







 本文详细介绍BW中数据存储对象(DSO)与转换的设置及应用,包括转换规则类型、聚合方式、例程编写等内容,并介绍了数据传输进程(DTP)、持久数据缓存区(PSA)的工作原理和数据抽取流程。
本文详细介绍BW中数据存储对象(DSO)与转换的设置及应用,包括转换规则类型、聚合方式、例程编写等内容,并介绍了数据传输进程(DTP)、持久数据缓存区(PSA)的工作原理和数据抽取流程。
bw项目抱佛脚入门资料-4.数据存储对象和转换
前言
温习一下,前面说了基础理论,然后说了怎么按照业务提供的指标先建立数据存储对象,也讲了怎么建立抽数用的数据源,这篇说说怎么把业务逻辑转为我们数据存储对象跟数据源之间的转换,也就是说怎么抽取数据。
一、DSO和转换
在DSO数据存储对象右击,新建转换,根据DSO和数据源字段的对应关系,手工拖动字段、连线,就形成了转换映射。
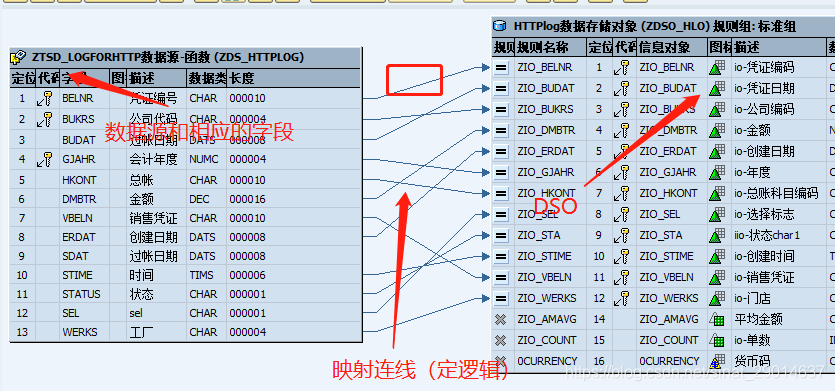
这些连线就是"转换规则",双击连线弹出来详细信息:

源字段(数据源)是支持多对一的,DSO字段是唯一的
二、转换相关字段映射设置
1.规则类型
直接分配——字段结构一致,可以选择直接映射,抽取时候直接抽
常数——无论数据源是什么,DSO抽取都是指定的常数
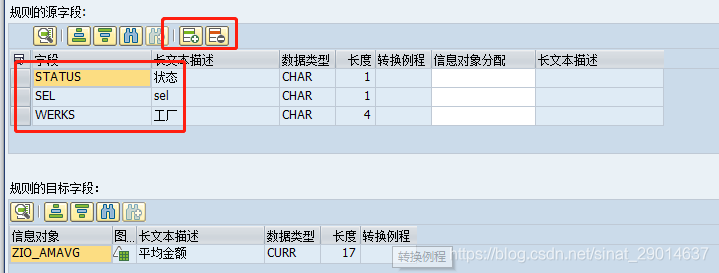
公式——可以设置简单的公式(DSO字段=数据源字段运算)
读取主数据——根据数据源字段值获取定义好的主数据的信息对象
从数据存储取得——用的少,是从DSO等获取
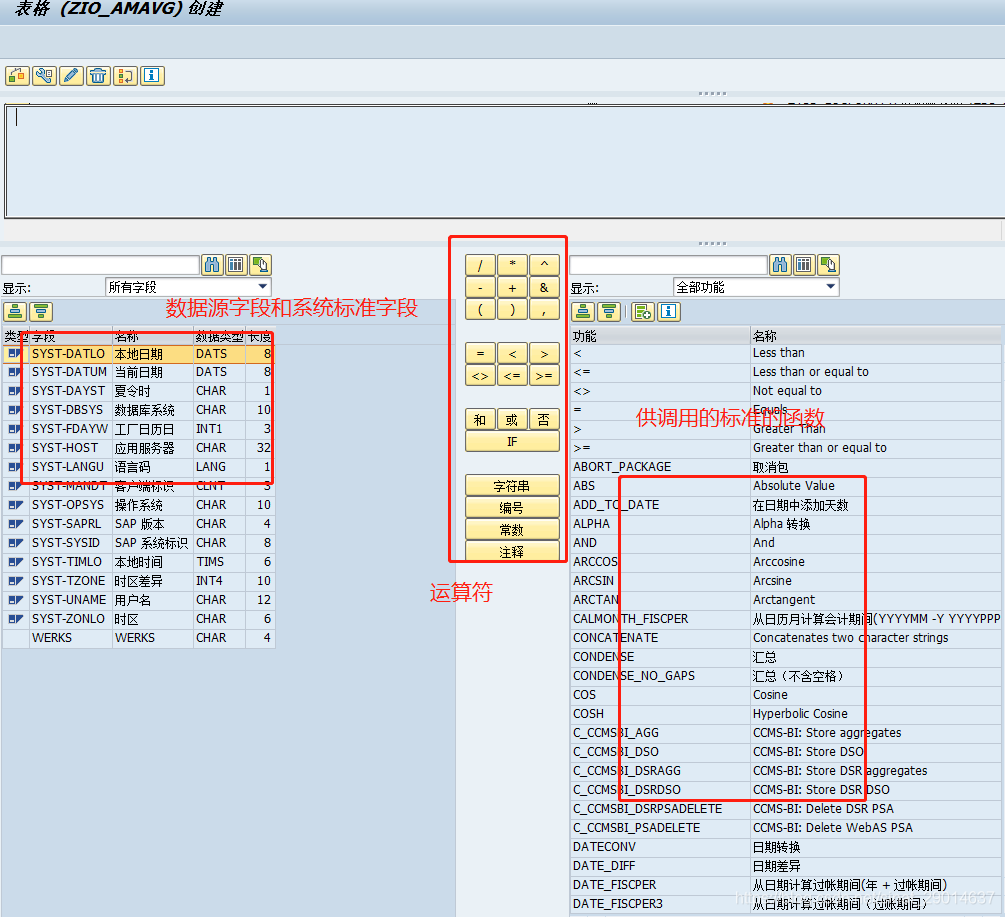
例程-单个字段的例程,直接用abap写关联关系
2.聚合
**汇总-**执行汇总,累加,例如多张凭证对应一张销售订单,凭证金额需要汇总
覆盖-覆盖存在的数据,例如多张凭证对应一张销售订单,销售订单金额则需要用覆盖避免重复汇总;或者同一个DSO不同转换取不同的数据源,不需要重复的可以选择覆盖
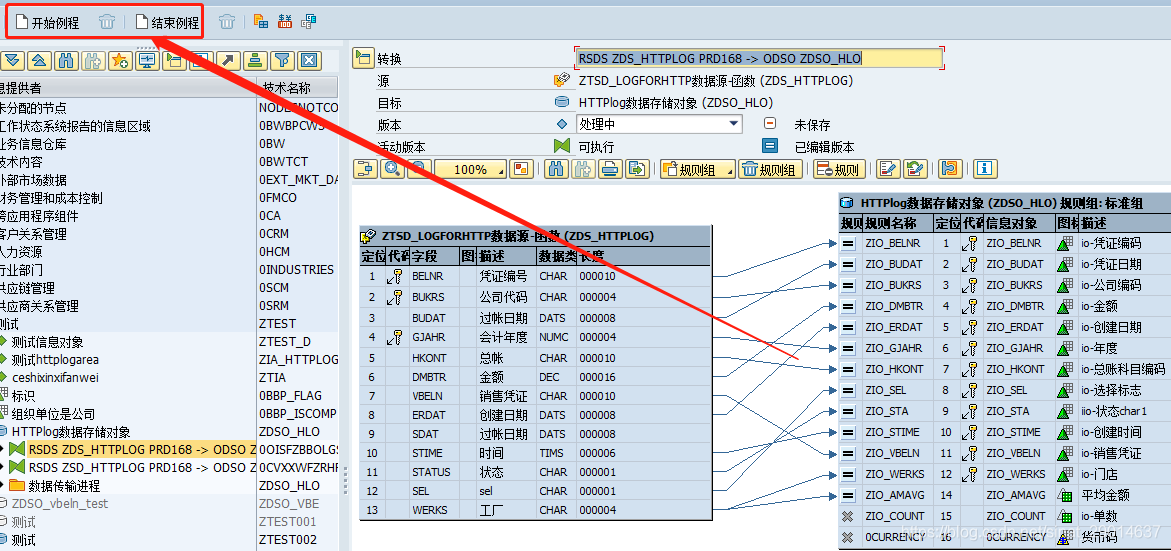
三、DSO转换的例程
一般都是分为开始例程和结束例程,此外还有反转例程、关键字段或者特殊例程(二.1中的例程)
(一)例程的代码结构
所有例程代码结构如下(都类似):
PROGRAM trans_routine .
Class lcl_transform definition.
Public section. “1.可以自定义系统全局变量
DATA: p_check_master_data_exist TYPE RSODSOCHECKONLY READ-ONLY,
*- Instance for getting request runtime attributs;
* Available information: Refer to methods of
* interface 'if_rsbk_request_admintab_view'
p_r_request TYPE REF TO if_rsbk_request_admintab_view READ-ONLY.
Private section. “2.可以自定义类变量
Type-pools:rsd ,rstr .
Types: begin of _ty_s_sc_l,
….转换的所有字段
TYPES: _ty_t_SC_1 TYPE STANDARD TABLE OF _ty_s_SC_1
WITH NON-UNIQUE DEFAULT KEY.
*$*$ begin of global - insert your declaration only below this line *-*
... "insert your code here “3.定义自定义类全局变量
*$*$ end of global - insert your declaration only before this line *-*
METHODS start_routine “4.开始转换,即开始例程
IMPORTING
request type rsrequest
datapackid type rsdatapid
segid type rsbk_segid
EXPORTING
monitor type rstr_ty_t_monitors
CHANGING
SOURCE_PACKAGE type _ty_t_SC_1
RAISING
cx_rsrout_abort
cx_rsbk_errorcount.
METHODS inverse_start_routine “5.反转转换 反转例程
IMPORTING
i_th_fields_outbound TYPE rstran_t_field_inv
I_R_SELSET_OUTBOUND TYPE REF TO CL_RSMDS_SET
i_is_main_selection TYPE rs_bool
i_r_selset_outbound_complete TYPE REF TO cl_rsmds_set
i_r_universe_inbound TYPE REF TO CL_RSMDS_UNIVERSE
CHANGING
c_th_fields_inbound TYPE rstran_t_field_inv
c_r_selset_inbound TYPE REF TO CL_RSMDS_SET
c_exact TYPE rs_bool.
ENDCLASS. "routine DEFINITION
*$*$ begin of 2nd part global - insert your code only below this line *
... "insert your code here “6.可以定义类等
*$*$ end of 2nd part global - insert your code only before this line *
“class实现
CLASS lcl_transform IMPLEMENTATION.
METHOD start_routine.
*=== Segments ===
FIELD-SYMBOLS:
<SOURCE_FIELDS> TYPE _ty_s_SC_1.
DATA:
MONITOR_REC TYPE rstmonitor.
*$*$ begin of routine - insert your code only below this line *-*7.可以写入自定义的代码,SOURCE_PACKAGE表示原数据,最终都是修改原数据以达到效果
*-- fill table "MONITOR" with values of structure "MONITOR_REC" “参数构造
*- to make monitor entries
... "to cancel the update process
* raise exception type CX_RSROUT_ABORT. “错误范例
delete SOURCE_PACKAGE where FISCPER+5(2) >= '13'. “自定义代码,期间大于13不取
*$*$ end of routine - insert your code only before this line *-*
ENDMETHOD. "start_routine
METHOD inverse_start_routine.
* IMPORTING
* i_r_selset_outbound TYPE REF TO cl_rsmds_set
* i_th_fields_outbound TYPE HASHED TABLE
* i_r_selset_outbound_complete TYPE REF TO cl_rsmds_set
* i_r_universe_inbound TYPE REF TO cl_rsmds_universe
* CHANGING
* c_r_selset_inbound TYPE REF TO cl_rsmds_set
* c_th_fields_inbound TYPE HASHED TABLE
* c_exact TYPE rs_bool
*$*$ begin of inverse routine - insert your code only below this line*-*
... "insert your code here
*$*$ end of inverse routine - insert your code only before this line *-*
ENDMETHOD.
ENDCLASS .
(二)例程分类
(所有例程都可以请见(一)的代码,特别是1-3都是在转换的开始例程、结束例程按钮生成)
1.开始例程:
主要标志:METHODS start_routine “开始转换,开始例程
转换开始的时候执行,即提取上来的数据处理,方便转换时候使用,一般是校验、转换不了的特殊数值处理。
2.反向例程:
标志是METHOD inverse_end_routine.
它将目标对象在运行报表时的选择条件和输出字段转化为对源对象的选择条件和输出字段的要求
反向例程只在两种情况下使用。
-
如果为虚拟信息提供者定义了例程,出于性能方面的考虑,可以使用反向例程。由于虚拟信息提供者本身并不存储数据,只在运行报表时直接到源系统读取数据,转换中的例程可能使报表的选择条件与输出字段与源系统不存在直接的对应关系,因此有必要把这些信息通过反向例程传给源对象。
-
当使用SAPBI 的报表跳转功能,从SAPBI 系统跳转到其他SAP 系统的事务处理界面时,如果数据是经过例程转换的,需要使用反向例程将报表中相应的信息返回给其他的SAP 系统。
3.结束例程:
标志是METHODS new_record__end_routine “结束例程新纪录触发,即转换完了后执行该代码再放到PSA(数据持久存储区),可以执行文本取数逻辑、基础资料数据填补等
4.关键字段例程(三.1中具体字段的例程,略)
四、数据传输进程DTP
主要用于bw数据加载转换激活后会出现空的DTP文件,要保证每个转换对应一个DTP
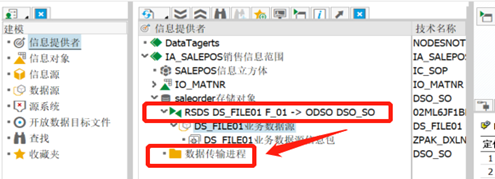
右击创建数据传输进程:
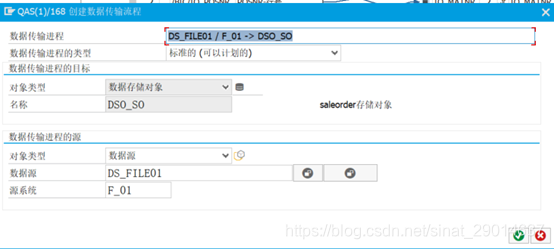
注意:激活出现@5D\Q警告@ Settings for error handling and error DTP do not match @35\Q存在长文本@
处理办法:点击更新tab,点击新建错误处理传输DTP,新建和激活了错误TDP后就可以
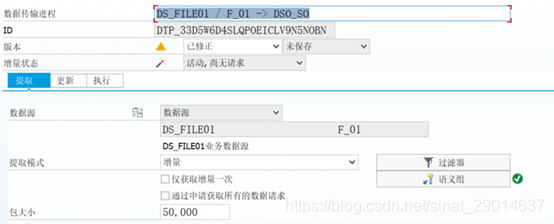
提取tab:
提取模式:全量、增量 ,配合过滤器使用(输入条件)
仅获取增量一次:初始化一次,后面全量
通过申请获取所有的数据请求:增量请款下,可申请获取全量数据,配合直到没有更多数据时候恢复(具体怎么用待了解)
包大小:每次获取数据包大小
更新tab(更新、错误处理):
执行tab:
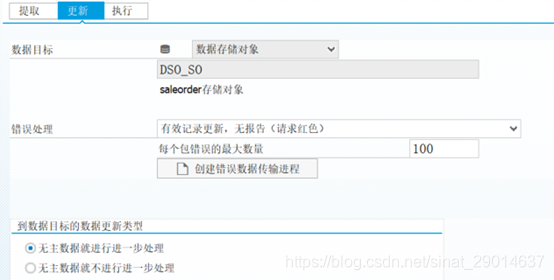
技术申请状态:可设置警告是否为红色
请求总体状态:自动/手工,主要是自动
处理模式:连续提取立即平行处理(获取选择调试的)
执行:点击后执行抽取过程,处理模式为调试,则变成模拟
程序流:显示处理数据流,在选择处理模式为调试,才能设置更改断点
上图可以看出,点击执行时候,从FS_FILE01业务数据源,通过过滤器在后台取数,然后通过转换变成DSO_SO销售订单储存对象,(存放)更新DSO中(绑定的io已生成相关表,存放在IO的表)
调试过程:METHOD if_rsbk_cmd_x~get_datapackage .
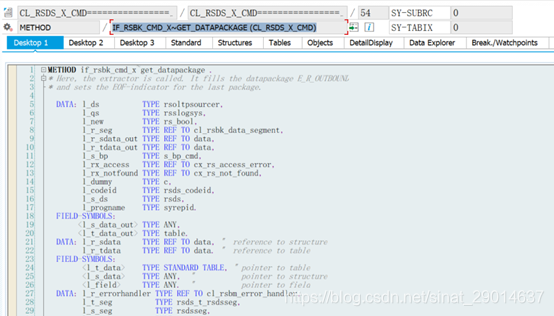
五、PSA和数据抽取流程
PSA Persistent Staging Area 持久数据缓存区
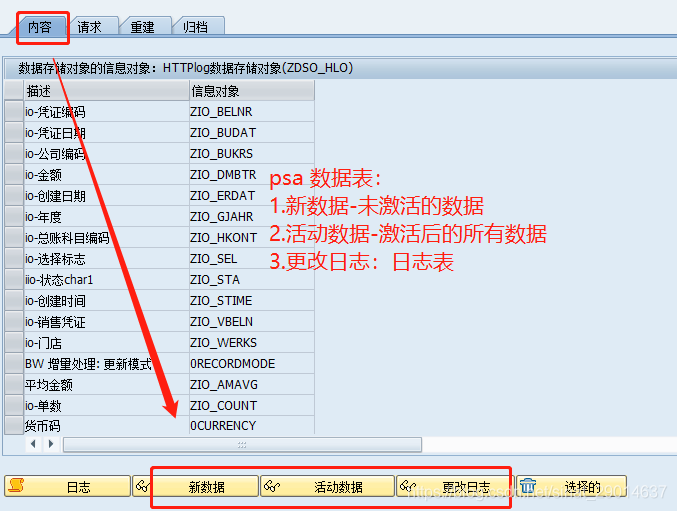
项目中用到的主要包括数据抽取时候进入的新数据表(未激活),数据激活后变成活动数据表(激活)以及数据日志表。
手工抽取数据(未建立处理链),一般都是需要全量抽取一次,后面增量抽取,流程如下:
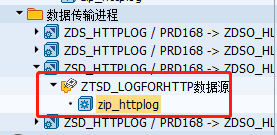
1.全量抽取
(1)激活信息包(全量的每一次都需要,增量的激活一次即可)
计划表tab-开始:
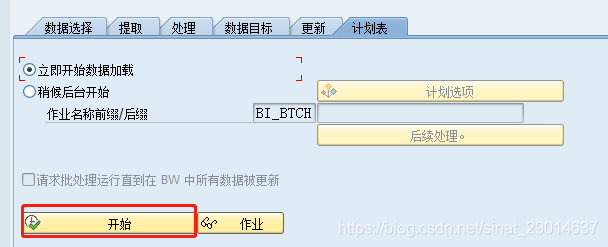
(2)执行DTP的数据
双击全量抽取的DTP
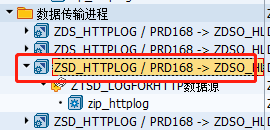
点击执行:
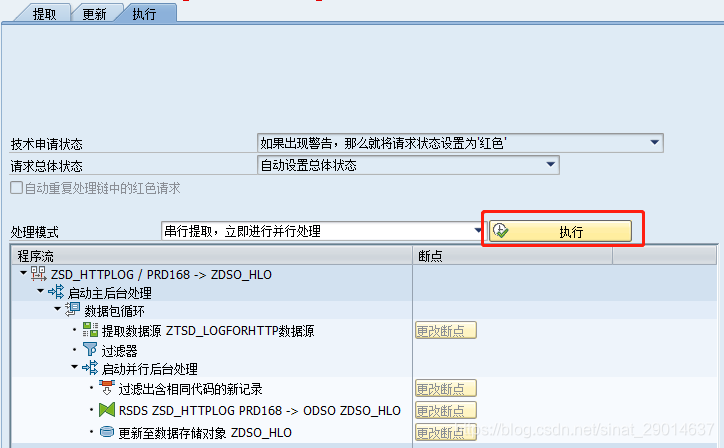
(3)查看和激活数据
在DSO中右击-管理,点击“内容”tab检查数据(非必要)
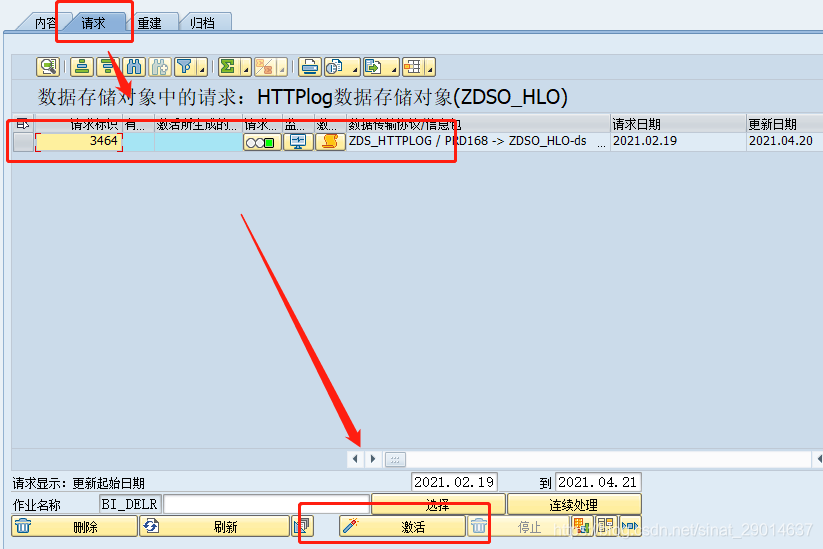
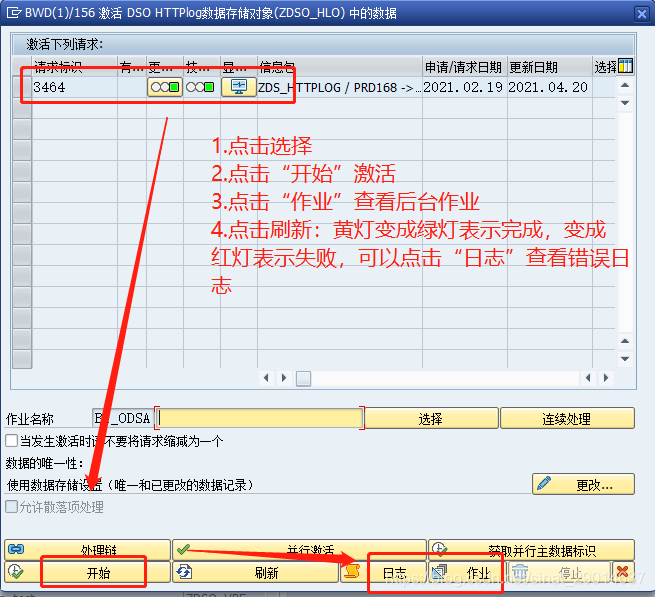
点击“请求”tab,点击“激活”按钮
2.增量抽取
增量抽取过程类似全量,一般都是初始化执行全量后,配置处理链执行(或者手工执行),根据增量标识(字段)抽取新的数据,这里不重复说明
六、总结
至此,项目抱佛脚的BW开发知识基本讲完,相信熟悉后是可以开展初步的建模开发和手工抽取数据的了。后续补发些开发后的传输、处理链开发和数据删除重抽等运维知识


















 8215
8215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











