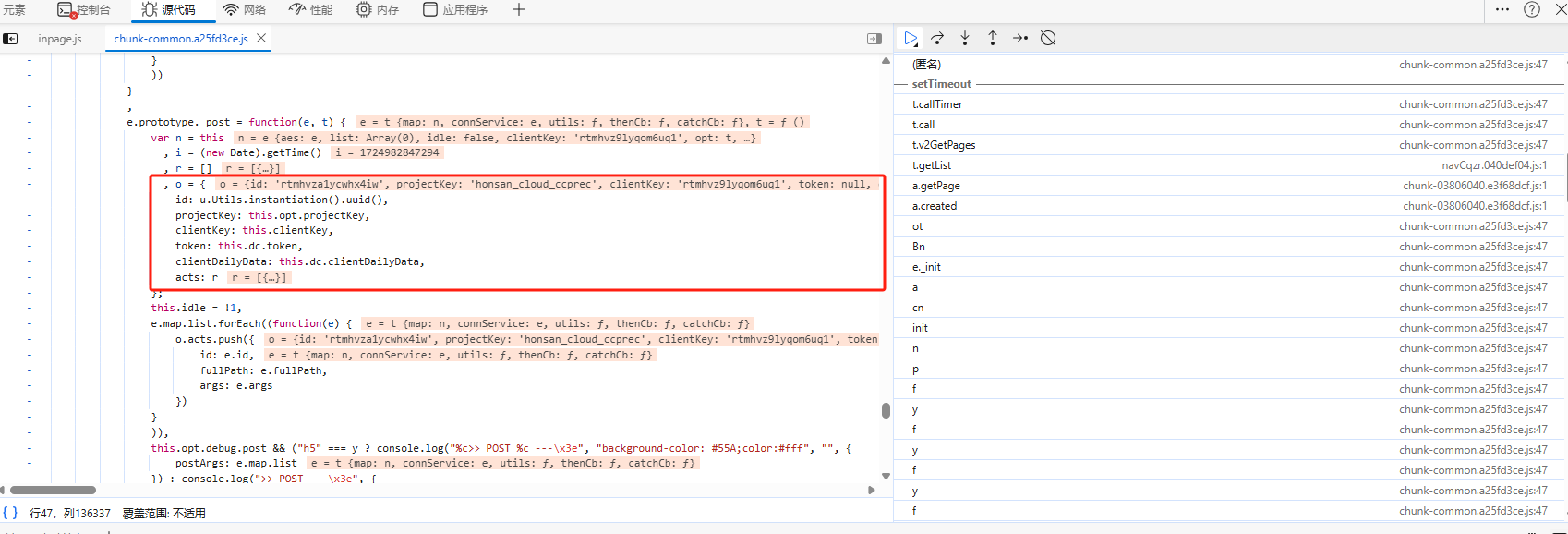
下面代码就是请求体的参数,通过上述代码发现id是通过uuid方法生成的。
{
"id": "rtmhwib79r4ytdgn",
"projectKey": "honsan_cloud_ccprec",
"clientKey": "rtmhwialwggc91l6",
"token": null,
"clientDailyData": {
},
"acts":  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1039
1039

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











